







 本文详细探讨了Linux内核中的进程复制,重点分析了fork和exec族系统调用的实现,包括写时复制技术、kernel_clone函数、copy_process过程以及内核线程和启动新程序的细节。通过对内核源码的解析,阐述了系统调用的执行流程和进程间的资源管理策略。
本文详细探讨了Linux内核中的进程复制,重点分析了fork和exec族系统调用的实现,包括写时复制技术、kernel_clone函数、copy_process过程以及内核线程和启动新程序的细节。通过对内核源码的解析,阐述了系统调用的执行流程和进程间的资源管理策略。
目录
环境:
Kernel Version:Linux-5.10
ARCH:ARM64
一:前言
上一节我们提到了进程的产生方式fork,exec与clone,本节将详细分析fork和exec族系统调用的具体实现。通常这些调用不是由应用程序直接发出的,而是通过一个中间层调用,即负责与内核通信的C标准库。从用户状态切换到内核态的方法在文件kernel/linux-5.10/include/uapi/asm-generic/unistd.h,kernel/linux-5.10/arch/arm64/include/asm/unistd32.h中做了定义,负责与系统调用相关两条内容:
- 定义了预处理常数,将所有系统调用的描述符关联到符号常数,诸如__NR_chdir,__NR_fchmod等。
- 定义了内核内部调用系统调用所有的函数。
#ifndef __SYSCALL
#define __SYSCALL(x, y)
#endif
... ...
#define __NR_fallocate 47
__SC_COMP(__NR_fallocate, sys_fallocate, compat_sys_fallocate)
#define __NR_faccessat 48
__SYSCALL(__NR_faccessat, sys_faccessat)
#define __NR_chdir 49
__SYSCALL(__NR_chdir, sys_chdir)
#define __NR_fchdir 50
__SYSCALL(__NR_fchdir, sys_fchdir)
#define __NR_chroot 51
__SYSCALL(__NR_chroot, sys_chroot)
#define __NR_fchmod 52
__SYSCALL(__NR_fchmod, sys_fchmod)
#define __NR_fchmodat 53
__SYSCALL(__NR_fchmodat, sys_fchmodat)
#define __NR_fchownat 54
__SYSCALL(__NR_fchownat, sys_fchownat)
#define __NR_fchown 55
__SYSCALL(__NR_fchown, sys_fchown)
... ...二:进程复制
Linux提供了3个复制进程的系统调用:
- fork建立了父进程的一个完整副本,然后作为子进程执行,为减少与该调用相关的工作量,Linux使用了写时复制(copy-on-write)技术。
- vfork类似于fork,但并不创建父进程数据的副本。父子进程之间共享数据。vfork设计用于子进程形成后立即执行execve系统调用加载新程序的情形。在子进程退出或开始新程序之前,内核保证父进程处于堵塞状态。(由于fork的写时复制技术,vfork速度优势不在,尽量避免使用)
- clone产生线程,可以对父子进程之间的共享,复制进行精准控制。
1、写时复制
内核使用写时复制技术,以防止在fork执行时将父进程的所有数据复制到子进程,从而规避掉复制操作耗时长以及fork系统调用后又调用exec从而导致之前的复制多余,因为复制的数据不再需要。
内核可以使用技巧规避该问题,并不复制进程的整个地址空间,而只是复制其页表。这样就建立了虚拟地址空间跟物理内存页之前的联系,fork之后父子进程的地址空间均指向同样的物理内存页并且不能修改批次的页,如果有一方要向内存页写入则会发生COW缺页异常。
2、系统调用
fork,vfork,clone系统调用的入口点在kernel中的实现方式:
#kernel/linux-5.10/kernel/fork.c
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
}
#endif
#ifdef __ARCH_WANT_SYS_CLONE
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
unsigned long, tls,
int __user *, child_tidptr)
{
struct kernel_clone_args args = {
.flags = (lower_32_bits(clone_flags) & ~CSIGNAL),
.pidfd = parent_tidptr,
.child_tid = child_tidptr,
.parent_tid = parent_tidptr,
.exit_signal = (lower_32_bits(clone_flags) & CSIGNAL),
.stack = newsp,
.tls = tls,
};
return kernel_clone(&args);
}
#endif系统调用宏展开即可得到__arm64_sys_fork,__arm64_sys_clone,具体实现如下:
#kernel/linux-5.10/arch/arm64/include/asm/syscall_wrapper.h
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long __arm64_sys##name(const struct pt_regs *regs); \
ALLOW_ERROR_INJECTION(__arm64_sys##name, ERRNO); \
static long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \
asmlinkage long __arm64_sys##name(const struct pt_regs *regs) \
{ \
return __se_sys##name(SC_ARM64_REGS_TO_ARGS(x,__VA_ARGS__)); \
} \
static long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = __do_sys##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__))
#define SYSCALL_DEFINE0(sname) \
SYSCALL_METADATA(_##sname, 0); \
asmlinkage long __arm64_sys_##sname(const struct pt_regs *__unused); \
ALLOW_ERROR_INJECTION(__arm64_sys_##sname, ERRNO); \
asmlinkage long __arm64_sys_##sname(const struct pt_regs *__unused)
#kernel/linux-5.10/include/linux/syscalls.h
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE_MAXARGS 6
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)大致调用流程可分为如下两种:
/* * EL0 mode handlers. */ .align 6 SYM_CODE_START_LOCAL_NOALIGN(el0_sync) kernel_entry 0 mov x0, sp bl el0_sync_handler b ret_to_user SYM_CODE_END(el0_sync)1、el0_sync_handler -> el0_svc -> el0_svc -> do_el0_svc -> el0_svc_common -> __arm64_sys_clone -> kernel_clone
2、kthreadd -> create_kthread -> kernel_thread -> kernel_clone
3、kernel_clone实现
The old _do_fork() helper doesn't follow naming conventions of in-kernel
helpers for syscalls. The process creation cleanup in [1] didn't change the
name to something more reasonable mainly because _do_fork() was used in quite a
few places. So sending this as a separate series seemed the better strategy.
This commit does two things:
1. renames _do_fork() to kernel_clone() but keeps _do_fork() as a simple static
inline wrapper around kernel_clone().
2. Changes the return type from long to pid_t. This aligns kernel_thread() and
kernel_clone(). Also, the return value from kernel_clone that is surfaced in
fork(), vfork(), clone(), and clone3() is taken from pid_vrn() which returns
a pid_t too.
通过分析3个fork机制最终都调用了kernel_clone(一个体系无关的函数),它之前的名字为_do_fork(),具体原因见上面commit内容。
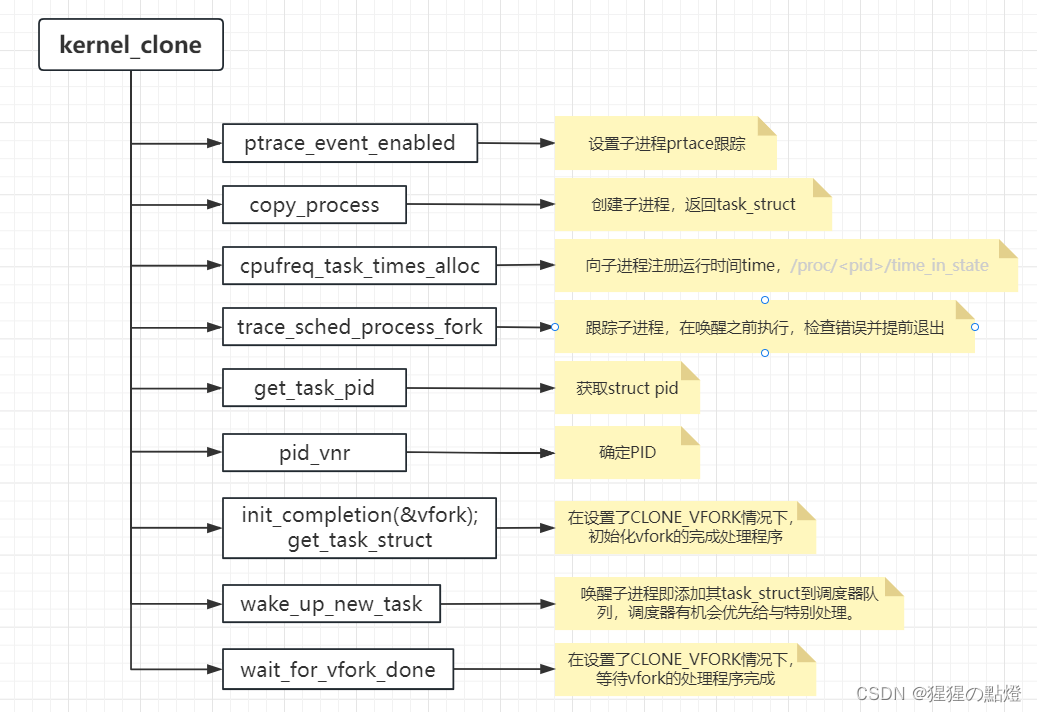
4、copy_process复制进程
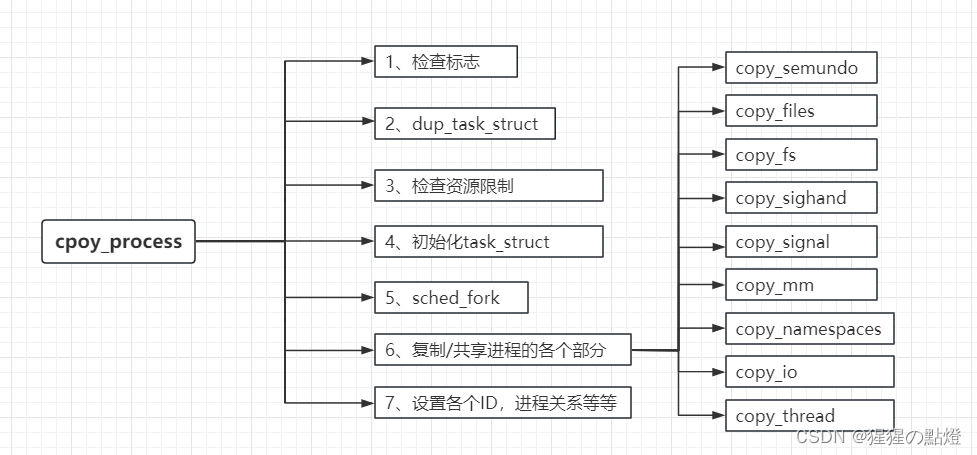
(1)检查标志
针对某些标志组合没有意义的情况,内核必须捕获这种情况,例如,一方面要求创建一个新命名空间(CLONE_NEWNS),而同时要求与父进程共享所有的文件系统信息(CLONE_FS)是没有意义的,因此需要返回错误码(一个指向虚拟地址0到至少4KiB的区域的指针,该区域没有任何有意义的信息,内核可以重用该地址范围来编码错误码)
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
# kernel/linux-5.10/include/linux/err.h
static inline void * __must_check ERR_PTR(long error)
{
return (void *) error;
}(2)dup_task_struct
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)建立父进程task_struct的副本,用于子进程的新的task_struct实例可以在任何空闲的内核内存位置分配。父子进程的task_struct实例只有一个成员不同:新进程分配一个新的核心态栈即task_struct->stack。在当前内核版本中stack和task_struct一同保存在一个联合中,具体可参考之前章节:Linux Kernel:thread_info与task_struct_猩猩の點燈的博客-优快云博客
#kernel/linux-5.10/include/linux/sched.h
static inline struct thread_info *task_thread_info(struct task_struct *task)
{
return &task->thread_info;
}
#kernel/linux-5.10/include/linux/sched/task_stack.h
static inline void *task_stack_page(const struct task_struct *task)
{
return task->stack;
}上述两个接口分别用于获取给定task_struct实例的线程信息(thread_info)和核心态栈(stack)
(3)检查资源限制
在dup_task_struct调用成功后,内核会检查当前的特定用户在创建新进程之后,是否会超过允许的最大进程数目:
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}拥有当前进程的用户,其资源计数器保存在一个user_struct实例中,可通过task_struct->cred->user_struct->processes访问,如果该值超过rlimit设置的限制,则放弃创建进程,除非当前用户是root用户或分配了特别权限(CAP_SYS_RESOURCE或CAP_SYS_ADMIN)
extern struct user_struct root_user;
#define INIT_USER (&root_user)
/* root_user.__count is 1, for init task cred */
struct user_struct root_user = {
.__count = REFCOUNT_INIT(1),
.processes = ATOMIC_INIT(1),
.sigpending = ATOMIC_INIT(0),
.locked_shm = 0,
.uid = GLOBAL_ROOT_UID,
.ratelimit = RATELIMIT_STATE_INIT(root_user.ratelimit, 0, 0),
};(4)初始化
对返回的task_struct实例成员进程初始化,这里暂不展开说明。
#复制由fork创建的新进程凭证
retval = copy_creds(p, clone_flags);
... ...
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER | PF_IDLE);
p->flags |= PF_FORKNOEXEC;
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = p->stime = p->gtime = 0;
prev_cputime_init(&p->prev_cputime);
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cputimers_init(&p->posix_cputimers);
p->io_context = NULL;
audit_set_context(p, NULL);
cgroup_fork(p);
... ...(5)sched_fork
如果资源限制无法防止进程建立,则可以调用sched_fork接口函数以便使调度器有机会对新进程进行设置。该接口会初始化一些统计字段,此外进程状态设置为TASK_RUNNING,由于新进程事实上还没运行,这个状态实际上不是真实的,但是可以防止内核的任何其他部分试图将进程状态从非运行改为运行,并在进程的设置彻底完成之前调度进程。
(6)复制/共享进程
通过诸多copy_xxx例程复制或共享特定的内核子系统资源。task_struct包含了一些指针,指向具体数据结构的实例,描述了可共享或可复制的资源。由于子进程时task_struct是从父进程task_struct精确复制而来,因此相关的指针最初都指向了同样的资源。
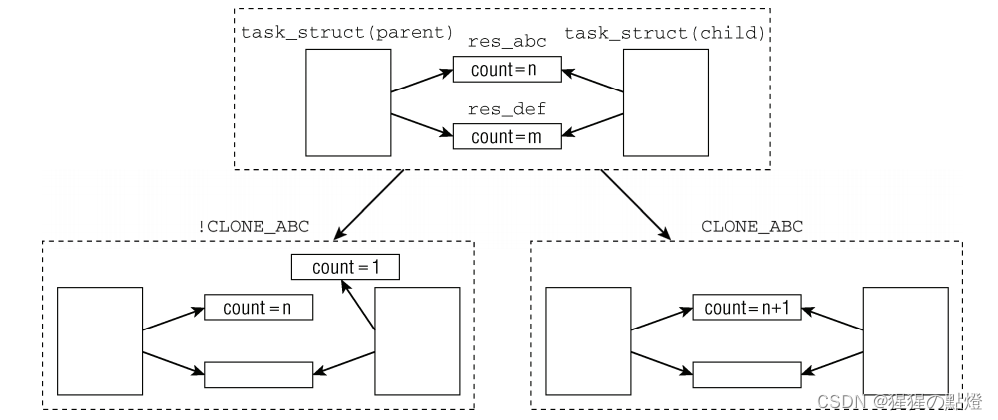
假定有两个资源:res_adb和res_def,最初父子进程的task_struct中的对应指针都指向了资源的同一个实例,即内存中特定的数据结构。
如果CLONE_ABC置位(右下),则两个进程会共享res_adc,此外,为防止与资源实例关联的内存空间释放过快,还需要对实例的引用计数器加1,只有进程不在使用内存时才能释放,如果父进程或子进程修改了共享资源,则变化在两个进程中都可以看到。
如果CLONE_ABC没有置位(左下),则会为子进程创建res_abc的一份副本,新副本的资源计数器初始化为1,如果父进程或子进程修改了资源,变化不会传播到另一个进程。
- COPY_SYSVSEM置位:copy_semundo使用父进程的System V信号量
- CLONE_FILES置位:copy_files使用父进程的文件描述符;否则创建新的files结构,其中包含的信息与父进程相同,该信息的修改可以独立于原结构。
- CLONE_FS置位:copy_fs使用父进程的文件系统上下文(task_struct->fs_struct),包含了诸如根目录,进程的当前工作目录之类的信息。
- CLONE_SIGHAND或CLONE_THREAD置位:copy_sighand使用父进程的信号处理程序(task_struct->sighand)。
- CLONE_THREAD置位:copy_signal与父进程共同使用信号处理中不特定于处理程序的部分(task_struct->signal)
- CLONE_MM置位:copy_mm让父子进程共享同一地址空间,两个进程使用同一个mm_struct实例(task_struct->mm)
- CLONE_MM没有置位并不意味着需要复制父进程的整个地址空间,内核会创建页表的一份副本,但并不复制页的实际内容。这里使用COW机制完成,仅当其中一个进程将数据写入页时,才会进行实际复制。
copy_namespaces用于建立子进程的命名空间。其语义与标志跟上述CLONE_NEWxxx标志刚好相反,如果没有指定CLONE_NEWxxx则与父进程共享相应的命名空间,否则创建一个新的命名空间。
if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWCGROUP | CLONE_NEWTIME)))) { if (likely(old_ns->time_ns_for_children == old_ns->time_ns)) { get_nsproxy(old_ns); return 0; } }
CLONE_IO置位:copy_io与父进程共享io上下文,否则创建新的io上下文副本
copy_thread与其他复制操作不大相同,这是一个特定于体系结构的函数,用于复制进程中特定于线程(thread-specific)的数据,重要的是填充task_struct->thread的各个成员。这是一个thread_struct类型的结构,其定义是体系结构相关的,它包含了所有寄存器,内核在进程之间切换时需要保存和恢复进程的内容。
(7)设置ID,进程关系等
内核必须填好task_struct中对父子进程不同的各个成员:
- task_struct中包含的各个链表元素,例如sibling和children;
- 间隔定时器成员cpu_timers;
- 待决信号列表pending
使用之前描述的机制为进程分配一个新的pid实例之后,保存进task_struct中,对于线程,线程组ID与分支进程相同:通过向pid_nr传入pid实例计算全局数值PID,对于线程来说还需要另一个校正,即普通进程的线程组组长是进程本身,对线程来说,其组长是当前进程的组长。
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
p->group_leader = p;
p->tgid = p->pid;
}设置子进程真正的父进程:
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
if (clone_flags & CLONE_THREAD)
p->exit_signal = -1;
else
p->exit_signal = current->group_leader->exit_signal;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
p->exit_signal = args->exit_signal;
}子进程最后通过children链表与父进程连接起来:
init_task_pid_links(p);
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
init_task_pid(p, PIDTYPE_TGID, pid);
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));
init_task_pid(p, PIDTYPE_SID, task_session(current));
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->shared_pending.signal = delayed.signal;
p->signal->tty = tty_kref_get(current->signal->tty);
/*
* Inherit has_child_subreaper flag under the same
* tasklist_lock with adding child to the process tree
* for propagate_has_child_subreaper optimization.
*/
p->signal->has_child_subreaper = p->real_parent->signal->has_child_subreaper ||
p->real_parent->signal->is_child_subreaper;
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_TGID);
attach_pid(p, PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID);
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
refcount_inc(¤t->signal->sigcnt);
task_join_group_stop(p);
list_add_tail_rcu(&p->thread_group,
&p->group_leader->thread_group);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID);
nr_threads++;
}三:内核线程
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,与系统中的其他进程“并行”执行。内核线程经常称之为守护进程:
功能:
- 周期性地将修改的内存页与页来源块设备同步(例如mmap的文件映射)
- 如果内存页很少使用,则写入交换区
- 管理延时动作(deferred action)
- 实现文件系统的事务日志
两个类型内核线程:
- 线程启动后一直等待,直至内核请求线程执行某一特定操作
- 线程启动后按周期性间隔运行,检测特定资源的使用,在用量超出或低于预置的限制值时采取行动。内核使用这类线程用于连续监测任务
内核线程特别之处:
- 它们在CPU的管态(supervisor mode)执行,而不是用户状态
- 它们只可以访问虚拟地址空间的内核部分(高于TASK_SIZE的所有地址),不能访问用户空间
kernel_thread用于启动内核线程:
/* * Create a kernel thread. */ pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags) { struct kernel_clone_args args = { .flags = ((lower_32_bits(flags) | CLONE_VM | CLONE_UNTRACED) & ~CSIGNAL), .exit_signal = (lower_32_bits(flags) & CSIGNAL), .stack = (unsigned long)fn, .stack_size = (unsigned long)arg, }; return kernel_clone(&args); }
- 该函数从内核线程释放其父进程(用户进程)的所有资源(内存上下文,文件描述符等等),不然这些资源会一直锁定到线程结束,这是不可取的,因为守护进程通常运行到系统关机为止,并且只操作内核地址区域,甚至不需要这些资源。
- daemonize阻塞信号的接收
- 将init用作守护进程的父进程
内核线程的创建有个更现代的方法:kthread_create
名称由namefmt给出,最初该线程是停止的,需要使用wake_up_process启动它,此后会调用通过threadfn给出的线程函数。
#define kthread_create(threadfn, data, namefmt, arg...) \
kthread_create_on_node(threadfn, data, NUMA_NO_NODE, namefmt, ##arg)
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node,
const char namefmt[],
...)
{
struct task_struct *task;
va_list args;
va_start(args, namefmt);
task = __kthread_create_on_node(threadfn, data, node, namefmt, args);
va_end(args);
return task;
}内核线程的其他创建方式:宏kthread_run与kthread_create区别是创建后立即唤醒
#define kthread_run(threadfn, data, namefmt, ...) \
({ \
struct task_struct *__k \
= kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \
if (!IS_ERR(__k)) \
wake_up_process(__k); \
__k; \
})四:启动新程序
通过用新代码替换现在内存程序,即可启动新程序。
execve系统调用可用于该目的。
1、execve的实现
该系统调用的入口点是体系结构相关的函数,宏展开即为__arm64_sys_execve函数,随后该函数会调用与系统体系结构无关的do_execve函数。
#kernel/linux-5.10/fs/exec.c
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}do_execve接口不仅用参数传递了寄存器集合和可执行文件的名称(filename),而且还传递了指向程序的参数和环境的指针。argv和envp都是指针数组,argv包含在命令行上传递给该程序的所有参数(例如,ls -l /usr/bin就是-l和/usr/bin),指向两个数组自身的指针以及数组中的所有指针都位于虚拟地址空间的用户空间部分。
2、解释二进制格式
Linux内核中,每种二进制格式都表示为下列数据结构:
#kernel/linux-5.10/include/linux/binfmts.h struct linux_binfmt { struct list_head lh; struct module *module; int (*load_binary)(struct linux_binprm *); int (*load_shlib)(struct file *); int (*core_dump)(struct coredump_params *cprm); unsigned long min_coredump; /* minimal dump size */ } __randomize_layout;
- load_binary用于加载普通程序
- load_shlib用于加载共享库
- core_dump用于在程序错误的情况下输出内存转储
- min_coredump是生成内存转储时,内存转储文件长度的下界
每种二进制格式首先必须使用register_binfmt想内核注册:
#kernel/linux-5.10/include/linux/binfmts.h
static inline void register_binfmt(struct linux_binfmt *fmt)
{
__register_binfmt(fmt, 0);
}
#kernel/linux-5.10/fs/exec.c
static LIST_HEAD(formats);
static DEFINE_RWLOCK(binfmt_lock);
void __register_binfmt(struct linux_binfmt * fmt, int insert)
{
BUG_ON(!fmt);
if (WARN_ON(!fmt->load_binary))
return;
write_lock(&binfmt_lock);
insert ? list_add(&fmt->lh, &formats) :
list_add_tail(&fmt->lh, &formats);
write_unlock(&binfmt_lock);
}五:退出进程
进程必须使用exit系统调用终止。这使得内核有机会将该进程使用的资源释放回系统。
#kernel/linux-5.10/kernel/exit.c
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code&0xff)<<8);
}
void __noreturn do_exit(long code)
















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









