






一个离散属性的机器学习问题,转为分类或线性模型的关键就是怎么把这些离散值属性,如高矮,红绿用数值表现出来。通常来说,对于有序的属性,如{高、矮、胖},我们可以用{1,0.5,0}表示。若属性中不存在有序关系,我们用向量来表示,如“西瓜”,“黄瓜”,“南瓜”可以转化为(1,0,0),(0,1,0),(0,0,1)。
线性模型
y1=x11w1+x12w2+...+x1dwdy2=x21w1+x22w2+...+x2dwd.....ym=xm1w1+xm2w2+...+xmdwd
y_{1}= x_{11}w_{1}+x_{12}w_{2}+...+x_{1d}w_{d}\\
y_{2}= x_{21}w_{1}+x_{22}w_{2}+...+x_{2d}w_{d}\\
.....\\
y_{m} = x_{m1}w_{1}+x_{m2}w_{2}+...+x_{md}w_{d}\\
y1=x11w1+x12w2+...+x1dwdy2=x21w1+x22w2+...+x2dwd.....ym=xm1w1+xm2w2+...+xmdwd
为便于分析,我们把b放到权向量里面。
w=[w1,w2,...,wd,b]
w=[w_{1},w_{2},...,w_{d},b]
w=[w1,w2,...,wd,b]
y=[y1,y2,...,ym] y=[y_{1},y_{2},...,y_{m}] y=[y1,y2,...,ym]
(x11x12...x1d1x21x22...x2d1...............xm1xm2...xmd1)
\left(
\begin{array}{ccccc}
x_{11} & x_{12} & ... & x_{1d} & 1 \\
x_{21} & x_{22} & ... & x_{2d} & 1 \\
... & ... & ... & ... & ... \\
x_{m1} & x_{m2} & ... & x_{md} & 1 \\
\end{array}
\right)
⎝⎜⎜⎛x11x21...xm1x12x22...xm2............x1dx2d...xmd11...1⎠⎟⎟⎞
注意:上面共有m个输入输出样本对,(x1,y1),(x2,y2)...(xm,ym)(x_{1},y_{1}),(x_{2},y_{2})...(x_{m},y_{m})(x1,y1),(x2,y2)...(xm,ym),每一组的输入有d个属性,如(x1,y1)(x_{1},y_{1})(x1,y1),它的含义是输入为(x11,x12...x1d)(x_{11},x_{12}...x_{1d})(x11,x12...x1d)时,输出为y1,构建出的线性回归模型是d+1维。
矩阵形式可以表示为:
y=XWT
y=XW^{T}
y=XWT
若XTXX^{T}XXTX满秩,则易知WT=(XTX)−1XTyW^{T}=(X^{T}X)^{-1}X^{T}yWT=(XTX)−1XTy
广义线性模型:将线性模型利用非线性映射函数g(.)映射到非线性模型上去,以便更好地逼近。
y=g−1(xTw+b)
y=g^{-1}(x^{T}w+b)
y=g−1(xTw+b)
注意:g(.)线性可微
如对数线性回归:
lny=xTw+b
lny=x^{T}w+b
lny=xTw+b
对数几率回归(解决分类问题)
刚刚提出的线性模型可以解决回归问题,那么分类问题怎么解决呢?我们依旧可以构建一个线性模型,只是需要设置一个阈值,当xTw>Cx^{T}w>CxTw>C,为1类等等。
常用对数几率函数解决二类分问题:
y=11+e−z,z=xTw+b.
y=\frac{1}{1+e^{-z}},z=x^{T}w+b.
y=1+e−z1,z=xTw+b.
上式可以转化为:
lny1−y=xTw+b
ln\frac{y}{1-y}=x^{T}w+b
ln1−yy=xTw+b
其中lny1−yln\frac{y}{1-y}ln1−yy被称为对数几率,它反映了xxx作为正例的相对可能性。
线性判别分析(LDA )
该方法就是利用投影的方法,将不同分类的样本点投影到一条直线上,从而使类内距离小,类间距离大,而使分类效果更好。

类内距离:wTΣ0w+wTΣ0ww^{T}\Sigma_{0}w+w^{T}\Sigma_{0}wwTΣ0w+wTΣ0w
类间距离:∥wTμ0+wTμ1∥22\|w^{T}\mu_{0}+w^{T}\mu_{1}\|_{2}^{2}∥wTμ0+wTμ1∥22
其中Σ0\Sigma_{0}Σ0、Σ1\Sigma_{1}Σ1为协方差矩阵。
类内散度矩阵(SwS_{w}Sw)
Sw=Σ0+Σ1=∑xϵXi(x−μi)(x−μi)T,(i=0,1)
S_{w}=\Sigma_{0}+\Sigma_{1}=\sum\limits_{x \epsilon X_{i}} (x-\mu_{i})(x-\mu_{i})^{T},(i=0,1)
Sw=Σ0+Σ1=xϵXi∑(x−μi)(x−μi)T,(i=0,1)
类间散度矩阵(SbS_{b}Sb)
Sb=(μ0−μ1)(μ0−μ1)T
S_{b}=(\mu_{0}-\mu_{1})(\mu_{0}-\mu_{1})^{T}
Sb=(μ0−μ1)(μ0−μ1)T
准则函数J参考下式,J越大越好。
J=∥wTμ0+wTμ1∥22wTΣ0w+wTΣ0=wTSbwwTSww J=\frac{\|w^{T}\mu_{0}+w^{T}\mu_{1}\|_{2}^{2}}{w^{T}\Sigma_{0}w+w^{T}\Sigma_{0}}=\frac{w^{T}S_{b}w}{w^{T}S_{w}w} J=wTΣ0w+wTΣ0∥wTμ0+wTμ1∥22=wTSwwwTSbw
| 多类分问题见西瓜书63页: |
对于多类分问题,除了引进StS_{t}St外,SbS_{b}Sb和SwS_{w}Sw的计算方法也发生了改变,最后准则函数也会改变。
多分类学习
多分类学习的基本思路是拆解法,即将多个分类任务拆分成多个两类分任务。并为拆解出来的每一个两类分任务训练一个分类器,最后对分类器结果集成,得到多分类结果。
经典拆分策略:一对一(OvO),一对多(OvR),多对多(MvM)。
其中,OvO和OvR策略参考下图很容易清楚其思想内涵。
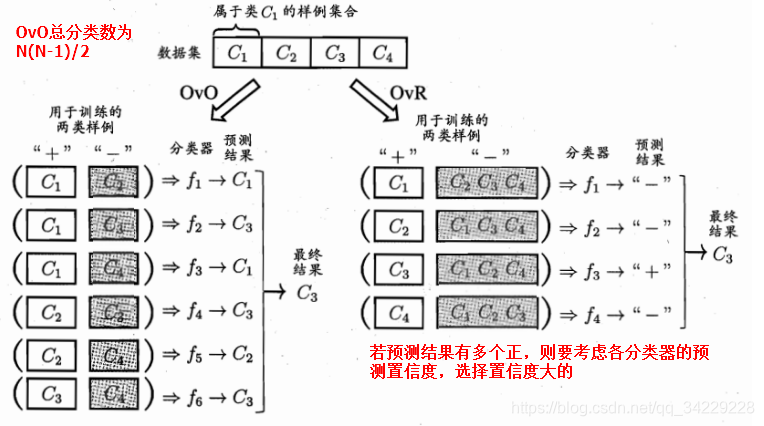
MvM: 就是M个分类器将N个类别做M次划分,每次有类别有一部分正例和一部分反例,如f1分类器将C2划分为正例,C1、C3、C4划分为反例。该方法包括编码和解码,编码就是f1要对类别以及测试示例进行编码。解码就是根据类别与测试样例距离最小找出测试样例最终属于哪一个类别。
常用MvM技术为纠错输出码ECOC。
该编码分为二元和三元,二元只将各类分为正类和反类,三元可以有停用类,即分类时不使用该类。
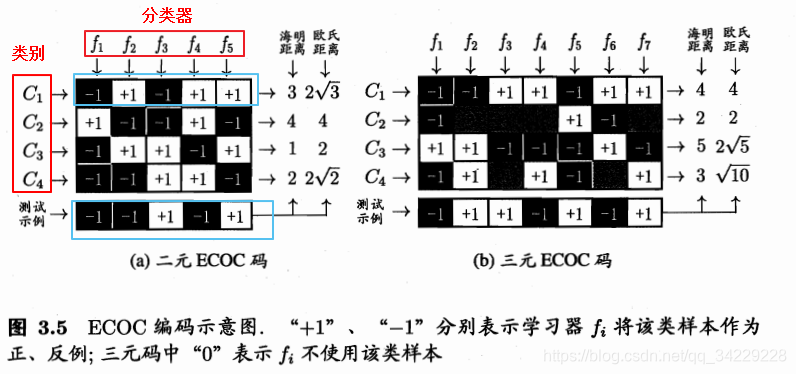
以蓝框C1和蓝框测试样例为例讲述明氏距离和欧氏距离的计算。
海明距:0+1+1+1+0=30+1+1+1+0=30+1+1+1+0=3
欧氏距离:0+22+22+22+0=23\sqrt{0+2^{2}+2^{2}+2^{2}+0}=2\sqrt{3}0+22+22+22+0=23
对于二元ECOC码,最后根据欧式距离最小应将它分为C3类。


















 3345
3345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











