







 本文介绍使用神经网络进行手写数字识别的过程,包括数据集的加载与理解、神经网络的设计与实现,以及通过反向传播算法进行权重更新。
本文介绍使用神经网络进行手写数字识别的过程,包括数据集的加载与理解、神经网络的设计与实现,以及通过反向传播算法进行权重更新。
神经网络学习(二)
手写数字识别
认识数据集
from sklearn.datasets import load_digits #导入手写数字数据集
digits = load_digits()
print(digits.keys())
dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])
print(digits.data)
print(digits.data.shape)
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[ 0. 0. 1. ... 6. 0. 0.]
[ 0. 0. 2. ... 12. 0. 0.]
[ 0. 0. 10. ... 12. 1. 0.]]
(1797, 64)
#数据里面存储了图片的所有信息,一共有1797张图面,每张图面有64个像素点
print(digits.target)
print(digits.target.shape)
[0 1 2 ... 8 9 8]
(1797,)
#从标签可以看出数据的范围是从0-9
print(digits.images)
print(digits.images.shape)
[[[ 0. 0. 5. ... 1. 0. 0.]
[ 0. 0. 13. ... 15. 5. 0.]
[ 0. 3. 15. ... 11. 8. 0.]
...
[ 0. 4. 16. ... 16. 6. 0.]
[ 0. 8. 16. ... 16. 8. 0.]
[ 0. 1. 8. ... 12. 1. 0.]]]
(1797, 8, 8)
#图像信息时8*8的矩阵存储的
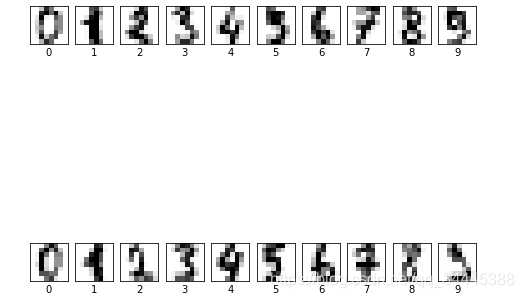
数据集图像显示
import matplotlib.pyplot as plt
plt.figure(figsize=(8,8))
for i in range(20):
plt.subplot(2,10,i+1) #图片是2*10的 参数(行数,列数,当前图片的序号)
plt.imshow(digits.images[i],cmap="Greys")
plt.xlabel(digits.target[i])
plt.xticks([])
plt.yticks([]) #去掉坐标轴
plt.show()
神经网络设计
网络结构
整个神经网络分为3层,由于图像的像素是64,所以输入节点一共64个,隐藏层设计为100个,输出一共有10种情况,所以设计为10个。
即网络结构为64 x 100 x10
激活函数
S
(
x
)
=
1
1
+
e
−
x
S(x)=\frac{1}{1+e^{-x}}
S(x)=1+e−x1
S
′
(
x
)
=
S
(
x
)
⋅
(
1
−
S
(
x
)
)
S'(x)=S(x) \cdot (1-S(x))
S′(x)=S(x)⋅(1−S(x))
反向传播更新公式
α
\alpha
α:为学习步长
ω
2
\bm{\omega}^{2}
ω2:输入层神经网络权重
ω
3
\bm{\omega}^{3}
ω3:隐藏层神经网路权重
隐藏层参数更新:
δ
(
3
)
=
−
(
y
−
a
(
3
)
)
⊙
f
′
(
z
(
3
)
)
=
−
(
y
−
a
(
3
)
)
⊙
S
(
z
(
3
)
)
(
1
−
S
(
z
(
3
)
)
)
∇
ω
3
E
=
δ
(
3
)
(
a
(
2
)
)
T
ω
3
=
ω
3
−
α
∇
ω
3
E
\begin{aligned} \bm{\delta}^{(3)} &=-(\bm{y}-\bm{a}^{(3)}) \odot f'(\bm{z}^{(3)}) \\ &=-(\bm{y}-\bm{a}^{(3)}) \odot S(\bm{z}^{(3)})(1-S(\bm{z}^{(3)})) \\ \nabla_{\bm{\omega}^{3}}E &= \bm{\delta}^{(3)}(\bm{a}^{(2)})^\text{T} \\ \bm{\omega}^{3} &= \bm{\omega}^{3} - \alpha \nabla_{\bm{\omega}^{3}}E \end{aligned}
δ(3)∇ω3Eω3=−(y−a(3))⊙f′(z(3))=−(y−a(3))⊙S(z(3))(1−S(z(3)))=δ(3)(a(2))T=ω3−α∇ω3E
输入层参数更新:
δ
(
2
)
=
(
(
ω
3
)
T
δ
3
)
⊙
S
′
(
z
(
2
)
)
∇
ω
2
E
=
δ
(
2
)
(
x
)
T
ω
2
=
ω
2
−
α
∇
ω
2
E
\begin{aligned} \bm{\delta}^{(2)} &= \left( (\bm{\omega}^{3})^{\text{T}}\bm{\delta}^{3} \right)\odot S'(\bm{z}^{(2)}) \\ \nabla_{\bm{\omega}^{2}}E &= \bm{\delta}^{(2)}(\bm{x})^\text{T} \\ \bm{\omega}^{2} &= \bm{\omega}^{2} - \alpha \nabla_{\bm{\omega}^{2}}E \end{aligned}
δ(2)∇ω2Eω2=((ω3)Tδ3)⊙S′(z(2))=δ(2)(x)T=ω2−α∇ω2E
实例程序
L1对应
a
(
2
)
a^{(2)}
a(2)
L2对应
a
(
3
)
a^{(3)}
a(3)
V对应
ω
2
\bm{\omega}^{2}
ω2
W对应
ω
3
\bm{\omega}^{3}
ω3
L1_delta对应
δ
(
2
)
\bm{\delta}^{(2)}
δ(2)
L2_delta对应
δ
(
3
)
\bm{\delta}^{(3)}
δ(3)
import numpy as np
from sklearn.datasets import load_digits #导入手写数字数据集
from sklearn.preprocessing import LabelBinarizer # 标签二值化
from sklearn.model_selection import train_test_split # 切割数据,交叉验证法
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def dsigmoid(x):
return x * (1 - x)
class NeuralNetwork:
def __init__(self, layers): # (64,100,10)
# 权重的初始化,范围-1到1:+1的一列是偏置值
self.V = np.random.random((layers[0] + 1, layers[1] + 1)) * 2 - 1
self.W = np.random.random((layers[1] + 1, layers[2])) * 2 - 1
def train(self, X, y, lr=0.11, epochs=10000):
# 添加偏置值:最后一列全是1
temp = np.ones([X.shape[0], X.shape[1] + 1])
temp[:, 0:-1] = X
X = temp
for n in range(epochs + 1):
# 在训练集中随机选取一行(一个数据):randint()在范围内随机生成一个int类型
i = np.random.randint(X.shape[0])
x = [X[i]]
# 转为二维数据:由一维一行转为二维一行
x = np.atleast_2d(x)
# L1:输入层传递给隐藏层的值;输入层64个节点,隐藏层100个节点
# L2:隐藏层传递到输出层的值;输出层10个节点
L1 = sigmoid(np.dot(x, self.V))
L2 = sigmoid(np.dot(L1, self.W))
# L2_delta:输出层对隐藏层的误差改变量
# L1_delta:隐藏层对输入层的误差改变量
L2_delta = (y[i] - L2) * dsigmoid(L2)
L1_delta = L2_delta.dot(self.W.T) * dsigmoid(L1)
# 计算改变后的新权重
self.W += lr * L1.T.dot(L2_delta)
self.V += lr * x.T.dot(L1_delta)
# 每训练1000次输出一次准确率
if n % 1000 == 0:
predictions = []
for j in range(X_test.shape[0]):
# 获取预测结果:返回与十个标签值逼近的距离,数值最大的选为本次的预测值
o = self.predict(X_test[j])
# 将最大的数值所对应的标签返回
predictions.append(np.argmax(o))
# np.equal():相同返回true,不同返回false
accuracy = np.mean(np.equal(predictions, y_test))
print('迭代次数:', n, '准确率:', accuracy)
def predict(self, x):
# 添加偏置值:最后一列全是1
temp = np.ones([x.shape[0] + 1])
temp[0:-1] = x
x = temp
# 转为二维数据:由一维一行转为二维一行
x = np.atleast_2d(x)
# L1:输入层传递给隐藏层的值;输入层64个节点,隐藏层100个节点
# L2:隐藏层传递到输出层的值;输出层10个节点
L1 = sigmoid(np.dot(x, self.V))
L2 = sigmoid(np.dot(L1, self.W))
return L2
# 载入数据:8*8的数据集
digits = load_digits()
print(digits.keys())
X = digits.data
Y = digits.target
# 输入数据归一化:当数据集数值过大,乘以较小的权重后还是很大的数,代入sigmoid激活函数就趋近于1,不利于学习
X -= X.min()
X /= X.max()
NN = NeuralNetwork([64, 100, 10])
# sklearn切分数据
X_train, X_test, y_train, y_test = train_test_split(X, Y)
# 标签二值化:将原始标签(十进制)转为新标签(二进制)
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
print('开始训练')
NN.train(X_train, labels_train, epochs=20000)
print('训练结束')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









