







 本文详细介绍了Linux Kernel中的调度器实现,包括调度器的数据结构、优先级处理和核心调度器的工作原理。调度器通过红黑树组织就绪队列,确保进程公平共享CPU时间。调度器类如实时调度器、完全公平调度器等各自有相应的操作函数。在上下文切换时,内核通过context_switch等函数完成进程间的切换工作,确保系统的高效运行。
本文详细介绍了Linux Kernel中的调度器实现,包括调度器的数据结构、优先级处理和核心调度器的工作原理。调度器通过红黑树组织就绪队列,确保进程公平共享CPU时间。调度器类如实时调度器、完全公平调度器等各自有相应的操作函数。在上下文切换时,内核通过context_switch等函数完成进程间的切换工作,确保系统的高效运行。
目录
环境:
Kernel Version:Linux-5.10
ARCH:ARM64
一:概述
内核针对若干连接起来的进程任务能公平地共享CPU时间,创造并行执行的错觉,并且需要考虑到不同任务的优先级问题提供了一种方法即schedule(调度器),调度器的一般原理是,按所能分配的计算能力,向系统中的每个进程提供最大的公正性,例如有N个进程,那么每个进程会得到总计算能力的1/N,所有的进程在物理上真实的并行执行。每次调用调度器时,都会挑选具有最高等待时间的进程,这些按照等待时间排队的结构称之为就绪队列。
#kernel/linux-5.10/kernel/sched/core.c
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
sched_update_worker(tsk);
}
EXPORT_SYMBOL(schedule);所有可运行进程都按等待时间在一个红黑树中排序,等待CPU时间最长的进程是最左侧的项,调度器下一次会考虑调用该进程。等待时间按照长短在该树上从左至右排序。
除过红黑树之外,就绪队列还装备了虚拟时钟。该时钟的时间流逝速度慢于实际的时钟,精确的速度依赖于当前等待调度器挑选的进程的数目。假定该队列上有4个进程,那么该虚拟时钟将以实际时钟四分之一的速度运行。
为了更好的理解调度决策,在编译时激活调度器统计,运行时文件保存在/proc/sched_debug
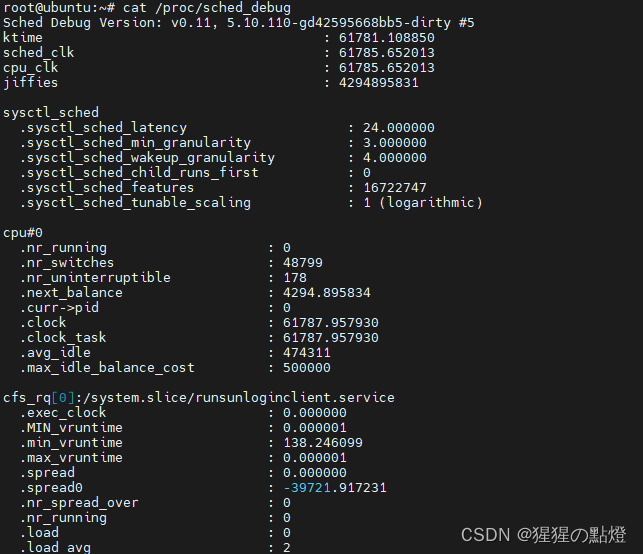
这里推荐一个数据结构可视化网站,对于红黑树及其他不是很清楚的同学可以学习:Data Structure Visualization
二:调度器实现
1、数据结构
(1)task_struct成员
struct task_struct {
...
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
unsigned int policy;
int nr_cpus_allowed;
...
}
prio,static_prio,normal_prio:表示进程优先级,prio表示动态优先级,normal_prio表示普通优先级,static_prio表示进程静态优先级。静态优先级是进程启动时分配的优先级。它可以使用nice和sched_setscheduler系统调用修改,否则在进程运行期间会一直保持恒定。normal_priority表示基于进程的静态优先级和调度策略计算出的优先级,因此即使普通进程和实时进程具有相同的静态优先级,其普通优先级也是不同的。进程复制时,子进程会继承普通优先级。调度器考虑的优先级则保存在prio中。
/* * Scheduling policies */ #define SCHED_NORMAL 0 #通过完全公平调度器来处理,用于普通进程 #define SCHED_FIFO 1 #通过实时调度器类处理,使用先进先出机制 #define SCHED_RR 2 #通过实时调度器类处理,实现一种循环方式 #define SCHED_BATCH 3 #通过完全公平调度器来处理,用于非交互,CPU使用密集的批处理进程 /* SCHED_ISO: reserved but not implemented yet */ #define SCHED_IDLE 5 #通过完全公平调度器来处理,注意名字虽为IDLE但是不负责调度空闲进程 #define SCHED_DEADLINE 6 #最后期限调度算法
- nr_cpus_allowed:位域,在多处理器系统上使用,用来限制进程可以在哪些CPU上运行
- rt.run_list和rt.time_slice:循环实时调度器需要,不用于完全公平调度器。run_list是一个表头,用于维护包含各进程的一个运行表,time_slice则指定进程可使用CPU的剩余时间段。
(2)调度器类
调度器类提供了通用调度器和各个调度方法之间的关联。调度器类由特定数据结构中汇集的几个函数指针表示。全局调度器请求的各个操作都可以由一个指针表示,对各个调度类,都必须提供sched_class的一个实例。调度类之间的层次结构是平坦的:实时进程最重要,在完全公平进程之前处理;完全公平进程则优于空闲进程;空闲进程只有CPU无事可做事才处于活动状态。
struct sched_class {
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task)(struct rq *rq, struct task_struct *p);
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
struct task_struct *(*pick_next_task)(struct rq *rq);
void (*put_prev_task)(struct rq *rq, struct task_struct *p);
void (*set_next_task)(struct rq *rq, struct task_struct *p, bool first);
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
void (*task_fork)(struct task_struct *p);
void (*task_dead)(struct task_struct *p);
/*
* The switched_from() call is allowed to drop rq->lock, therefore we
* cannot assume the switched_from/switched_to pair is serliazed by
* rq->lock. They are however serialized by p->pi_lock.
*/
void (*switched_from)(struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval)(struct rq *rq,
struct task_struct *task);
void (*update_curr)(struct rq *rq);
#define TASK_SET_GROUP 0
#define TASK_MOVE_GROUP 1
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_change_group)(struct task_struct *p, int type);
#endif
} __aligned(STRUCT_ALIGNMENT); /* STRUCT_ALIGN(), vmlinux.lds.h */
#kernel/linux-5.10/kernel/sched/core.c
void activate_task(struct rq *rq, struct task_struct *p, int flags)
{
enqueue_task(rq, p, flags);
p->on_rq = TASK_ON_RQ_QUEUED;
}
EXPORT_SYMBOL_GPL(activate_task);
void deactivate_task(struct rq *rq, struct task_struct *p, int flags)
{
p->on_rq = (flags & DEQUEUE_SLEEP) ? 0 : TASK_ON_RQ_MIGRATING;
dequeue_task(rq, p, flags);
}
EXPORT_SYMBOL_GPL(deactivate_task);
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
if (p->sched_class == rq->curr->sched_class)
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
else if (p->sched_class > rq->curr->sched_class)
resched_curr(rq);
/*
* A queue event has occurred, and we're going to schedule. In
* this case, we can save a useless back to back clock update.
*/
if (task_on_rq_queued(rq->curr) && test_tsk_need_resched(rq->curr))
rq_clock_skip_update(rq);
}
EXPORT_SYMBOL_GPL(check_preempt_curr);用户层应用程序无法直接与调度类交互,它们只知道上文定义的常量SCHED_xxx。这些常量和可用调度类之间提供适当的映射。SCHED_NORMAL,SCHED_BATCH和SCHED_IDLE映射到fair_sched_class,而SCHED_RR和SCHED_FIFO与rt_sched_class关联。
调度类优先级由高到低:stop_sched_class(停止调度类)>dl_sched_class(终止调度类)>rt_sched_class(实时调度类)>fair_sched_class(完全公平调度类)>idle_sched_class(空闲调度类)
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;(3)就绪队列
核心调度器用于管理活动进程的主要数据结构称之为就绪队列。各个CPU都有自身的就绪队列,各个活动进程只出现在一个就绪队列中。就绪队列是全局调度器许多操作的起点。但是进程并不是由就绪队列的成员直接管理,这是各个调度器类的职责,因此各个就绪队列中都嵌入了特定于调度器类的子就绪队列。
#kernel/linux-5.10/kernel/sched/sched.h
struct rq {
...
unsigned int nr_running;
...
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
...
struct task_struct __rcu *curr;
struct task_struct *idle;
struct task_struct *stop;
u64 clock;
...
};
nr_running:指定队列上可运行进程的数目,不考虑其优先级或调度类。
cfs,rt,dl:嵌入的子就绪队列,分别用于完全公平调度器,实时调度器和最终期限调度器。
curr:指向当前运行进程的task_struct实例。
idle:指向idle进程的task_struct实例,也称为idle线程,在无其他可运行进程时执行。
stop:指向stop进程的task_struct实例。
clock:用于实现就绪队列自身的时钟,每次调用周期性调度器时,都会更新clock值。
(4)调度实体
由于调度器可以操作比进程更一般的实体,因此需要一个适当的数据结构来描述此类实体:
struct sched_entity {
/* For load-balancing: */
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
/* cached value of my_q->h_nr_running */
unsigned long runnable_weight;
#endif
...
};
- load:指定了权重,决定了各个实体占队列总负荷的比例。计算负荷权重是调度器的一项重任,因为CFS所需的虚拟时钟的速度最终依赖于负荷。
run_node:红黑树节点,实体可以在其上排序
group_node:组链表节点
on_rq:表示该实体当前是否在就绪队列行接收调度
exec_start:完全公平调度开始时间,每次调用时更新到当前时间
sum_exec_runtime:记录进程运行时消耗的CPU时间以用于完全公平调度器
vruntime:进程执行期间虚拟时钟上流逝的时间数量
prev_sum_exec_runtime:在进程被撤销CPU时,其当前sum_exec_runtime值保存到prev_sum_exec_runtime中,而sum_exec_runtime继续单调增长,当之后进程抢占时又需要该数据
2、处理优先级
(1)优先级表示
在用户空间可通过nice命令设置进程的静态优先级,内部会调用nice系统调用。进程的nice值范围为(-20~+19),值越低表明优先级越高。
内核使用了一个简单的数值范围(0~139)来表示内部优先级,同样值越低优先级越高,从0到99的范围专攻实时进程使用,nice值(-20~+19)映射到范围(100~139),实时进程的优先级总是比普通进程高。

内核中定义的一些优先级转换宏:
#kernel/linux-5.10/include/linux/sched/prio.h
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
/*
* 'User priority' is the nice value converted to something we
* can work with better when scaling various scheduler parameters,
* it's a [ 0 ... 39 ] range.
*/
#define USER_PRIO(p) ((p)-MAX_RT_PRIO)
#define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio)
#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))(2)计算优先级
在本文数据结构章节提及过优先级分为3种即动态优先级task_struct->prio,普通优先级task_struct->normal_prio和静态优先级task_struct->static_prio,在计算优先级是必须都考虑到。
static_prio作为计算起点,假定已经设置好,内核可通过以下函数计算出其他优先级:
#kernel/linux-5.10/kernel/sched/core.c
p->prio = effective_prio(p);
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
/*
* If we are RT tasks or we were boosted to RT priority,
* keep the priority unchanged. Otherwise, update priority
* to the normal priority:
*/
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
static inline int normal_prio(struct task_struct *p)
{
return __normal_prio(p->policy, p->rt_priority, PRIO_TO_NICE(p->static_prio));
}
static inline int __normal_prio(int policy, int rt_prio, int nice)
{
int prio;
if (dl_policy(policy))
prio = MAX_DL_PRIO - 1;
else if (rt_policy(policy))
prio = MAX_RT_PRIO - 1 - rt_prio;
else
prio = NICE_TO_PRIO(nice);
return prio;
}在新建进程时或使用nice系统调用改变静态优先级时则使用上述给出的方法设置p->prio:
#kernel/linux-5.10/kernel/sched/core.c
void set_user_nice(struct task_struct *p, long nice)
{
...
p->prio = effective_prio(p);
...
}(3)计算负荷权重
进程的重要性不仅是由优先级指定,还需要考虑负荷权重(task_struct->se.load),set_load_weight函数负责根据进程类型和静态优先级计算负荷权重
#kernel/linux-5.10/include/linux/sched.h
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
#define WEIGHT_IDLEPRIO 3
#define WMULT_IDLEPRIO 1431655765
#kernel/linux-5.10/kernel/sched/core.c
static void set_load_weight(struct task_struct *p, bool update_load)
{
int prio = p->static_prio - MAX_RT_PRIO;
struct load_weight *load = &p->se.load;
/*
* SCHED_IDLE tasks get minimal weight:
*/
if (task_has_idle_policy(p)) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
/*
* SCHED_OTHER tasks have to update their load when changing their
* weight
*/
if (update_load && p->sched_class == &fair_sched_class) {
reweight_task(p, prio);
} else {
load->weight = scale_load(sched_prio_to_weight[prio]);
load->inv_weight = sched_prio_to_wmult[prio];
}
}在计算权重的函数中有两个特殊数组用于计算被负荷权重运算除的结果,一般概念为进程每降低一个nice值,则多获得10%的CPU时间,每升高一个nice值,则放弃10%的CPU时间。为执行该策略,内核将优先级转换为权重值:
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
/*
* Inverse (2^32/x) values of the sched_prio_to_weight[] array, precalculated.
*
* In cases where the weight does not change often, we can use the
* precalculated inverse to speed up arithmetics by turning divisions
* into multiplications:
*/
const u32 sched_prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};3、核心调度器
(1)周期性调度器
周期性调度器在scheduler_tick中实现,如果系统正在活动中,内核会按照频率HZ自动调用该函数,该函数主要任务:
- 管理内核中与整个系统和各个进程的调度相关的统计量
- 激活负责当前进程的调度类的周期性调度方法
#kernel/linux-5.10/kernel/sched/core.c
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
unsigned long thermal_pressure;
arch_scale_freq_tick();
sched_clock_tick();
rq_lock(rq, &rf);
trace_android_rvh_tick_entry(rq);
update_rq_clock(rq);
thermal_pressure = arch_scale_thermal_pressure(cpu_of(rq));
update_thermal_load_avg(rq_clock_thermal(rq), rq, thermal_pressure);
curr->sched_class->task_tick(rq, curr, 0);
calc_global_load_tick(rq);
psi_task_tick(rq);
rq_unlock(rq, &rf);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
trace_android_vh_scheduler_tick(rq);
}
该函数的第一部分处理就绪队列时钟的更新,由update_rq_clock完成,本质就是增加struct rq当前实例的时钟时间戳。其余工作都完全委托给特定的调度器类来完成:
curr->sched_class->task_tick(rq, curr, 0);(2)主调度器
在内核中,如果要将CPU分配给与当前活动进程不同的另一个进程时都会直接调用主调度器函数schedule,其中__sched前缀用于调用schedule函数,包括自身。该前缀目的在于将相关函数的代码编译之后,放到目标文件的一个特定的段中(".sched.text"),该信息使得内核在现实栈转储或类似信息时,忽略所有与调度有关的调用。
#kernel/linux-5.10/include/linux/sched/debug.h
#define __sched __section(".sched.text")
#kernel/linux-5.10/kernel/sched/core.c
void __sched some_function(...)
{
...
schedule()
...
}
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
sched_update_worker(tsk);
}
EXPORT_SYMBOL(schedule);sched_submit_work:避免死锁
preempt_disable:关闭抢占
__schedule:重点函数,后续详解
sched_preempt_enable_no_resched:开启抢占
need_resched:如果TIF_NEED_RESCHED置位则需要重新调度当前进程
sched_update_worker:调度完成更新当前进程data
#kernel/linux-5.10/kernel/sched/core.c
static void __sched notrace __schedule(bool preempt){}
__schedule() 主要调度器函数,进入调度器的方法有:
1. 明确的阻塞: 互斥,信号,等待队列等。
2. 在中断和用户空间返回路径上检查TIF_NEED_RESCHED标志。例如:arch/x86/entry_64.S。
为了驱动任务之间的抢占,调度程序在计时器中断处理程序scheduler_tick()中设置标志。
3. 唤醒并不会真正导致进入schedule()。添加一个任务到就绪队列中。
现在,如果添加到就绪队列中的新任务抢占了当前任务,则唤醒设置TIF_NEED_RESCHED并在最近的可能场合调用schedule():
(1)如果内核是可抢占的(CONFIG_PREEMPTION=y):
- 在系统调用或异常上下文中,在下一个最外层preempt_enable()。(这可能与wake_up()的spin_unlock()一样快!)
- 在IRQ上下文中,从中断处理程序返回到可抢占上下文中t
(2)如果内核不是可抢占的(CONFIG_PREEMPTION没有设置),那么在下一步:
- cond_resched() call
- explicit schedule() call
- return from syscall or exception to user-space
- return from interrupt-handler to user-space
警告:必须在禁用抢占的情况下调用!
__schedule函数说明:
更新就绪队列的时钟:
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);因为调度器的模块化结构,大多数工作可以委托给调度类。如果当前进程原来处于可中断睡眠状态,现在接收到信号,那么它必须再次提升为运行进程。否则,用相应调度器类的方法使进程停止活动,其中终止调用依次为:deactivate_task->dequeue_task->sched_class->dequeue_task
prev_state = prev->state;
if (!preempt && prev_state) {
if (signal_pending_state(prev_state, prev)) {
prev->state = TASK_RUNNING;
} else {
prev->sched_contributes_to_load =
(prev_state & TASK_UNINTERRUPTIBLE) &&
!(prev_state & TASK_NOLOAD) &&
!(prev->flags & PF_FROZEN);
if (prev->sched_contributes_to_load)
rq->nr_uninterruptible++;
/*
* __schedule() ttwu()
* prev_state = prev->state; if (p->on_rq && ...)
* if (prev_state) goto out;
* p->on_rq = 0; smp_acquire__after_ctrl_dep();
* p->state = TASK_WAKING
*
* Where __schedule() and ttwu() have matching control dependencies.
*
* After this, schedule() must not care about p->state any more.
*/
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
}
switch_count = &prev->nvcsw;
}调度类选择下一个应该执行的进程:
next = pick_next_task(rq, prev, &rf);清除当前运行进程task_struct中的重调度标志TIF_NEED_RESCHED:
clear_tsk_need_resched(prev);
clear_preempt_need_resched();并不是必须选择一个新进程,也可能其他进程都在睡眠,当前只有一个进程能够运行,这样当前进程就被留在CPU上。如果已经选择了一个新进程,那么必须准备并执行硬件级的进程切换,其中context_switch接口供访问特定于体系结构的方法,后者负责执行底层上下文切换,调用顺序依次为:context_switch->switch_to->__switch_to,《栈指针sp与进程切换》一文中有说明体系结构的调用内容。
if (likely(prev != next)) {
rq->nr_switches++;
/*
* RCU users of rcu_dereference(rq->curr) may not see
* changes to task_struct made by pick_next_task().
*/
RCU_INIT_POINTER(rq->curr, next);
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
* rq->curr, before returning to user-space.
*
* Here are the schemes providing that barrier on the
* various architectures:
* - mm ? switch_mm() : mmdrop() for x86, s390, sparc, PowerPC.
* switch_mm() rely on membarrier_arch_switch_mm() on PowerPC.
* - finish_lock_switch() for weakly-ordered
* architectures where spin_unlock is a full barrier,
* - switch_to() for arm64 (weakly-ordered, spin_unlock
* is a RELEASE barrier),
*/
++*switch_count;
psi_sched_switch(prev, next, !task_on_rq_queued(prev));
trace_sched_switch(preempt, prev, next);
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
}(3)与fork的交互
每当使用fork/clone系统调用或其变体之一建立新进程时,调度器有机会用sched_fork函数挂钩到该进程。主要任务:设置优先级,设置符合权重,设置调度类。
通过使用父进程的普通优先级作为子进程的动态优先级,内核确保父进程优先级的临时提高不会被子进程继承。
/*
* fork()/clone()-time setup:
*/
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
trace_android_rvh_sched_fork(p);
__sched_fork(clone_flags, p);
/*
* We mark the process as NEW here. This guarantees that
* nobody will actually run it, and a signal or other external
* event cannot wake it up and insert it on the runqueue either.
*/
p->state = TASK_NEW;
/*
* Make sure we do not leak PI boosting priority to the child.
*/
p->prio = current->normal_prio;
trace_android_rvh_prepare_prio_fork(p);
uclamp_fork(p);
/*
* Revert to default priority/policy on fork if requested.
*/
if (unlikely(p->sched_reset_on_fork)) {
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {
p->policy = SCHED_NORMAL;
p->static_prio = NICE_TO_PRIO(0);
p->rt_priority = 0;
} else if (PRIO_TO_NICE(p->static_prio) < 0)
p->static_prio = NICE_TO_PRIO(0);
p->prio = p->normal_prio = p->static_prio;
set_load_weight(p, false);
/*
* We don't need the reset flag anymore after the fork. It has
* fulfilled its duty:
*/
p->sched_reset_on_fork = 0;
}
if (dl_prio(p->prio))
return -EAGAIN;
else if (rt_prio(p->prio))
p->sched_class = &rt_sched_class;
else
p->sched_class = &fair_sched_class;
init_entity_runnable_average(&p->se);
trace_android_rvh_finish_prio_fork(p);
#ifdef CONFIG_SCHED_INFO
if (likely(sched_info_on()))
memset(&p->sched_info, 0, sizeof(p->sched_info));
#endif
#if defined(CONFIG_SMP)
p->on_cpu = 0;
#endif
init_task_preempt_count(p);
#ifdef CONFIG_SMP
plist_node_init(&p->pushable_tasks, MAX_PRIO);
RB_CLEAR_NODE(&p->pushable_dl_tasks);
#endif
return 0;
}fork/clone与调度器之间的调用顺序:
pid_t kernel_clone(struct kernel_clone_args *args)
{
copy_process()
--> sched_fork()
wake_up_new_task()
Wake_up_new_task—第一次唤醒新创建的任务。
该函数将为每个新创建的上下文执行一些初始调度器统计整理,然后将任务放在就绪队列中并唤醒它。
}(4)上下文切换
内核选择新进程之后,必须处理与多任务相关的技术细节,这些细节总称为上下文切换。辅助函数context_switch是个分配器,它会调用所需的特定于体系结构的方法。
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
prepare_task_switch(rq, prev, next);
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
/*
* kernel -> kernel lazy + transfer active
* user -> kernel lazy + mmgrab() active
*
* kernel -> user switch + mmdrop() active
* user -> user switch
*/
if (!next->mm) { // to kernel
enter_lazy_tlb(prev->active_mm, next);
next->active_mm = prev->active_mm;
if (prev->mm) // from user
mmgrab(prev->active_mm);
else
prev->active_mm = NULL;
} else { // to user
membarrier_switch_mm(rq, prev->active_mm, next->mm);
/*
* sys_membarrier() requires an smp_mb() between setting
* rq->curr / membarrier_switch_mm() and returning to userspace.
*
* The below provides this either through switch_mm(), or in
* case 'prev->active_mm == next->mm' through
* finish_task_switch()'s mmdrop().
*/
switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // from kernel
/* will mmdrop() in finish_task_switch(). */
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
prepare_lock_switch(rq, next, rf);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
- prepare_task_switch为进程切换做准备,设置锁定并调用特定于体系结构的
prepare_arch_switch挂钩- 用户空间进程的寄存器内容在进入核心态时保存在内核栈上,因此在上下文切换期间无需显示操作。而因为每个进程首先都是从核心态开始执行,在返回用户空间时,会使用内核栈上保存的值自动恢复寄存器数据。重点:内核线程没有自身的用户空间上下文,可能在某个随机进程地址空间的上部执行。其task_struct->mm为NULL,task_struct->active_mm记录从当前进程“借来”的地址空间。根据此特性可区分用户空间或内核空间。
- 如果 next 是内核空间任务,调用 enter_lazy_tlb() 进行懒惰TLB加速行下文切换(通知底层体系结构不需要切换虚拟地址空间的用户空间部分),同时将 next 的 active_mm 设置为 prev 的 active_mm。如果前一进程prev是内核线程(prev->mm为NULL),则其actice_mm指针必须重置为NULL以断开与借用的地址空间的联系(kernel -> kernel),否则调用mmgrab接口增加prev->active_mm的引用计数(user -> kernel)
- 如果 next 是用户空间任务,则需要进行内存空间切换。switch_mm_irqs_off即switch_mm宏调用,更换通过task_struct->mm描述的内存管理上下文。主要功能包括加载页表,刷出地址转后备缓冲器,向内存管理单元(MMU)提供新的信息。如果 前一进程任务prev 属于内核空间,将 prev 的 active_mm 设置为 NULL,同时设置就绪队rq->prev_mm值为prev->active_mm。释放引用计数在finish_task_switch中处理(kernel -> user)
prepare_lock_switch为将要到来的进程切换释放就绪队列相关锁
switch_to进程切换,该函数切换处理寄存器内容和内核栈。新进程在该调用之后开始执行。
finish_task_switch完成一些清理工作
switch_to复杂之处:
通过上述介绍可知当switch_to调用之后,后续代码由新进程接管,即运行finish_task_switch的是切换后的新进程,而finish_task_switch需要的清理工作则是针对之前运行的进程,内核为了使新进程与context_switch能够通信,需要提供一种方法。
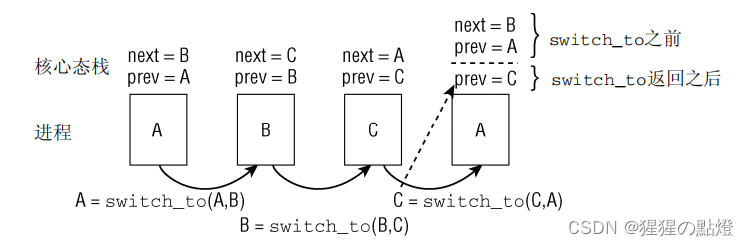
如上图所示,当ABC三个进程依次按照A->B,B->C,C->A顺序切换,prev表示当前进程,next表示下一个进程。当控制权重新回到next=B,prev=A时,内核无法知道实际上在进程A之前运行的是进程C。因此在新进程被选中时,底层的进程切换例程必须将此前执行的进程提供给context_switch,由于控制流会回到该函数的中间,无法用普通函数返回值做到,因此使用了一个3个参数的宏来实现。
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
#endif /* __ASM_GENERIC_SWITCH_TO_H */
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
...
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
















 1930
1930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









