



 本文深入探讨Scala中的操作符本质,指出在Scala中操作符实际上是方法。讲解了前缀、中缀和后缀操作符的用法,以及操作符的优先级和结合性。同时,提到了预设操作符和对象的相等性,强调了“操作符即方法”对于构建DSL语言的重要性。
本文深入探讨Scala中的操作符本质,指出在Scala中操作符实际上是方法。讲解了前缀、中缀和后缀操作符的用法,以及操作符的优先级和结合性。同时,提到了预设操作符和对象的相等性,强调了“操作符即方法”对于构建DSL语言的重要性。
一、操作符在Scala里的解释
在诸如C++、Java等oop语言里,定义了像byte、short、int、char、float之类的基本类型,但是这些基本类型不属于面向对象的范畴。就好比C语言也有这些类型,但是C语言根本没有面向对象的概念。 比如只能说“1”是一个int类型的常量,却不能说它是一个int类型的对象。与之对应的,这些语言还定义了与基本类型相关的操作符。例如,有算术操作符加法“+”,它可以连接左、右两个操作数,然后算出相应的总和。
前面提到,Scala追求纯粹的面向对象,像这种不属于面向对象范畴的基本类型及其操作符都是有违宗旨的。那么,Scala如何实现这些基本类型呢?实际在Scala标准库里定义了“class Byte”、“class Short”、“class Char”、“class Int”、“class Long”、“class Float”、“class Double”、“class Boolean”和“class Unit”九种值类,只不过这些类是抽象的、不可继承的,因此不能通过“new Int”这种语句来构造一个Int对象,也不能编写它们的子类,它们的对象都是由字面量来表示。例如,整数字面量“1”就是一个Int的对象。在运行时,前八种值类会被转换成对应的Java基本类型。第九个Unit类对应Java的“void”类型,即表示空值,这样就能理解返回值类型为Unit的、有副作用的函数其实是空函数。Unit类的对象由一个空括号作为字面量来表示。
简而言之,Scala做到了真正的“万物皆对象”。
还有,与基本类型相关的操作符该如何处理呢?严格来讲,Scala并不存在操作符的概念,这些所谓的操作符,例如算术运算的加减乘除,逻辑运算的与或非,比较运算的大于小于等等,其实都是定义在“class Int”、“class Double”等类里的成员方法。也就是说,在Scala里,操作符即方法。例如,Int类定义了一个名为“+”的方法,那么表达式“1 + 2”的真正形式应该是“1.+(2)”。它的释义是:Int对象“1”调用了它的成员方法“+”,并把Int对象“2”当作参数传递给了该方法,最后这个方法会返回一个新的Int对象“3”。
推而广之,“操作符即方法”的概念不仅仅限于九种值类的操作符,Scala里任何类定义的成员方法都是操作符,而且方法调用都能写成操作符的形式:去掉句点符号,并且方法参数只有一个时可以省略圆括号。例如:
scala> class Students3(val name: String, var score: Int) {
| def exam(s: Int) = score = s
| def friends(n: String, s: Int) = println("My friend " + n + " gets " + s + ".")
| override def toString = name + "'s score is " + score + "."
| }
defined class Students3scala> val stu3 = new Students3("Alice", 80)
stu3: Students3 = Alice's score is 80.scala> stu3 exam 100
scala> stu3.score
res0: Int = 100scala> stu3 friends ("Bob", 70)
My friend Bob gets 70.
二、三种操作符
Ⅰ、前缀操作符
写在操作数前面的操作符称为前缀操作符,并且操作数只有一个。前缀操作符对应一个无参方法,操作数是调用该方法的对象。前缀操作符只有“+”、“-”、“!”和“~”四个,相对应的方法名分别是“unary_+”、“unary_-”、“unary_!”和“unary_~”。如果自定义的方法名是 “unary_”加上这四个操作符之外的操作符,那么就不能写成前缀操作符的形式。假设定义了方法“unary_*”,那么写成“*p”的形式让人误以为这是一个指针,实际Scala并不存在指针,因此只能写成“p.unary_*”或后缀操作符“p unary_*”的形式。例如:
scala> class MyInt(val x: Int) {
| def unary_! = -x
| def unary_* = x * 2
| }
defined class MyIntscala> val mi = new MyInt(10)
mi: MyInt = MyInt@2aac87abscala> !mi
res0: Int = -10scala> *mi
<console>:12: error: not found: value *
*mi
^
<console>:12: warning: postfix operator mi should be enabled
by making the implicit value scala.language.postfixOps visible.
This can be achieved by adding the import clause 'import scala.language.postfixOps'
or by setting the compiler option -language:postfixOps.
See the Scaladoc for value scala.language.postfixOps for a discussion
why the feature should be explicitly enabled.
*mi
^scala> mi.unary_*
res2: Int = 20
Ⅱ、中缀操作符
中缀操作符的左右两边都接收操作数,它对应普通的有参方法。两个操作数中的一个是调用该方法的对象,一个是传入该方法的参数,参数那一边没有数量限制,只是多个参数需要放在圆括号里。Scala规定,以冒号“ : ”结尾的操作符,其右操作数是调用该方法的对象,其余操作符都是把左操作数当调用该方法的对象。 例如:
scala> class MyInt2(val x: Int) {
| def +*(y: Int) = (x + y) * y
| def +:(y: Int) = x + y
| }
defined class MyInt2scala> val mi2 = new MyInt2(10)
mi2: MyInt2 = MyInt2@216c6825scala> mi2 +* 10
res7: Int = 200scala> mi2 +: 10
<console>:13: error: value +: is not a member of Int
mi2 +: 10
^scala> 10 +: mi2
res9: Int = 20
对于系统打印函数“print”、“printf”和“println”,其实也是中缀操作符,不过左侧的操作数是调用对象——控制台Console,右侧是要打印的内容。例如:
scala> Console println "Hello, world!"
Hello, world!
Ⅲ、后缀操作符
写在操作数后面的操作符称为后缀操作符,并且操作数只有一个,即调用该方法的对象。后缀操作符也对应一个无参方法,但是要注意方法名如果构成前缀操作符的条件,那么既可以写成前缀操作符,也可以把完整的方法名写成后缀操作符。例如:
scala> class MyInt3(val x: Int) {
| def display() = println("The value is " + x + ".")
| }
defined class MyInt3scala> val mi3 = new MyInt3(10)
mi3: MyInt3 = MyInt3@2670435scala> import scala.language.postfixOps
import scala.language.postfixOpsscala> mi3 display
The value is 10.
三、操作符的优先级和结合性
Ⅰ、优先级
在数学运算中,乘、除法的优先级要高于加、减法,这是算术操作符的优先级。Scala也保留了这种特性,并有一套判断操作符优先级的规则:通过操作符的首个字符来判断。因为操作符都是方法,所以也就是通过方法名的首个字符来比较优先级,注意前缀操作符的方法名要去掉关键字。当然,圆括号内的优先级是最高的,圆括号可以改变操作符的结合顺序。
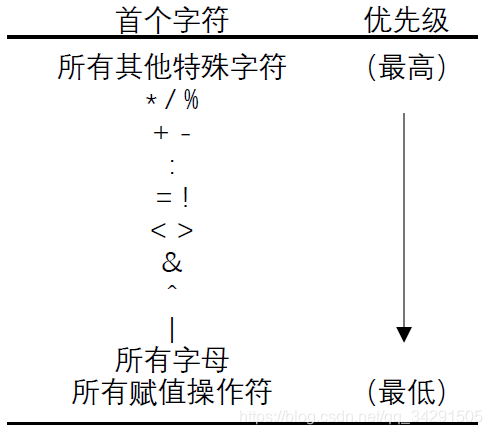
上图给出了各种字符的优先级顺序。例如,常规算术运算法则在计算表达式“1 + 2 * 3”时,会先算乘法,后算加法。类似地,如果有一个表达式“1 +++ 2 *** 3”,那么结合顺序就是“1 +++ (2 *** 3)”。
这个规则有一个例外:如果操作符以等号结尾,并且不是“>=”、“<=”、“==”或“!=”四个比较操作符之一,那么就认为是赋值操作符,优先级最低。例如,表达式“sum *= 1 + 2”会先算“1 + 2”,再把得出的3和sum相乘并赋给sum。也就是说,“*=”的优先级并不会因为以乘号开头就比加号高,而是被当作了一种赋值操作。
Ⅱ、结合性
一般情况下,同级的操作符都是从左往右结合的。但是,前面说了,以冒号结尾的中缀操作符的调用对象在右侧,所以这些操作符是从右往左结合的。例如,“a + b + c + d”的结合顺序是“((a + b) + c) + d”,而“a ::: b ::: c ::: d”的结合顺序则是“a ::: (b ::: (c ::: d))”。
一个好的编程习惯是让代码简洁易懂,不造成歧义。所以,在操作符的结合顺序不能一眼就看明白时,最好加上圆括号来表示前后顺序,即使不加圆括号也能得到预期的结果。例如,想要得到“x + y << z”的默认结果,最好写成“(x + y) << z”,以便阅读。
四、预设操作符
Scala预设了常用的算术、逻辑运算的操作符,总结如下:
| + | 算术加法 |
| - | 算术减法 |
| * | 算术乘法 |
| / | 算术除法 |
| % | 算术取余 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
| &&、& | 逻辑与,前者短路,后者不短路 |
| ||、| | 逻辑或,前者短路,后者不短路 |
| ! | 逻辑非 |
| & | 位与 |
| | | 位或 |
| ^ | 位异或 |
| ~ | 位取反 |
| >> | 算术右移 |
| << | 左移 |
| >>> | 逻辑右移 |
五、对象的相等性
在编程时,常常需要比较两个对象的相等性。其实相等性有两种:①自然相等性,也就是常见的相等性。只要字面上的值相等,就认为两个对象相等。②引用相等性。构造的对象常常会赋给一个变量,即让变量引用该对象。引用相等性用于比较两个变量是否引用了同一个对象,即是否指向JVM的堆里的同一个内存空间。如果两个变量引用了两个完全一样的对象,那么它们的自然相等性为true,但是引用相等性为false。
在Java里,这两种相等性都是由操作符“==”和“!=”比较的。Scala为了区分得更细致,也为了符合常规思维,只让“==”和“!=”比较自然相等性。这两个方法是所有类隐式继承来的,但是它们不能被子类重写。自定义类可能需要不同行为的相等性比较,因此可以重写隐式继承来的“equals”方法。实际上,“==”就是调用了equals方法,而“!=”就是对equals的结果取反。为了比较引用相等性,Scala提供了“eq”和“ne”方法,它们也是被所有类隐式继承的,且不可被子类重写。例如:
scala> val a = List(1, 0, -1)
a: List[Int] = List(1, 0, -1)scala> val b = List(1, 0, -1)
b: List[Int] = List(1, 0, -1)scala> val c = List(1, 0, 1)
c: List[Int] = List(1, 0, 1)scala> val d = a
d: List[Int] = List(1, 0, -1)scala> a == c
res0: Boolean = falsescala> a == b
res1: Boolean = truescala> a equals b
res2: Boolean = truescala> a eq b
res3: Boolean = falsescala> a eq d
res4: Boolean = true
六、总结
本章又进一步阐释了Scala追求的纯粹的面向对象,介绍了“操作符即方法”这个重要概念。这一概念对构建良好的DSL语言很重要,因为它使得不仅内建类型可以写成表达式,也让自定义的类在计算时可以写出自然的表达式风格。
关于对象相等性,这是一个较为复杂的概念。在自定义类里,如果要比较对象相等性,则不仅是简单地重写equals方法,还需要其他手段。这里不再赘述,如有必要,后续会继续讨论。

















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









