






资料为初步问题一二解题代码,仅供参考,如有不同意见或更好思路欢迎指正
分享资料链接
https://pan.baidu.com/s/1g5fBwXRy5nsgbjZwKyhimg
提取码:i3kc
问题 D(ICM)风能与太阳能电厂 详细解题思路
任务:提供的数据集包括一个月的来自12个风力发电机组和11个太阳能电站的发电数据。目标是开发一个有效的数学模型来解决以下任务:
任务1: 分析风电场和太阳能电场的发电波动模式
应在总发电量出现显著下降(至少提前5分钟)或显著上升(至少提前2分钟)时进行预测。设当前时刻的发电量为 p,过去30分钟的平均发电量为 q。波动幅度通过 k = |p − q|/q 来衡量。当 k 超过指定阈值 t 时,定义为显著下降或上升。你可以选择阈值 t,目标是使 t 尽可能小,同时提高预测的准确性。
步骤1.1: 数据预处理与波动计算
·首先对题目给出数据进行必要处理,并按时间戳对数据进行排序,确保数据是按正确的时间顺序排列。
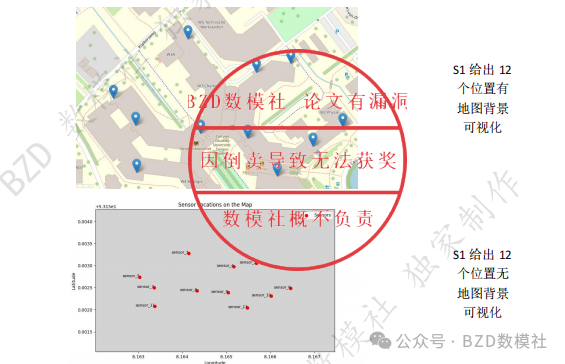
例如,可以对给出的位置经纬度绘制可视化结果,也可以对给出数据进行必要描述性分析。

步骤1.2: 确定显著波动阈值
·根据题意,当 超过某个阈值 时,认为发生了"显著的波动",可以是显著下降或显著上升。需要根据历史数据选择合适的阈值 。
·可以通过分析过去数据中 的分布情况(例如,通过直方图或统计分析)来选择阈值。一般来说, 的值不应过大,否则可能会错过一些实际的波动。
·选择合适的闻值 后,你可以识别出那些显萆的波动事件(即,波动幅度大于 的时刻)。
# 4. 计算过去30分钟的平均发电量并计算波动幅度
window_size = 30 # 过去30分钟的窗口
# 计算每个传感器的滚动平均值(过去30分钟的平均发电量)
for sensor in ['sensor_1', 'sensor_2', 'sensor_4', 'sensor_5', 'sensor_6']: # 可以根据实际情况调整传感器列表
data[f'{sensor}_rolling_avg'] = data[sensor].rolling(window=window_size).mean()
# 计算波动幅度
t = 0.5 # 设置波动幅度阈值t,默认设为0.2,表示波动幅度超过20%时认为是显著波动
for sensor in ['sensor_1', 'sensor_2', 'sensor_4', 'sensor_5', 'sensor_6']:
# 计算当前时刻的波动幅度
data[f'{sensor}_fluctuation'] = abs(data[sensor] - data[f'{sensor}_rolling_avg']) / data[f'{sensor}_rolling_avg']
# 标记显著波动
data[f'{sensor}_significant_change'] = np.where(data[f'{sensor}_fluctuation'] > t, 1, 0) # 1代表显著波动,0代表没有显著波动
步骤1.3:波动预测
·你需要对即将发生的显著波动进行预测。具体来说,在波动发生前(例如,显著下降至少5分钟,显著上升至少 2 分钟),你需要预测到这一变化。
·你可以选择不同的预测方法,例如:
·滑动平均法:基于历史数据(例如,过去几分钟的功率数据)来预测未来的功率变化。
·时间序列分析:使用ARIMA、LSTM等模型来预测功率变化。
·回归模型:例如多项式回归、支持向量回归等,根据历史数据拟合预测模型。
步骤1.4:精度与阈值选择
·对不同阈值 和预测方法进行实验,评估模型的精度。你可以计算准确率、召回率、F1-score等评价指标来评估预测性能。
·准确率:预测的波动事件与真实波动事件匹配的比例。
·召回率:真实发生波动事件中被正确预测的比例。
·F1-score: 综合考虑准确率和召回率的平衡。
任务2: 进行短期发电量预测
步骤2.1:确定预测目标
·你需要分别对未来1到120秒的发电量进行预测。
·因为数据的采样频率是 1 Hz ,意味着你有 1 秒钟间隔的数据。目标是基于当前时刻的功率数据,预测未来1秒到120秒的发电量变化。
步骤2.2: 选择预测模型
·传统时间序列方法:例如ARIMA、SARIMA等,适合于有季节性或趋势性的时间序列数据。
·机器学习模型:例如随机森林、XGBoost等,可以通过构造特征(如历史功率数据、时间等)来进行预测。
·深度学习模型:例如LSTM(长短时记忆网络),适用于具有时序性质的数据,能够捕捉到长期的时间依赖关系。
这里为了方便展示,我们仅仅以问题一线性回归为例进行预测展示,后续会进一步选择高精度模型。

import geopandas as gpd
import matplotlib.pyplot as plt
from shapely.geometry import Point
# 经纬度数据
coordinates = {
'sensor_1': (53.1532754254192, 8.16414535045624),
'sensor_2': (53.1530566746515, 8.16568493843079),
'sensor_4': (53.152976251295, 8.16516995429993),
'sensor_5': (53.1527414142317, 8.16302955150604),
'sensor_6': (53.152487274045, 8.1664627790451),
'sensor_7': (53.1525001419387, 8.16336214542389),
'sensor_8': (53.1524293684755, 8.16433310508728),
'sensor_9': (53.1523843307564, 8.16504120826721),
'sensor_10': (53.1523135571024, 8.16601753234863),
'sensor_11': (53.1520787164146, 8.16337823867798),
'sensor_13': (53.1520465463573, 8.16548109054565)
}
# 提取所有的经纬度
latitudes = [lat for lat, lon in coordinates.values()]
longitudes = [lon for lat, lon in coordinates.values()]
# 计算经纬度范围
min_lat = min(latitudes)
max_lat = max(latitudes)
min_lon = min(longitudes)
max_lon = max(longitudes)
# 创建一个GeoDataFrame
points = [Point(lon, lat) for lat, lon in coordinates.values()]
gdf = gpd.GeoDataFrame(geometry=points)
# 获取地图数据
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
# 创建绘图
fig, ax = plt.subplots(figsize=(10, 10))
# 绘制背景地图
world.plot(ax=ax, color='lightgray')
# 绘制传感器位置
gdf.plot(ax=ax, color='red', markersize=50, label='Sensors')
# 添加标签
for label, (lat, lon) in coordinates.items():
ax.text(lon, lat, label, fontsize=9, ha='right', color='black')
# 设置地图显示的经纬度范围
ax.set_xlim(min_lon - 0.001, max_lon + 0.001) # 适当扩展范围,避免点太靠边
ax.set_ylim(min_lat - 0.001, max_lat + 0.001)
# 设置标题
plt.title("Sensor Locations on the Map")
plt.xlabel("Longitude")
plt.ylabel("Latitude")
plt.legend()
# 显示地图
plt.show()
import folium
# 经纬度数据
coordinates = {
'sensor_1': (53.1532754254192, 8.16414535045624),
'sensor_2': (53.1530566746515, 8.16568493843079),
'sensor_4': (53.152976251295, 8.16516995429993),
'sensor_5': (53.1527414142317, 8.16302955150604),
'sensor_6': (53.152487274045, 8.1664627790451),
'sensor_7': (53.1525001419387, 8.16336214542389),
'sensor_8': (53.1524293684755, 8.16433310508728),
'sensor_9': (53.1523843307564, 8.16504120826721),
'sensor_10': (53.1523135571024, 8.16601753234863),
'sensor_11': (53.1520787164146, 8.16337823867798),
'sensor_13': (53.1520465463573, 8.16548109054565)
}
# 创建地图对象,初始位置设为数据点的中心位置
m = folium.Map(location=[53.1525, 8.164], zoom_start=15, control_scale=True)
# 向地图中添加背景(OpenStreetMap或其他底图)
folium.TileLayer('openstreetmap').add_to(m) # OpenStreetMap 背景
# 或者使用其他底图,比如:
# folium.TileLayer('Stamen Terrain').add_to(m) # Stamen Terrain 背景
# folium.TileLayer('Stamen Toner').add_to(m) # Stamen Toner 背景
# folium.TileLayer('CartoDB positron').add_to(m) # CartoDB positron 背景
# 在地图上添加传感器点
for sensor, (lat, lon) in coordinates.items():
folium.Marker([lat, lon], popup=sensor).add_to(m)
# 保存地图到HTML文件
m.save("sensors_map_with_background.html")
# 显示提示信息
print("地图已保存为 'sensors_map_with_background.html',打开该文件查看交互式地图。")
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 读取数据
file_path = 'S1.txt'
data = pd.read_csv(file_path, sep='\s+', header=0, # header=0 确保第一行被当作列名
dtype={'timestamp': 'float64'}, low_memory=False)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 2. 确保时间戳列是数字并转换为 datetime 类型
data['timestamp'] = pd.to_datetime(data['timestamp'], unit='s', errors='coerce')
# 3. 描述性统计分析
desc_stats = data.describe()
print("描述性统计数据:")
print(desc_stats)
# 4. 时间序列图
plt.figure(figsize=(12, 6))
for sensor in data.columns[1:]:
plt.plot(data['timestamp'], data[sensor], label=sensor)
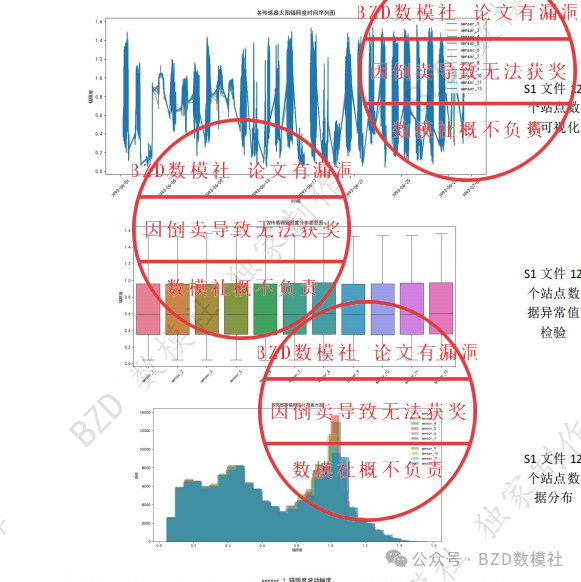
plt.title('各传感器太阳辐照度时间序列图')
plt.xlabel('时间')
plt.ylabel('辐照度')
plt.legend(loc='upper right')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 5. 绘制辐照度分布直方图
plt.figure(figsize=(12, 6))
for sensor in data.columns[1:]:
plt.hist(data[sensor], bins=30, alpha=0.5, label=sensor)
plt.title('各传感器辐照度分布直方图')
plt.xlabel('辐照度')
plt.ylabel('频率')
plt.legend(loc='upper right')
plt.tight_layout()
plt.show()
# 6. 绘制箱型图
plt.figure(figsize=(12, 6))
sns.boxplot(data=data.iloc[:, 1:], orient='vertical')
plt.title('各传感器辐照度分布箱型图')
plt.ylabel('辐照度')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 7. 波动性分析
# 计算每个传感器的平均值并计算波动性
for sensor in ['sensor_1', 'sensor_2', 'sensor_4', 'sensor_5', 'sensor_6']: # 你可以根据实际情况调整传感器列表
data[f'{sensor}_avg'] = data[sensor].mean() # 计算每个传感器的平均值
data[f'{sensor}_fluctuation'] = abs(data[sensor] - data[f'{sensor}_avg']) / data[f'{sensor}_avg'] # 计算波动性
# 8. 滚动窗口分析
window_size = 24 # 设置为24小时窗口大小,或者根据实际情况调整
for sensor in ['sensor_1', 'sensor_2', 'sensor_4', 'sensor_5', 'sensor_6']: # 只分析部分传感器
# 在这里计算滚动平均并命名为 `{sensor}_avg`
data[f'{sensor}_rolling_avg'] = data[sensor].rolling(window=window_size).mean()
# 计算滚动波动性
data[f'{sensor}_rolling_fluctuation'] = abs(data[sensor] - data[f'{sensor}_rolling_avg']) / data[f'{sensor}_rolling_avg']
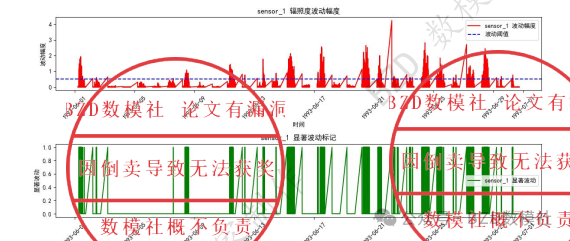
# 9. 绘制sensor_1波动幅度时间序列图
plt.figure(figsize=(12, 6))
plt.plot(data['timestamp'], data['sensor_1_fluctuation'], label='sensor_1 波动幅度', color='r')
plt.title('sensor_1 辐照度波动幅度')
plt.xlabel('时间')
plt.ylabel('波动幅度')
plt.xticks(rotation=45)
plt.tight_layout()
plt.legend()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









