




 本文总结了双向BFS和Meet in the Middle算法。双向BFS在限定步数问题中能显著减少搜索状态数,如POJ1198中,通过双向BFS将状态数从168降至69632。Meet in the Middle是深搜技巧,通过分治降低枚举复杂度,如在POJ1903中应用。实施时需注意状态同步和合并效率。
本文总结了双向BFS和Meet in the Middle算法。双向BFS在限定步数问题中能显著减少搜索状态数,如POJ1198中,通过双向BFS将状态数从168降至69632。Meet in the Middle是深搜技巧,通过分治降低枚举复杂度,如在POJ1903中应用。实施时需注意状态同步和合并效率。
前言:
尽管搜索题在难度高的比赛中都不是重要考点,但作为骗分的一大技巧,无论多强的选手,都仍然无法忽视搜索的重要性。并且,有些高难度比赛中,一些带一定技巧的搜索题,很有可能会放在签到题的位置上。这些题全场都会做,但正因如此,所有人都会毫不犹豫地先写这道题,如果在这道题上花的时间过多,对后面的难题将造成不可估量的影响。
总之,练好搜索是绝对必要的。
双向BFS
传统的BFS是从起点出发,一直搜到终点为止,而双向BFS则是从起点和终点同时出发,搜到两者的某些状态相遇为止。
在一些限定行走步数的问题中,双向BFS往往是非常有效的一种方式。
例如:POJ1198Solitaire
这道题中,要求最多走8步,考虑每一步可以转移的情况,总共有16种,总的状态数就会有168=4294967296168=4294967296种(当然,这道题中,由于棋盘的限制,最多应该仅有644=16777216644=16777216种,不过仍然无法支持),这明显是不可能做到的,但如果考虑双向BFS,那么一边最多走4步,另一边最多走3步,总的情况数就降为164+163=69632164+163=69632种,这就相当可做了。
另一种方式理解双向BFS的优越性,可以画一个图来表示
假设S是初始状态,T是终止状态,如果普通BFS,其搜索范围为圆S的面积。
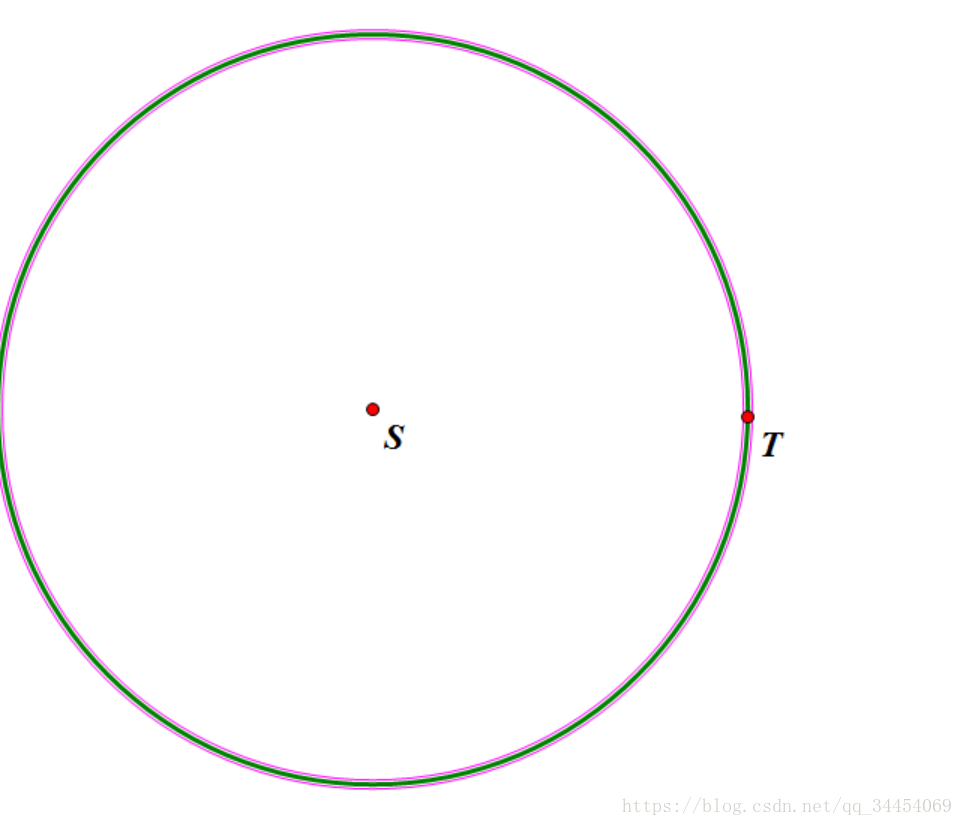
而如果使用双向BFS,搜索的范围则变为了:
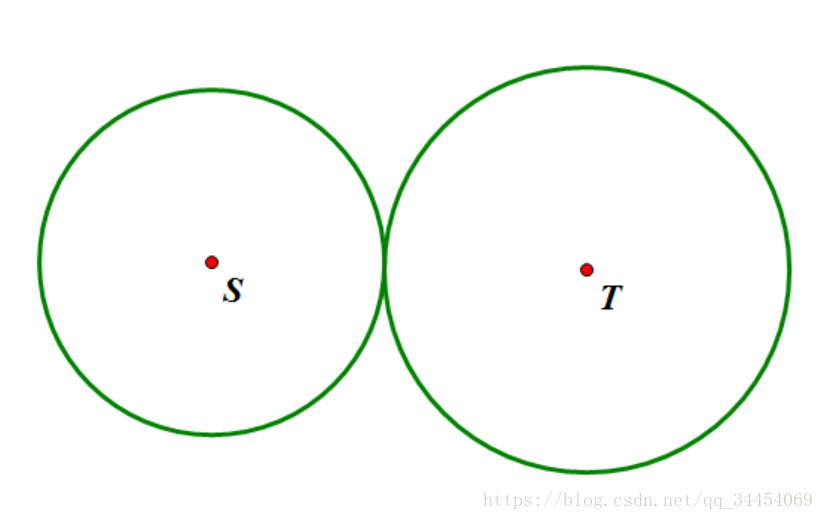
实现时有些要注意的:
1、初始状态可能与目标状态重合,要特判
2、前半状态与后半状态之间的连接还需要一步,所以如果拆8步需要拆成4步+3步,而不能是4步+4步
3、两种状态要同步进行,不需要先搞从s出发,再搞从t出发,只需要用标记存储当前状态的来源即可。
Meet in the Middle
这是一种深搜的重要技巧,通过减半枚举量,再将两部分答案组合起来,以达到降低复杂度的目的。
比较经典的题是POJ1903
通过枚举前半部分的选择状态,以及后半部分的选择状态,我们的枚举量大大降低(从240变为2∗220240变为2∗220)
注意事项:
1、这个算法有个很大的局限,在于中间合并两部分状态时,有可能需要n2n2的复杂度,这样会使算法效率退化。一定要优化这里的合并,或者用其他方式定义状态。
2、一般来说,我们不会把两部分的状态都存下来(少数例外),常规做法是:暴力枚举左半部分后,将左半部分信息存储,在暴力枚举右半部分时,直接在左半部分的信息中筛选即可。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









