




 Apache Beam编程指南介绍了如何使用Beam SDK创建数据处理流水线。它涵盖了Pipeline、PCollection、PTransform和窗口等核心概念,提供了从数据源读取、转换、分组、聚合等操作的指导。文章强调了PCollection的不变性和有界与无界数据集的处理方式,并讨论了窗口和触发器在处理无界数据流时的重要性。
Apache Beam编程指南介绍了如何使用Beam SDK创建数据处理流水线。它涵盖了Pipeline、PCollection、PTransform和窗口等核心概念,提供了从数据源读取、转换、分组、聚合等操作的指导。文章强调了PCollection的不变性和有界与无界数据集的处理方式,并讨论了窗口和触发器在处理无界数据流时的重要性。
指南
Beam Programming Guide适用于希望使用Beam SDK创建数据处理流水线的Beam用户。 它为使用Beam SDK类构建和测试管道提供了指导。 它不是一个详尽的参考,而是作为一种语言无关的高级指南,以编程方式构建您的Beam管道。
概述
要使用Beam,您需要首先使用其中一个Beam SDK中的类创建驱动程序。 您的驱动程序定义了您的管道,包括所有输入,转换和输出; 它还为您的管道设置执行选项(通常使用命令行选项传递)。 其中包括Pipeline Runner,它反过来确定您的管道将在哪个后端运行。
Beam SDK提供了许多抽象,简化了大规模分布式数据处理的机制。 相同的Beam抽象适用于批处理和流数据源。 创建Beam管道时,您可以根据这些抽象来考虑数据处理任务。 他们包括:
- Pipeline:管道从头到尾封装整个数据处理任务。这包括读取输入数据,转换数据和写入输出数据。所有Beam驱动程序都必须创建管道。创建管道时,还必须指定执行选项,以告知管道在何处以及如何运行。
- PCollection:PCollection表示Beam管道操作的分布式数据集。数据集可以是有界的,这意味着它来自固定的源,如文件,或无限制,这意味着它来自通过订阅或其他机制不断更新的源。您的管道通常通过从外部数据源读取数据来创建初始PCollection,但您也可以从驱动程序中的内存数据创建PCollection。从那里,PCollections是管道中每个步骤的输入和输出。
- PTransform:PTransform表示管道中的数据处理操作或步骤。每个PTransform都将一个或多个PCollection对象作为输入,执行您在该PCollection的元素上提供的处理函数,并生成零个或多个输出PCollection对象。
- I / O转换:Beam带有许多“IO” - 库PTransforms可以读取或写入各种外部存储系统的数据。
典型的Beam驱动程序的工作原理如下:
- 创建Pipeline对象并设置管道执行选项,包括Pipeline Runner。
- 为管道数据创建初始PCollection,使用IO从外部存储系统读取数据,或使用Create转换从内存数据构建PCollection。
- 将PTransforms应用于每个PCollection。变换可以更改,过滤,分组,分析或以其他方式处理PCollection中的元素。转换创建新的输出PCollection而不修改输入集合。典型的管道依次将后续变换应用于每个新输出PCollection直到处理完成。但是,请注意,管道不必是一个接一个地应用的单个直线变换:将PCollections视为变量,将PTransforms视为应用于这些变量的函数:管道的形状可以是任意复杂的处理图形。
- 使用IO将最终的转换后的PCollection写入外部源。
- 使用指定的Pipeline Runner运行管道。
运行Beam驱动程序时,您指定的Pipeline Runner会根据您创建的PCollection对象构建管道的工作流图,并转换您已应用的对象。然后使用适当的分布式处理后端执行该图,在该后端成为异步“作业”(或等效的)
创建Pipeline
Pipeline抽象封装了数据处理任务中的所有数据和步骤。 您的Beam驱动程序通常首先构建一个对象,然后使用该对象作为创建管道数据集的基础,如PCollections及其作为Transforms的操作。
要使用Beam,您的驱动程序必须首先创建Beam SDK类Pipeline的实例(通常在main()函数中)。 创建管道时,还需要设置一些配置选项。 您可以以编程方式设置管道的配置选项,但通常更容易提前设置选项(或从命令行读取它们),并在创建对象时将它们传递给Pipeline对象。
// In order to start creating the pipeline for execution, a Pipeline object and a Scope object are needed.
p, s := beam.NewPipelineWithRoot()
配置管道选项
使用管道选项配置管道的不同方面,例如将执行管道的管道运行程序以及所选运行程序所需的任何运行程序特定的配置。您的管道选项可能包含诸如项目ID或存储文件的位置之类的信息。
在您选择的运行器上运行管道时,您的代码将可以使用PipelineOptions的副本。例如,如果将一个PipelineOptions参数添加到DoFn的@ProcessElement方法,它将由系统填充。
从命令行参数设置PipelineOptions
虽然您可以通过创建PipelineOptions对象并直接设置字段来配置管道,但Beam SDK包含一个命令行解析器,您可以使用该命令行解析器使用命令行参数在PipelineOptions中设置字段。
要从命令行读取选项,请构造PipelineOptions对象,如以下示例代码所示:
// If beamx or Go flags are used, flags must be parsed first.
flag.Parse()这解释了遵循以下格式的命令行参数:
--<option>=<value> - <选项> = <值>注意:附加方法.withValidation将检查所需的命令行参数并验证参数值。
以这种方式构建PipelineOptions允许您将任何选项指定为命令行参数。
注意:WordCount example pipeline示例管道演示了如何使用命令行选项在运行时设置管道选项。
创建自定义选项
除标准PipelineOptions外,您还可以添加自己的自定义选项。 要添加自己的选项,请为每个选项定义具有getter和setter方法的接口,如以下示例所示:
var (
input = flag.String("input", "", "")
output = flag.String("output", "", "")
)您还可以指定描述,该描述在用户将--help作为命令行参数传递时显示,并显示默认值。
您可以使用注释设置描述和默认值,如下所示:
var (
input = flag.String("input", "gs://my-bucket/input", "File(s) to read.")
output = flag.String("output", "gs://my-bucket/output", "Output file.")
)现在您的管道可以接受--myCustomOption = value作为命令行参数。
PCollections
抽象表示潜在分布的多元素数据集。 您可以将PCollection视为“管道”数据; Beam变换使用PCollection对象作为输入和输出。 因此,如果要处理管道中的数据,则必须采用PCollection的形式。
在创建管道之后,您需要首先以某种形式创建至少一个PCollection。 您创建的PCollection用作管道中第一个操作的输入。
创建PCollection
您可以通过使用Beam的Source API从外部源读取数据来创建PCollection,也可以在驱动程序中创建存储在内存中集合类中的数据的PCollection。 前者通常是生产管道如何获取数据; Beam的Source API包含适配器,可帮助您从外部源读取大型基于云的文件,数据库或订阅服务。 后者主要用于测试和调试目的。
从外部来源阅读
要从外部源读取,请使用Beam提供的I / O适配器之一。 适配器的确切用法各不相同,但它们都从一些外部数据源读取并返回一个PCollection,其元素代表该源中的数据记录。
每个数据源适配器都有一个Read变换; 要阅读,您必须将该变换应用于Pipeline对象本身。 例如,从外部文本文件读取并返回其元素为String类型的PCollection,每个String表示文本文件中的一行。 以下是您应用于管道创建PCollection的方法:
lines := textio.Read(s, "protocol://path/to/some/inputData.txt")请参阅有关I / O的部分,以了解有关如何从Beam SDK支持的各种数据源进行读取的更多信息。
从内存数据创建PCollection
以下示例代码显示如何从内存中创建PCollection:
counted := CountWords(s, lines)PCollection特性
PCollection由为其创建的特定Pipeline对象拥有; 多个管道无法共享PCollection。 在某些方面,PCollection的功能类似于集合类。 但是,PCollection可以在几个关键方面有所不同:
元素类型
PCollection的元素可以是任何类型,但必须都是相同的类型。 但是,为了支持分布式处理,Beam需要能够将每个单独的元素编码为字节串(因此元素可以传递给分布式工作者)。 Beam SDK提供了一种数据编码机制,包括常用类型的内置编码,以及支持根据需要指定自定义编码。
不变性
PCollection是不可变的。 创建后,您无法添加,删除或更改单个元素。 Beam Transform可以处理PCollection的每个元素并生成新的管道数据(作为新的PCollection),但它不会消耗或修改原始输入集合。
随机访问
PCollection不支持对单个元素的随机访问。相反,Beam Transforms会单独考虑PCollection中的每个元素。
大小和有界
PCollection是一个庞大的,不可改变的“包”元素。 PCollection可以包含的元素数量没有上限;任何给定的PCollection可能适合单个机器上的内存,或者它可能代表由持久数据存储支持的非常大的分布式数据集.
PCollection的大小可以是有界的,也可以是无界的。有界PCollection表示已知固定大小的数据集,而无界PCollection表示无限大小的数据集。 PCollection是有界还是无界取决于它所代表的数据集的来源。从批处理数据源(例如文件或数据库)读取会创建有界PCollection。从流式传输或不断更新的数据源(如Pub / Sub或Kafka)中读取,会创建一个无界的PCollection(除非您明确告诉它不要)。
PCollection的有界(或无界)性质会影响Beam处理数据的方式。可以使用批处理作业处理有界PCollection,批处理作业可以读取整个数据集一次,并在有限长度的作业中执行处理。必须使用连续运行的流式作业处理无界PCollection,因为整个集合在任何时候都无法进行处理。
Beam使用窗口将连续更新的无界PCollection划分为有限大小的逻辑窗口。这些逻辑窗口由与数据元素相关联的某些特征确定,例如时间戳。聚合转换(例如GroupByKey和Combine)基于每个窗口工作 - 当生成数据集时,它们将每个PCollection作为这些有限窗口的连续处理。
元素时间戳
PCollection中的每个元素都有一个关联的固有时间戳。每个元素的时间戳最初由创建PCollection的Source分配。创建无界PCollection的源通常会为每个新元素分配一个时间戳,该时间戳对应于读取或添加元素的时间。
注意:为固定数据集创建有界PCollection的源也会自动分配时间戳,但最常见的行为是为每个元素分配相同的时间戳(Long.MIN_VALUE)。
时间戳对于包含具有固有时间概念的元素的PCollection非常有用。如果您的管道正在读取事件流(如推文或其他社交媒体消息),则每个元素可能会使用事件发布的时间作为元素时间戳。
如果源不为您执行此操作,您可以手动将时间戳分配给PCollection的元素。如果元素具有固有的时间戳,则需要执行此操作,但时间戳位于元素本身的结构中(例如服务器日志条目中的“time”字段)。 Beam具有将PCollection作为输入的变换,并输出附加了时间戳的相同PCollection;有关如何执行此操作的详细信息,请参阅Adding Timestamps。
Transforms
Transforms是管道中的操作,并提供通用的处理框架。您以函数对象的形式提供处理逻辑(通俗地称为“用户代码”),并且您的用户代码应用于输入PCollection(或多个PCollection)的每个元素。根据您选择的管道运行程序和后端,群集中的许多不同工作程序可以并行执行用户代码的实例。在每个worker上运行的用户代码生成输出元素,这些元素最终被添加到转换产生的最终输出PCollection中。
Beam SDK包含许多不同的变换,您可以将这些变换应用于管道的PCollections。这些包括通用核心转换,例如ParDo或Combine。 SDK中还包含预先编写的复合变换,它们以一种有用的处理模式组合一个或多个核心变换,例如计算或组合集合中的元素。您还可以定义自己更复杂的复合变换,以适应管道的确切用例。
应用变换
要调用转换,必须将其应用于输入PCollection。 Beam SDK中的每个变换都有一个通用的apply方法。调用多个Beam变换类似于方法链接,但略有不同:将变换应用于输入PCollection,将变换本身作为参数传递,操作返回输出PCollection。这采取一般形式:
因为Beam对PCollection使用通用的apply方法,所以您既可以顺序链变换,也可以应用包含嵌套在其中的其他变换的变换(在Beam SDK中称为复合变换)。
如何应用管道的转换决定了管道的结构。考虑管道的最佳方法是作为有向非循环图,其中节点是PCollections,边是变换。例如,您可以链变换以创建顺序管道,如下所示:
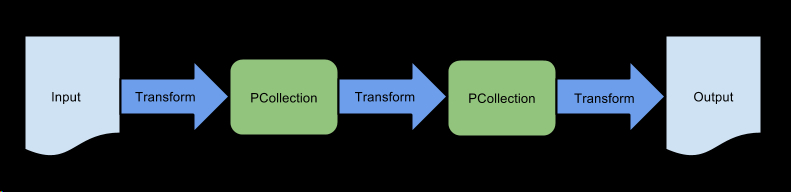
图:具有三个顺序变换的线性流水线。
但是,请注意,转换不会消耗或以其他方式更改输入集合 - 请记住,PCollection根据定义是不可变的。 这意味着您可以将多个转换应用于相同的输入PCollection以创建分支管道,如下所示:
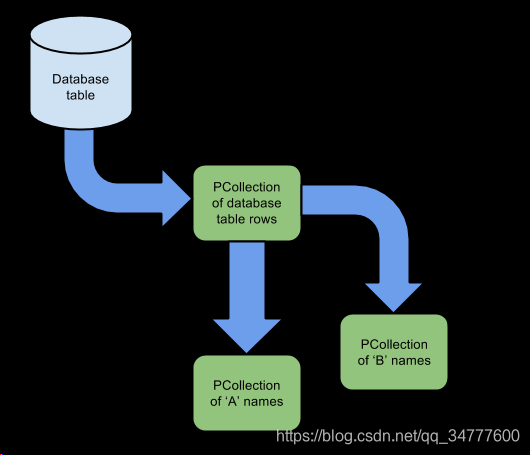
图:分支管道。 两个转换应用于数据库表行的单个PCollection。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









