







 本文主要探讨Linux内核中的PID机制和命名空间。介绍了进程的三种创建方式:fork、exec和clone,重点讲解命名空间的概念,包括其作用、结构以及如何创建。命名空间提供了一种轻量级的虚拟化形式,使得不同进程可以拥有各自的资源视图,如UTS、IPC、MNT、PID、NET、TIME和CGROUP命名空间。同时,文章详细阐述了PID的管理,包括进程ID的分配、查找和引用计数。最后,讨论了进程之间的关系,如父进程、子进程和兄弟进程的链表结构。
本文主要探讨Linux内核中的PID机制和命名空间。介绍了进程的三种创建方式:fork、exec和clone,重点讲解命名空间的概念,包括其作用、结构以及如何创建。命名空间提供了一种轻量级的虚拟化形式,使得不同进程可以拥有各自的资源视图,如UTS、IPC、MNT、PID、NET、TIME和CGROUP命名空间。同时,文章详细阐述了PID的管理,包括进程ID的分配、查找和引用计数。最后,讨论了进程之间的关系,如父进程、子进程和兄弟进程的链表结构。
环境:
Kernel Version:Linux-5.10
ARCH:ARM64
一:前言
Linux内核涉及进程和程序的所有算法都围绕task_struct数据结构建立,具体可看另一篇文章:
Linux Kernel:thread_info与task_struct
同时Linux提供了资源限制(resource limit, rlimit)机制,对进程使用系统资源施加某些限制,数据类型为:struct rlimit和struct rlimit64,该机制后续会新开一章详细分析。
struct rlimit {
__kernel_ulong_t rlim_cur;
__kernel_ulong_t rlim_max;
};
#define RLIM64_INFINITY (~0ULL)
struct rlimit64 {
__u64 rlim_cur;
__u64 rlim_max;
};二:进程类型
典型UNIX进程的产生方式:fork,exec
- fork生成当前进程的一个相同副本,该副本称之为子进程。原进程的所有资源都以适当的方式复制到子进程,因此该系统调用后,原来的进程就有了两个独立的实例。这两个实例的联系包括:同一组打开文件,同样的工作目录,内存中同样的数据(两个进程各有一份副本),等等。此外两者再无关联。
- exec从一个可执行的二进制文件加载另一个应用程序,来代替当前运行的程序。因为exec并不创建新进程,所以必须先使用fork复制一个旧的程序,然后调用exec在系统上创建另一个应用程序。
除过上述两种进程产生方式外,Linux还提供了clone系统调用。clone的工作原理基本上与fork相同,但新进程不是独立于父进程,而可以与其共享某些资源。可以指定需要共享和复制的资源种类,例如,父进程的内存数据,打开文件或安装的信号处理程序。clone用于实现线程,但仅仅该系统调用不足以做到这一点,还需要用户空间库才能提供完整的实现。
三:命名空间
1、概述
命名空间提供了虚拟化的一种轻量级形式,使得我们可以从不同的方面来查看运行系统的全局属性,所需资源较少。本质上,命名空间建立了系统的不同视图。此前的每一项全局资源都必须包装到容器数据结构中,只有资源和包含资源的命名空间构成的二元组仍然是全局唯一的,虽然在给定容器内部资源是自足的,但无法在容器外部具有唯一的ID。
如下图:命名空间可以按层次关联起来。每个命名空间都发源于一个父命名空间,一个父命名空间可以有多个子命名空间,并且两个子命名空间都有PID为1,2,3的进程。由于相同PID在系统中出现多次,所以PID号不是全局唯一的。虽然子容器不了解系统中的其他容器,但父容器知道子命名空间的存在,也可以看到其中执行的所有内容。
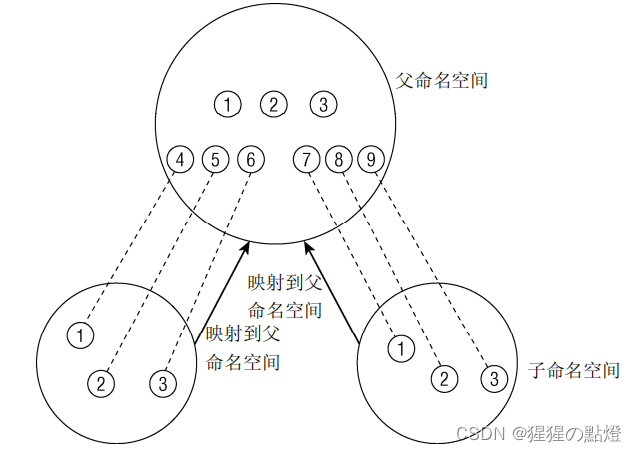
新的命名空间创建方法:
1、在用fork或clone系统调用创建新进程时,有特定的选项可以控制是否与父进程共享命名空间还是建立新的命名空间。
2、unshare系统调用将进程的某些部分从父进程分离,其中也包括命名空间。
命名空间的实现需要两个部分:
1、每个子系统的命名空间结构,将此前所有的全局组件包装到命名空间中。
2、将给定进程关联到所属各个命名空间的机制
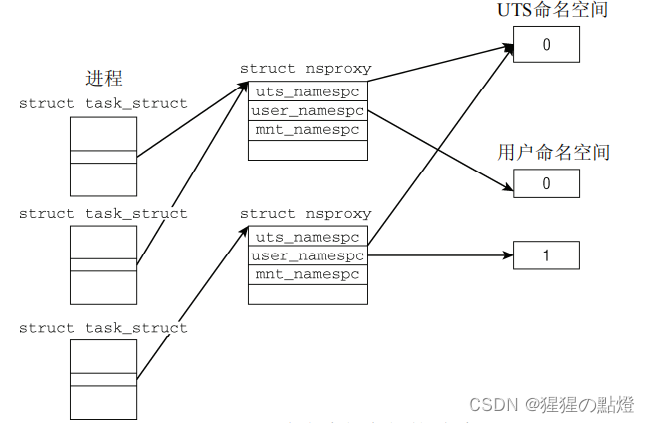
2、数据结构
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};目前该内核以下范围可以感知到命名空间:
- UTS命名空间包含了运行内核的名字,版本,底层体系结构类型等信息。
- IPC命名空间包含所有与进程间通讯(IPC)有关的信息。
- MNT命名空间包含已经挂载的文件系统视图。
- PID命名空间包含有关进程ID的信息。
- NET包含所有网络相关的命名空间参数。
- TIME命名空间包含时钟相关的信息。
- CGROUP命名空间包含进程在该点所属的cgroup。
struct cred {
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
}
- USER命名空间包含用于限制每个用户资源使用的信息。
对于命名空间的支持必须在编译时启动,而且必须逐一指定需要支持的命名空间
root@ubuntu:/# zcat /proc/config.gz | grep -e CONFIG_USER_NS -e CONFIG_TIME_NS -e CONFIG_IPC_NS -e CONFIG_PID_NS -e CONFIG_MNT_NS -e CONFIG_NET_NS -e CONFIG_UTS_NS
CONFIG_UTS_NS=y
CONFIG_TIME_NS=y
CONFIG_IPC_NS=y
CONFIG_USER_NS=y
CONFIG_PID_NS=y
CONFIG_NET_NS=y
# CONFIG_NET_NSH is not set命名空间初始化是在init_task时进行:init_nsproxy
struct nsproxy init_nsproxy = {
.count = ATOMIC_INIT(1),
.uts_ns = &init_uts_ns,
#if defined(CONFIG_POSIX_MQUEUE) || defined(CONFIG_SYSVIPC)
.ipc_ns = &init_ipc_ns,
#endif
.mnt_ns = NULL,
.pid_ns_for_children = &init_pid_ns,
#ifdef CONFIG_NET
.net_ns = &init_net,
#endif
#ifdef CONFIG_CGROUPS
.cgroup_ns = &init_cgroup_ns,
#endif
#ifdef CONFIG_TIME_NS
.time_ns = &init_time_ns,
.time_ns_for_children = &init_time_ns,
#endif
};四:进程ID号
UNIX进程总是会分配一个号码用于在其命名空间中唯一地标识它们。该号码被称作进程ID号,简称PID。用fork或clone产生的每个进程都由内核自动地分配了一个新的唯一的PID值。
1、进程ID
每个进程除了PID这个特征值之外,还有其他ID,处于某个线程组中的所有进程都有统一的线程组ID(TGID),如果进程没有使用线程,则其PID和TGID相同。
全局PID与TGID直接保存在task_struct中,分别为成员pid与tgid:
struct task_struct {
...
pid_t pid;
pid_t tgid;
...
}其中会话(session)和进程组(pgrp)ID则是从task_struct中移到信号处理结构signal_struct中:
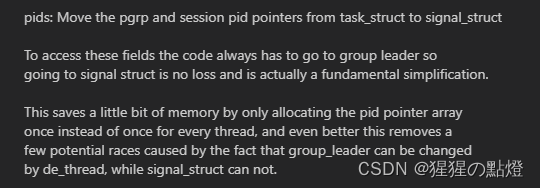
struct task_struct {
...
struct signal_struct *signal;
...
}
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_TGID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX,
};
struct signal_struct {
/* PID/PID hash table linkage. */
struct pid *pids[PIDTYPE_MAX];
}命名空间增加了PID管理的复杂性,PID命名空间按层次组织。在建立一个新的命名空间时,该命名空间中的所有PID是对父命名空间可见的,但子命名空间无法看到父命名空间的PID。这意味着某些进程具有多个PID,凡是可以看到该进程的命名空间,都会为其分配一个PID。这必须反映在数据结构中,我们必须区分局部ID和全局ID。
- 全局ID是在内核本身和初始命名空间中的唯一ID号,在系统启动期间开始的init进程即属于初始命名空间。对每个ID类型,都有一个给定的全局ID,保证在整个系统中是唯一的
- 局部ID属于某个特定的命名空间,不具备全局有效性。
2、管理PID
除过上述提到的会话,进程组ID外,还需要一个来管理所有命名空间内部的局部量和其他ID(TGID线程组ID)的方法:一个小型的子系统称之为PID分配器(PID allocator)用于加速新ID的分配。此外内核还需要提供辅助函数,以实现通过ID及其类型查找进程的task_struct的功能,以及将ID的内核表示形式和用户空间可见的数值进行转换的功能。
在此之前说明下PID命名空间,因为PID分配器也需要依赖该结构一些部分来连续生成唯一ID
struct pid_namespace {
... ...
unsigned int pid_allocated;
struct task_struct *child_reaper;
unsigned int level;
struct pid_namespace *parent;
... ...
} __randomize_layout;
- 每个PID命名空间都具有一个进程,其发挥的作用相当于全局的init进程。init的一个 目的是对孤儿进程调用wait4,命名空间局部init变体也必须完成该工作。child_reaper保存了指向该进程的task_struct的指针。
- parent是指向父命名空间的指针,level表示当前命名空间在命名空间层次结构中的深度
PID的管理围绕两个数据结构展开:struct pid是内核对PID的内部表示,struct upid表示特定的命名空间中可见的信息。
- upid数据结构:nr表示ID数值,ns是指向该ID所属的命名空间指针,pid_chain在v4.15被取消。Struct upid用于获取Struct pid的id,在特定的命名空间中可以看到。接下来使用int nr和struct pid_namespace *ns通过find_pid_ns()接口可以方向找到struct pid。
- pid数据结构:count表示引用计数器,
#kernel/linux-5.10/include/linux/pid.h
struct upid {
int nr;
struct pid_namespace *ns;
# struct hlist_node pid_chain; //在linux-v4.15取消了该结构体散列表成员
};
struct pid
{
refcount_t count;
unsigned int level;
spinlock_t lock;
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX];
struct hlist_head inodes;
/* wait queue for pidfd notifications */
wait_queue_head_t wait_pidfd;
struct rcu_head rcu;
struct upid numbers[1];
};如果已经分配了struct pid一个新实例,并设置了ID类型,它会通过接口attach_pid加入到task_struct->pid(thread_pid或者singal->pids[type])->tasks中,而attach_pid自身被调用可以追溯到fork.c文件copy_process接口。
struct task_struct {
/* PID/PID hash table linkage. */
struct pid *thread_pid;
struct hlist_node pid_links[PIDTYPE_MAX];
}
static struct pid **task_pid_ptr(struct task_struct *task, enum pid_type type)
{
return (type == PIDTYPE_PID) ?
&task->thread_pid :
&task->signal->pids[type];
}
/*
* attach_pid() must be called with the tasklist_lock write-held.
*/
void attach_pid(struct task_struct *task, enum pid_type type)
{
struct pid *pid = *task_pid_ptr(task, type);
hlist_add_head_rcu(&task->pid_links[type], &pid->tasks[type]);
}3、函数
内核提供了许多辅助函数用于操作和扫描上述提到的数据结构,并且必须完成如下两个任务:
- 给出局部数字ID和对应的命名空间,查找此二元组描述的task_struct
- 给出task_struct,ID类型,命名空间,查找该命名空间局部数字ID
find_pid_ns():通过nr和命名空间查找对应pid
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)
{
return idr_find(&ns->idr, nr);
}
EXPORT_SYMBOL_GPL(find_pid_ns);find_task_by_pid_ns():通过nr和命名空间查找对应task_struct
struct task_struct *find_task_by_pid_ns(pid_t nr, struct pid_namespace *ns)
{
RCU_LOCKDEP_WARN(!rcu_read_lock_held(),
"find_task_by_pid_ns() needs rcu_read_lock() protection");
return pid_task(find_pid_ns(nr, ns), PIDTYPE_PID);
}get_task_pid(): 通过task_struct和对应ID类型查找pid
struct pid *get_task_pid(struct task_struct *task, enum pid_type type)
{
struct pid *pid;
rcu_read_lock();
pid = get_pid(rcu_dereference(*task_pid_ptr(task, type)));
rcu_read_unlock();
return pid;
}
EXPORT_SYMBOL_GPL(get_task_pid);get_pid_task():通过pid和类型查找task_struct
struct task_struct *get_pid_task(struct pid *pid, enum pid_type type)
{
struct task_struct *result;
rcu_read_lock();
result = pid_task(pid, type);
if (result)
get_task_struct(result);
rcu_read_unlock();
return result;
}
EXPORT_SYMBOL_GPL(get_pid_task);还有诸多相关接口给出类型,详细实现文章中不在一一罗列:
struct pid *find_get_pid(pid_t nr);
pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns);
pid_t pid_vnr(struct pid *pid);
pid_t __task_pid_nr_ns(struct task_struct *task, enum pid_type type,
struct pid_namespace *ns)
在v4.15之前内核为了避免id冲突而在struct upid中使用了struct hlist_node pid_chain散列溢出表解决这个问题,截止目前v5.10,pidhash(散列表)不再需要,因为所有信息都可以从idr tree(kernel/linux-5.10/lib/idr.c)中查找到,nr_hashed表示已经删除的散列表数目,nr_hashed和PIDNS_HASH_ADDING不再相关,它们分别重命名为pid_allocated和PIDNS_ADDING
# v4.15之前
struct pid_namespace init_pid_ns = {
.nr_hashed = PIDNS_HASH_ADDING,
};
# v4.15之后
struct pid_namespace init_pid_ns = {
.pid_allocated = PIDNS_ADDING,
};
EXPORT_SYMBOL_GPL(init_pid_ns);ldr tree的实例被应用在下面三个接口中,对应也是fork接口中的重要组成部分。
struct pid *alloc_pid(struct pid_namespace *ns, pid_t *set_tid, size_t set_tid_size);
void free_pid(struct pid *pid);
void put_pid(struct pid *pid);五:进程关系
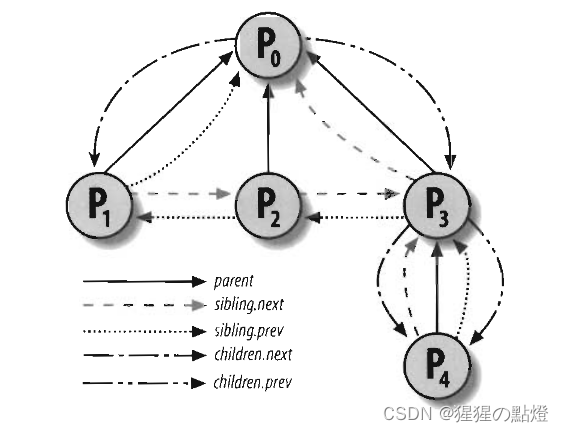
在task_struct中有两个链表用来实现进程之前的关系
/* Recipient of SIGCHLD, wait4() reports: */ struct task_struct __rcu *parent; struct list_head children; struct list_head sibling;
- children:子进程链表
- sibling:连接到父进程的子进程链表(兄弟链表)

















 6416
6416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









