




一、《OVTrack: Open-Vocabulary Multiple Object Tracking》
作者:Siyuan Li* Tobias Fischer* Lei Ke Henghui Ding Martin Danelljan Fisher Yu
Computer Vision Lab, ETH Zurich
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Li_OVTrack_Open-Vocabulary_Multiple_Object_Tracking_CVPR_2023_paper.pdf
Github:https://github.com/SysCV/ovtrack
1、摘要
识别、定位和跟踪场景中的动态物体的能力是许多现实世界的应用程序的基础,如自动驾驶和机器人系统。然而,传统的多重对象跟踪(MOT)基准测试只依赖于少数对象类别,这些类别很难代表在现实世界中遇到的大量可能的对象。这使得当代的MOT方法仅限于一组预定义的对象类别。在本文中,我们通过解决一个新的任务,即开放词汇表MOT来解决这一限制,该任务旨在评估在预定义的训练类别之外的跟踪。我们进一步开发了OVTrack,这是一个能够跟踪任意对象类的开放词汇表跟踪器。它的设计基于两个关键成分:第一,利用视觉语言模型通过知识蒸馏进行分类和关联;第二,一种数据幻想策略,从去噪扩散概率模型中进行鲁棒外观特征学习。其结果是一个非常数据高效的开放词汇量跟踪器,它在静态图像上进行训练就在大规模的、大词汇量的TAO基准测试上达到SOTA。
2、方法
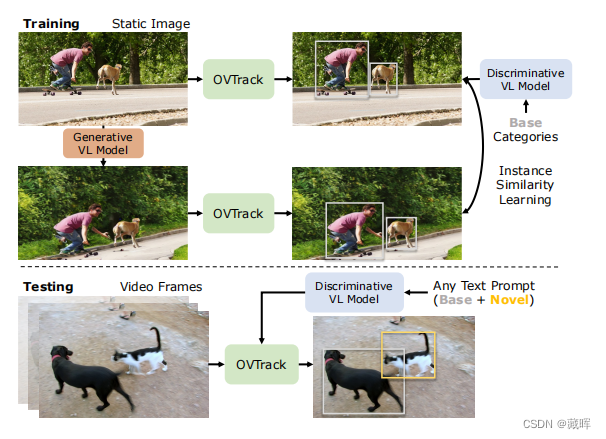
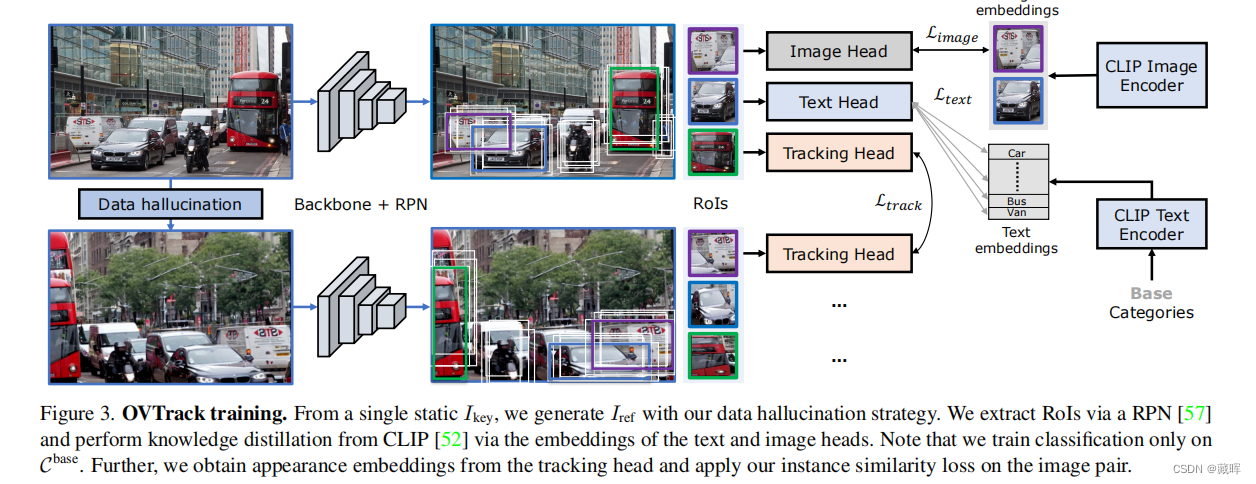
简单来说,本文通过大模型的能力来替代掉原来的Tracking不可知目标分类的能力。对于跟随未知物体,需要跟踪器可以做的事请有三件,一是定位物体的位置,文中用了Faster RCNN在类不可知的方式下进行训练(先前的方法,可见前两年的总结)。二是关联,作者用了一种数据增强方式,用一种图来促进外观embedding的学习,并用其做关联。三是分类,告诉用户现在在跟随的目标类别。这篇paper将传统的分类任务改变为Image Captioning的任务,通过蒸馏大模型CLIP来获得Image到Text的解读能力。

在Inference阶段,也用到了CLIP。OVTrack通过比较embedding的相似性获得相邻帧的匹配结果以及类别。
二、《MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking》
作者:Zheng Qin1† Sanping Zhou1† Le Wang1∗
Jinghai Duan2 Gang Hua3 Wei Tang4
1National Key Laboratory of Human-Machine Hybrid Augmented Intelligence,
National Engineering Research Center for Visual Information and Applications,
Institute of Artificial Intelligence and Robotics, Xi’an Jiaotong University
2School of Software Engineering, Xi’an Jiaotong University
3Wormpex AI Research 4University of Illinois at Chicago
论文链接 :https://openaccess.thecvf.com/content/CVPR2023/papers/Qin_MotionTrack_Learning_Robust_Short-Term_and_Long-Term_Motions_for_Multi-Object_Tracking_CVPR_2023_paper.pdf
Github:https://github.com/qwomeng/MotionTrack
1、摘要
多目标跟踪(MOT)的主要挑战在于为每个目标保持一个连续的轨迹。现有的方法通常是学习可靠的运动模式,以匹配相邻帧之间的相同目标和有区别的外观特征,以在长时间后重新识别丢失的目标。然而,在跟踪过程中,密集的人群和极端的遮挡很容易受到运动预测的可靠性和外观的影响。在本文中,我们提出了一种简单而有效的多目标跟踪器,即运动跟踪器,它在一个统一的框架中学习鲁棒的短期和长期运动,从而将从短期到长期的轨迹关联起来。对于密集的人群,我们设计了一个新的交互模块,从短期轨迹中学习交互感知运动,它可以估计每个目标的复杂运动。对于极端遮挡,我们建立了一个新的重寻模块,从目标的历史轨迹中学习可靠的长期运动,它可以将中断的轨迹与相应的检测联系起来。我们的交互模块和重寻模块嵌入在众所周知的Tracking-by-detection范式中,它可以协同工作以保持优越的性能。
🔺这篇paper主要是基于ByteTrack的改进,用网络来强化其运动预测。
2、方法
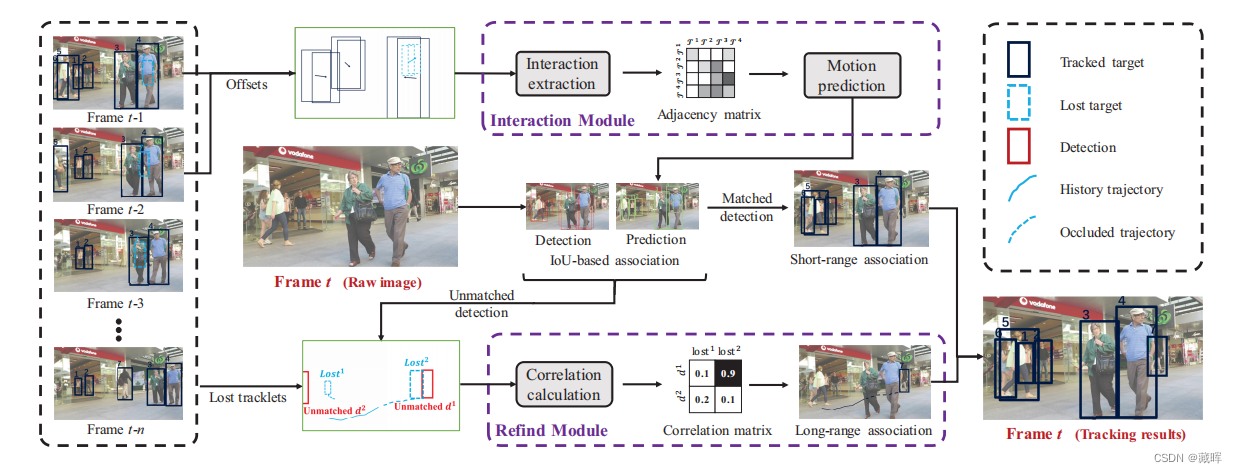
文中主要有两个模块,一个用于短时运动轨迹估计的Interaction Module,通过预测每一个目标的短时的运动轨迹,并和当前帧的detection结果做匹配。另一个是长时的Refind Moudule,通过一些方法补偿由于目标遮挡所不可见目标的运动轨迹,并找回他们。
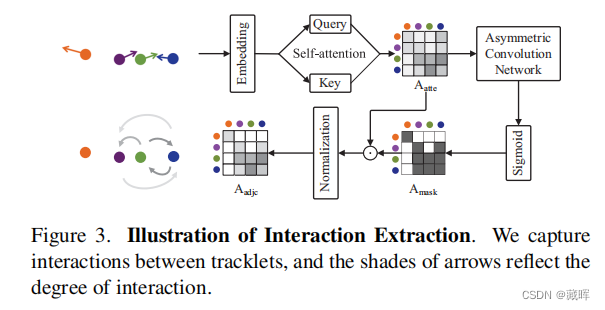
Interaction model将目标的绝对坐标和偏移量作为输入,表示为It∈R^(M×8)。将其embedding化后计算轨迹之间的相互影响,即相互作用矩阵Aadjc。这个矩阵的作用是将其他影响到的该目标轨迹的目标的偏移量,用来做加权,以提高偏移量预测的精度。跨帧的关联还是用了IOU。
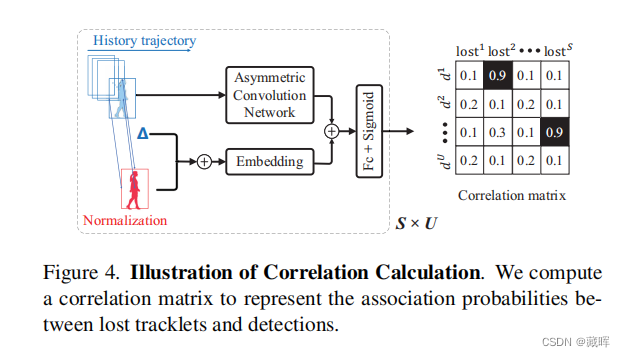
Refind module将lost tracklet和当前帧未匹配的box进行编码,之后通过一个全连接层来计算其相关性,以获得找回结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









