







本文档介绍常见的 ARM 架构,包括 Cortex-A5,Cortex-A7, Cortex-A8, Cortex-A9, Cortex-A15.
常见的术语
-
DFT(Design for Test), 为了增强芯片可测性而采用的一种设计方法
-
APB(Advanced Peripheral Bus), 是一种低速外设总线接口,通常用于将外部设备(如I/O端口、定时器、UART等)连接到嵌入式系统的微控制器或微处理器中
-
ATB(Advanced Trace Bus)接口是一种用于高级跟踪和调试功能的总线接口,通常用于嵌入式系统中的调试和性能分析。
-
AXI(Advanced eXtensible Interface)接口是一种高性能、低功耗的总线接口,通常用于连接各种外设和内核到片上系统(SoC)中的中央处理器(CPU)或其他主控制器。AXI接口是ARM公司推出的一种总线标准,用于在SoC中实现高性能和低功耗的数据传输。
-
BIU(Bus Interface Unit)是计算机中的一个关键组件,用于连接 CPU(中央处理器)与系统总线,负责协调和管理 CPU 对内存和外部设备的访问。BIU 可以将 CPU 发出的内存地址转换为物理地址,并处理与内存或外设的数据传输。BIU 还可能包括高速缓存控制逻辑以提高数据访问效率。
-
Fill and eviction queue
- Fill Queue(填充队列)是一个用于处理从主存(或更低级别的缓存)中加载数据到高速缓存的队列
- Eviction Queue(淘汰队列)是一个用于处理高速缓存中的数据替换操作的队列。
-
Arbitration(仲裁), 用于解决多个设备或资源竞争访问的问题。在共享资源或总线上,多个设备可能同时请求访问资源,因此需要一种机制来决定哪个设备应该获得访问权限。仲裁的目标是公平地分配资源的访问权,并确保资源的正确和高效使用。
- Processor arbitration(处理器仲裁)它涉及到多个处理器(或 CPU 核心)之间的竞争和决定哪个处理器可以访问共享资源或执行特定任务的过程。
-
Decode & sequencer
-
Decode
在解码阶段,计算机处理器会将取指令阶段获取的指令进行解析,确定指令的操作类型、操作数、目标寄存器等信息。
解码阶段的主要任务是识别和解释指令的操作码,以便后续的执行阶段可以正确地执行指令。
解码还可以包括检查指令的合法性、检查操作数的可用性以及生成执行指令所需的控制信号。
-
sequencer
顺序控制器,也称为指令控制器或微程序控制器,是处理器中的一个关键组件,负责协调和控制指令的执行顺序。
顺序控制器通常包括一个状态机或类似的机制,它根据当前的处理状态和指令解码的结果来选择下一个要执行的指令。
顺序控制器还负责生成各种控制信号,以确保指令的正确执行,包括操作数的读取、ALU(算术逻辑单元)的操作、寄存器的写入等。
顺序控制器还可以实现分支操作、跳转操作和异常处理,以处理不同的控制流程。
-
-
Dependency Check 在多条指令依次执行的流水线处理器中,每条指令可能依赖于之前的指令的结果。这种依赖关系通常分为两种类型:数据依赖和控制依赖。
-
issue 指令发射
-
RegBank (Register Bank)寄存器组
-
Flags 标志位
-
零标志位(Zero Flag):通常用于指示计算结果是否为零。如果计算结果为零,零标志位将被设置为 1,否则设置为 0。
-
符号标志位(Sign Flag):表示计算结果的符号,通常是结果的最高位(最左侧位)。如果结果为正,则符号标志位为 0,如果结果为负,则符号标志位为 1。
-
溢出标志位(Overflow Flag):用于检测算术运算是否导致了溢出,即结果是否超出了有限位数的表示范围。如果发生溢出,溢出标志位将被设置为 1。
-
进位标志位(Carry Flag):通常在无符号整数运算中使用,用于表示是否发生了进位。如果某个算术操作导致了进位,进位标志位将被设置为 1。
-
借位标志位(Borrow Flag):类似于进位标志位,但通常在有符号整数运算中使用,用于表示是否发生了借位。如果某个算术操作导致了借位,借位标志位将被设置为 1。
-
其他标志位(Flag Bit):可以根据特定的处理器架构和指令集定义,用于表示不同的状态和条件。
-
-
Parity and ECC RAM
奇偶校验RAM(Parity RAM)和纠错码RAM(ECC RAM)是计算机系统中的两种内存模块,用于帮助检测和有时纠正存储在内存中的数据错误。它们旨在提高数据的可靠性和完整性,特别是在关键任务和高可用性计算环境中使用。
- 奇偶校验RAM在每个字节的数据存储中包括一个额外的位(奇偶校验位),奇偶校验位用于简单的错误检测。它被设置为0或1,以使每个字节中1的总数(包括奇偶校验位)始终为偶数(偶校验)或奇数(奇校验)。奇偶校验RAM的价格比ECC RAM低,通常用于不那么关键的计算环境。
- 纠错码RAM(ECC RAM)不仅提供了奇偶校验RAM的功能,还提供了错误检测和纠正。ECC RAM使用更多位来进行错误校正,通常是每64位数据额外的8位(8/64 ECC)。ECC RAM比奇偶校验RAM更昂贵,通常用于服务器、工作站和其他需要数据完整性的系统中。
-
L2 cache tag RAM
L2缓存通常由两个主要组件组成:标签RAM和数据RAM, L2缓存标签RAM的主要作用是跟踪缓存中存储的数据块或行的状态和位置。每当CPU请求访问内存中的数据时,处理器会首先检查L2缓存,以查看所需的数据是否已经存在于缓存中。
-
L1、L2 cache control 缓存流水线控制是计算机体系结构中与缓存操作相关的一组控制机制和策略。它们用于确保缓存的高效操作,以提供快速的数据存取,同时最大程度地减少延迟和冲突。
-
PTM(Processor Trace Macrocell):这是一种ARM处理器中的调试工具,用于跟踪处理器的执行流程。PTM可用于分析和调试应用程序的执行,以便发现和解决问题。
-
Ind Pred(Indirect Prediction),间接预测,是与分支预测相关的概念,用于确定程序中条件分支的执行路径。
-
ITLB(Instruction Translation Lookaside Buffer), 主要功能是缓存将虚拟内存地址(由程序使用)转换为物理内存地址(由硬件使用)的映射。
-
LTLB(Large Translation Lookaside Buffer), 大型TLB,用于管理虚拟内存地址到物理内存地址的映射。
-
STLB(Second-Level Translation Lookaside Buffer), 二级TLB,用于管理虚拟内存地址到物理内存地址的映射。
-
CP14 是 ARM 处理器的调试协处理器。它包括一组调试和性能监测寄存器,用于支持调试器和性能分析工具的功能。CP14 寄存器通常包括控制调试模式、观察点和断点、性能计数器等功能。
-
CP15 是 ARM 处理器的系统控制协处理器。它包括一组系统控制和配置寄存器,用于管理处理器的各种系统级功能和配置选项。CP15 寄存器允许操作系统内核和处理器配置管理器来控制内存管理、缓存、异常处理、访问权限等系统级别的特性。
-
PMU(Performance Monitoring Unit)性能监测单元,PMU 是计算机处理器中的一个硬件模块,用于监测和记录处理器的性能指标和事件,以便进行性能分析、调试和优化。
Cortex-A5
Cortex-A5处理器支持所有ARMv7-A体系结构特性,包括TrustZone安全扩展和NEON媒体处理引擎。它具有极高的面积和功耗效率,但最大性能低于其他Cortex-A系列处理器。Cortex-A5处理器提供单核和多核版本。
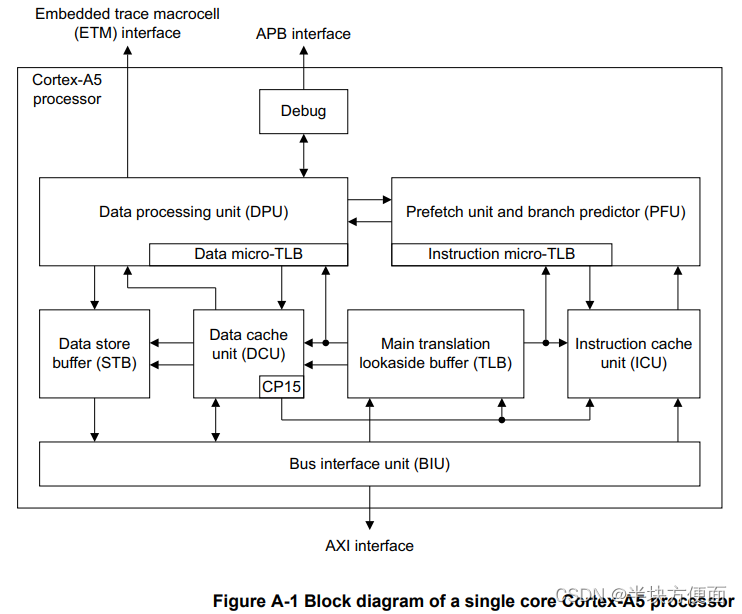
图A-1中显示的Cortex-A5处理器具有单发射、8级(流水线共分为8个步骤)流水线。在某些情况下,它可以同时执行分支指令,并包含复杂的分支预测逻辑,以减少与流水线重新加载相关的性能损失。NEON和浮点硬件支持都是可选的。Cortex-A5处理器的VFP实现了VFPv4,它在VFPv3的基础上增加了半精度扩展和融合乘积累加指令的功能。它支持ARM和Thumb指令集。一级指令缓存和数据缓存的大小是可配置的(由硬件实现者),范围从4KB到64KB不等。
Cortex-A5 NEON单元的特点:
- SIMD和标量单精度浮点计算
- 标量双精度浮点计算
- SIMD和标量半精度浮点转换
- SIMD 8位、16位、32位和64位有符号和无符号整数计算
- 单位系数的8位或16位多项式计算
- 结构化数据加载能力
- 一个大的共享寄存器文件,可寻址为
- 32个32位S(单)寄存器
- 32个64位D(双)寄存器
- 16个128位Q(四元)寄存器
- 操作
- 加减
- 累加乘
- 最大或最小值驱动的通道选择操作
- 倒数平方根
- 全面的数据结构加载指令,包括寄存器库中的表查找
Cortex-A7
Cortex-A7 MPCore处理器是一款高性能、低功耗的处理器,由ARM于2011年10月宣布推出。它采用顺序执行流水线,并具有直接和间接分支预测功能,还对浮点和NEON代码性能进行了多项改进。它与本书中描述的其他处理器具有应用兼容性。该处理器与其他Cortex-A系列处理器完全兼容,并集成了高性能Cortex-A15处理器的所有功能,包括虚拟化、大物理地址扩展(LPAE)、NEON高级SIMD和AMBA 4 ACE一致性。
AMBA 4 ACE 是一种高级扩展,用于 AMBA(Advanced Microcontroller Bus Architecture)总线协议,该协议由ARM开发,用于在SoC中连接处理器、内存、外设和其他硬件组件。ACE 一致性添加了高级缓存一致性管理机制,以确保多个处理器核心的缓存与主存之间的数据一致性,以及在共享内存系统中正确处理访问冲突。
Cortex-A7 Neon单元的特点:
- SIMD和标量单精度浮点计算
- 标量双精度浮点计算
- SIMD和标量半精度浮点转换
- SIMD 8位、16位、32位和64位有符号和无符号整数计算
- 单位系数的8位或16位多项式计算
- 结构化数据加载能力
- 一个大的共享寄存器文件,可寻址为
- 32个32位S(单)寄存器
- 32个64位D(双)寄存器
- 16个128位Q(四元)寄存器
- 操作
- 加减
- 累加乘
- 最大或最小值驱动的通道选择操作
- 倒数平方根
- 全面的数据结构加载指令,包括寄存器库中的表查找
Cortex-A8
Cortex-A8处理器是首个实现ARMv7-A架构配置文件的处理器。它可用于许多不同的设备,包括三星的S5PC100、德州仪器的OMAP3530和Freescale的i.MX515。这些设备具有各种性能水平,一些设备的时钟速度超过1GHz。
与以前的ARM处理器相比,Cortex-A8处理器具有更复杂的微体系结构。其整数处理器具有双对称、13级(共13步)流水线,支持按顺序发出指令。NEON流水线具有额外的10级流水线,支持整数和浮点64位或128位的SIMD。它支持VFPv3浮点运算,以及Jazelle-RCT。
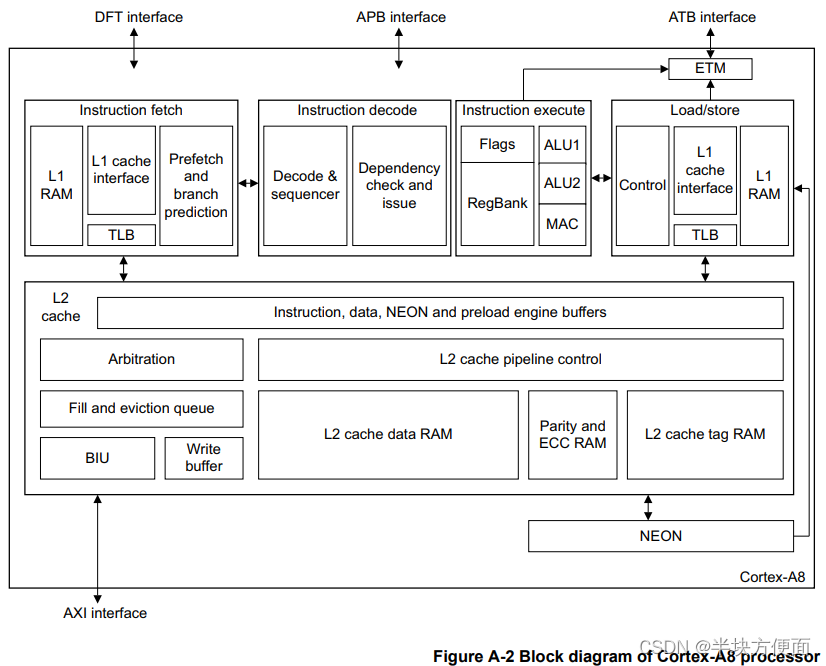
L1 缓存(指令或数据)的大小为16KB或32KB。L2缓存共 1MB,每缓存行共16字。L1 和 L2 缓存都具有128位宽的数据接口,供处理器使用。NEON单元使用的数据默认情况下不会分配到一级缓存(尽管NEON单元可以读取和写入已经位于一级数据缓存中的数据)。
NEON单元的工作方式类似于一条流水线,处理器在其中执行指令。这个流水线从整数处理的最后一步开始,这意味着指令中没有异常和分支(Arm流水线以及处理完毕)。
NEON单元能够非常迅速地访问一级缓存中的数据,而不需要额外的等待时间。当处理器执行NEON指令时,它会提前生成需要访问的数据的地址,这样数据可以在NEON操作需要它之前就被提前加载到一级缓存中。这有助于提高数据访问的速度。
NEON单元、整数处理单元和内存系统之间有一个复杂的数据传输系统,允许数据顺畅地传输,而不需要等待。这样可以减少数据访问的延迟时间,使计算更加高效。
Neon 单元包括:
-
128 位宽的加载和存储通过至 L1、 L2缓存,支持流式传输
-
三个 SIMD 整数流水线
- 累加乘
- 偏移
- ALU
-
加载存储/排列
- 加载存储 Neon 数据
- 在整数单元中传送数据
- 数据排列:交错、解交错
-
两个 SIMD 单精度浮点管道
- 乘法
- 加法
-
一个独立的非流水线化的矢量浮点单元(VFPLite)实现了ARM VFPv3浮点规范,旨在提供中等性能的IEEE 754兼容浮点支持。
ARM指令执行单元每个时钟周期最多可以向NEON单元发出两条有效指令,但Cortex-A8 NEON单元不会并行发出两条数据处理指令。这是为了避免复制数据处理功能块所带来的面积开销,以及避免与读写寄存器端口复用相关的时序关键路径和复杂性开销。
Cortex-A8处理器以 64位宽 访问 L1缓存,Neon使用 128位宽 访问 L1 和 L2 缓存。尽量避免ARM和NEON访问同一缓存行;或者使用NEON代码进行内存拷贝,避免L1缓存污染。
Cortex-A8处理器可以发射两个Neon指令,在以下情况中:
- 没有寄存器和数据依赖
- 一条指令是数据处理、另一条是:
- 加载或存储指令
VLD1.8 {D0}, [R1]! VMLAL.S8 Q2, D3, D2 - ARM-NEON数据传输
VEXT.8 D0, D1, D2, #1 VSUB.16 D3, D4, D5 - 排列指令
- 加载或存储指令
PS:
- 从ARM寄存器到NEON寄存器的数据传输很快,但是使用MRC(数据移动指令)从NEON流水线移动数据到ARM需要20个时钟周期。
- 如果NEON和ARM单元都对位于同一缓存行内的地址执行加载或存储指令,需要延迟约20个周期来解决排序问题。
- 通过谨慎的编码,可以避免这些延迟。首先,我们必须尽量减少ARM内存访问和NEON内存访问的组合,以避免它们访问同一内存区域
- 如果不需要立即使用结果,可以将NEON结果存储到内存中,然后从内存加载结果到ARM通用寄存器。
- 在尝试加载之前,ARM可以在做一些其他工作来隐藏20个周期的延迟。
- 大多数编译器使用softfp调用约定来在ARM通用寄存器中传递参数和返回值。因此,要返回一个浮点值,需要将一个值从NEON寄存器传递到ARM通用寄存器,这会导致20个周期的延迟。避免这个问题的一种方法是尝试内联这样的函数或使用硬浮点链接。
- 尽管浮点单元有自己的逻辑来评估比较并设置标志,但这个寄存器的内容必须传输到ARM以进行条件分支,这会导致延迟。
Cortex-A9
Cortex-A9 MPCore处理器和Cortex-A9单核处理器性能更高,时钟速度超过1GHz,性能达到2.5DMIPS/MHz,明显高于Cortex-A5或Cortex-A8处理器。它支持ARM、Thumb、Thumb-2、TrustZone、Jazelle-RCT和DBX等技术。
L1 缓存系统为多核软件提供硬件支持的缓存一致性,可以连接1到4个处理器。处理器外部可以选择连接一个L2缓存。ARM提供了一个L2缓存控制器(PL310/L2C-310),支持最大8MB大小的缓存。
该处理器还包含一个集成的中断控制器,实现了ARM通用中断控制器(GIC)架构规范。这可以配置为支持高达224个中断源。
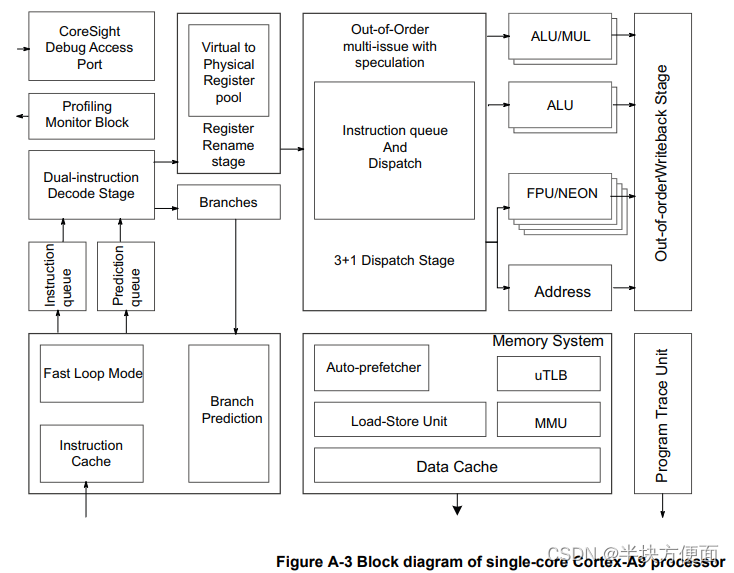
Cortex-A9 Neon单元特点:
-
SIMD和标量单精度浮点计算
-
标量双精度浮点计算
-
SIMD和标量半精度浮点转换
-
SIMD 8位、16位、32位和64位有符号和无符号整数计算
-
单位系数的8位或16位多项式计算
-
结构化数据加载能力
-
Cortex-A9处理器可以同时执行两条ARM或Thumb指令。
-
VFPv3和高级SIMD指令拥有独立的流水线。
-
一个大的共享寄存器文件,可寻址为
- 32个32位S(单)寄存器
- 32个64位D(双)寄存器
- 16个128位Q(四元)寄存器
-
高性能SIMD矢量操作,支持以下类型:
- 无符号、有符号整数
- 二进制系数多项式
- 单精度浮点数
-
半精度浮点值转换
-
附加的VFP和高级SIMD指令,这些指令允许将单个值和值向量与单精度浮点表示之间进行转换。然后可以使用VFP和高级SIMD指令来处理这些值。
-
独立的高级SIMD和VFP禁用,独立的高级SIMD禁用允许Cortex-A9实现在只有VFP扩展存在时表现得像只有VFP扩展。这使您可以在包含Cortex-A9 NEON单元和仅浮点单元的Cortex-A9多核集群之间启用最佳操作系统任务调度。
-
动态可配置的NEON寄存器文件大小,动态可配置的NEON寄存器文件大小为VFPv3-D16和VFPv3-D32混合多处理器集群提供了额外的支持。Cortex-A9 NEON单元实现了32个64位双精度寄存器。而仅支持VFP的实现只需要支持16个双精度寄存器。这个寄存器文件禁用控制允许模拟一个16个条目的双精度寄存器文件,提供了增强的兼容性和更灵活的任务调度。
Cortex-A15
Cortex-A15 MPCore处理器具有非常高的性能和改进的浮点性能。它与本文中描述的其他ARM处理器兼容。
Cortex-A15 MPCore处理器引入了新的功能,包括支持完全硬件虚拟化和大物理地址扩展(LPAE),这使得可以寻址高达1TB的内存。
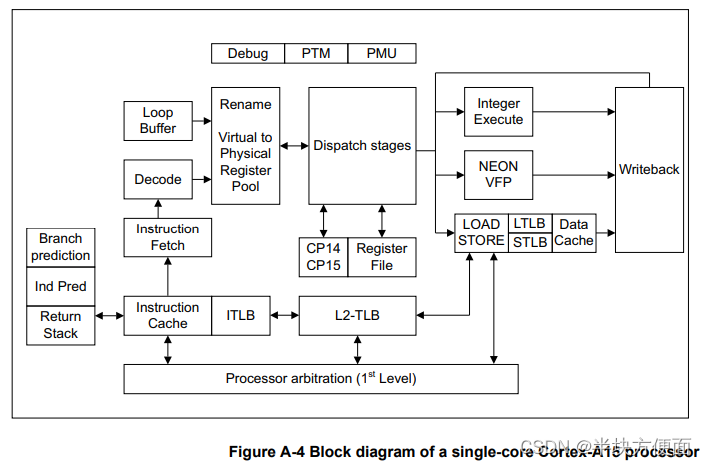
Cortex-A15 MPCore 处理器的特点:
- 乱序(out-of-order,涉及性能优化)、超标量(Superscalar,同时执行多个指令)流水线
- 32KB L1 指令缓存和32KB L1 数据缓存。
- 紧密耦合的低延迟 L2 缓存
- 改进的浮点和 NEON 代码性能
- 全硬件虚拟化
- 大型物理地址扩展(LPAE),支持高达1TB的内存地址
- 具备纠错能力,用于容错和软错误恢复
- 单核簇内包含1-4个处理器核心,且为SMP(对称多处理器核心)结构
- 通过 AMBA4 技术实现多个一致性多核核心簇(clusters)之间的连接和协同工作。
- AMBA4 高速缓存一致互连(Cache Coherent Interconnect,CCI),允许多个 Cortex-A15 MPCore 处理器之间实现完全的高速缓存一致性。
Cortex-A15在制造时可以配置不同级别的SIMD和VFP:
- Cortex-A15 支持高级 SIMDv2 指令集中的所有寻址模式、数据类型和操作。
- 该处理器支持 VFPv4 扩展的所有寻址模式、数据类型和操作,同时采用了 Common VFP 子架构的版本3。 该处理器实现了 VFPv4-D32。
在 Cortex-A15 的 VFP 实现中:
- 所有标量操作都完全在硬件中实现,支持所有的舍入模式、向零截断和默认 NaN 模式的组合。
- Cortex-A15 的 VFP 实现不生成异步 VFP 异常。
- 如果应用程序需要 VFP 矢量操作,则必须使用 VFP 支持代码。
PS:
- 从复位状态开始,高级 SIMD 和 VFP 扩展都被禁用
- 任何尝试执行高级 SIMD 或 VFP 指令的操作都会触发一个未定义指令异常。
- 协处理器寄存器 CP10 和 CP11 控制软件对高级 SIMD 和 VFP 功能的访问。
- 高级 SIMD 和 VFP 可以配置为仅在安全状态下可用。

















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









