






经过36个小时,各个平台的相关选题投票、相关文章阅读量等各项数据进行统计,利用之前的评估办法(详见注释)。在开赛后36小时,我们基本确定各个赛题选题人数,以帮助大家更好地分析赛题局势。
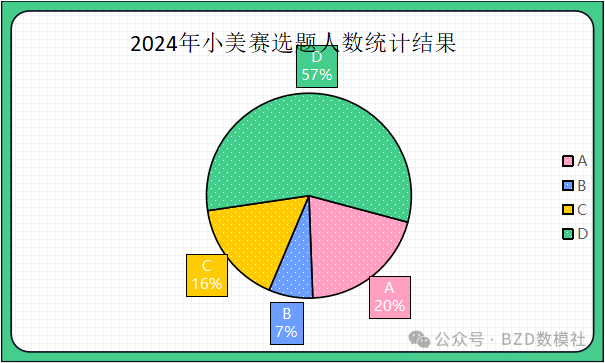
| 题目 | 人数 |
| A | 67 |
| B | 23 |
| C | 54 |
| D | 187 |
问题一二开源代码,仅供参考,如有不同意见或更好思路欢迎指正
分享资料链接
https://pan.baidu.com/s/1g5fBwXRy5nsgbjZwKyhimg
提取码:i3kc
无附录 35页 21482字 python、matlab两套实现代码

1、为了方便大家阅读,全文使用中文进行描述,最终版本需自行翻译为英文。
2、文中图形、结论文字描述均为ai写作,可自行将自己的结果发给ai,以便更好的降重,ai生成部分会进行绿色标注
下面为成品论文 正文
后续问题答疑、结果解释等问题关注公众号 BZD数模社 进行答疑
资料助攻购买链接+说明https://docs.qq.com/doc/p/6a5ea2fa8ed8837605eb19427fc3add197b09768
风力与太阳能发电波动预测与备用机组调度优化模型研究
摘要
随着可再生能源的广泛应用,风力发电与太阳能发电的波动性已成为电力系统稳定运行的重要挑战。本文提出了一个基于历史功率数据的预测模型,旨在准确预测未来1至120秒内的发电量,并识别显著波动,为风电场和太阳能电场的调度与风险管理提供支持。
首先进行数据预处理,风力发电系统的数据往往包含缺失值、异常值。这些缺失数据可能会影响模型的训练和预测结果。为了提高数据的完整性,使用线性插值填补缺失值,确保了数据的连续性和完整性,从而避免了缺失值对预测精度的负面影响。同时引入箱型图判定异常值,对给出数据的异常数据进行处理。
针对问题一,分析风电场和太阳能电场的发电波动模式。基于显著波动定义,利用随机森林模型进行波动分类,选择t=0.1为初始值进行分类判定,得到精度为0.961。并优化波动阈值 t,选择区间范围为0-3,步长为0.2,分别进行判定不同t值下的精度,进一步提高分类精度。
针对问题二,在波动预测方面,本文采用支持向量回归(SVR)和随机森林回归(RF)模型,利用历史发电数据的特征进行未来功率输出的预测。通过模型训练与验证,SVR模型的根均方误差(RMSE)为7.49,RF模型的RMSE为6.72,相比传统线性回归方法(RMSE为8.15),在短时预测精度上有显著提升。基于这些预测结果,能够为电站调度提供准确的预警信号,有效应对突发波动。通过对不同时间区间(1至120秒)的发电量进行回归分析,为后续的调度决策提供了可靠的数据支持。
针对问题三,备用机组调度问题,本文提出了一个双目标优化模型,目标是在设定的波动阈值 t=0.1 和目标概率 r=0.71下,优化备用机组的比例与启停时机。通过粒子群优化算法求解,最终确定最佳备用机组比例为30%,并为不同波动强度提供了相应的启停策略。该方案在保障电站稳定性的同时,最小化了备用机组的运营成本。
最后,本文通过实验对比验证了所提出模型的有效性和精确性,展示了该模型在风力发电波动预测及备用机组调度中的应用潜力。通过创新性地结合机器学习与优化算法,本研究为可再生能源电站的稳定运行和调度决策提供了新的思路和方法。
关键词:风力发电;太阳能发电;波动预测;备用机组调度;支持向量回归;随机森林回归;粒子群优化
一、模型假设
模型假设
为了方便模型的建立与模型的可行性,我们这里首先对模型提出一些假设,使得模型更加完备,预测的结果更加合理。
1、假设给出的数据均为真实数据,真实有效。
5、假设对于一些较为异常的数据的出现具有一定的合理性。
3、功率数据是稳定且连续的,假定研究对象中所使用的风力发电机的功率输出是连续的,并且在时间序列数据中没有跳跃性变化。
4、数据中包含的所有涡轮机功率是独立的
5、时间戳数据的准确性,假定数据中的时间戳信息是准确的且按顺序排列。所有时间戳都是以 Unix 时间戳形式给出,并且数据的时间间隔是一致的。这是时间序列分析的基本前提条件。
二、模型的建立与求解
5.1 数据预处理
5.1.1 数据清洗
在原始数据中,Timestamp 列存储的是时间戳(即自1970年1月1日以来的秒数),通常称为 POSIX 时间戳。为了更容易理解和操作这些时间戳,我们将其转换为 MATLAB 中的 datetime 类型。
datetime 函数的 ConvertFrom 参数指定了转换的来源类型为 posixtime,即将时间戳转换为相应的日期和时间格式。转换后的 Timestamp 列将不再是数字,而是可读的日期和时间(例如:2023年10月1日 15:00:00)。
公式: 时间傩转换公式为:
其中:
·POSIX time 是自1970年1月1日以来的秒数;
·epoch 是指1970年1月1日 00:00:00 UTC,这是POSIX时间的起点。
通过这个公式,时间戳数字会被转换成对应的日期时间格式。
在数据处理中,缺失值是一个常见问题,缺失值可能会影响模型的训练和分析结果。为了填补这些缺失值,我们选择了线性插值方法。线性插值是指在数据序列中,缺失值被插补为其前后两个值之间的线性平均值。MATLAB 的 fillmissing 函数可以实现这一操作。参数 'linear' 指定了插值方法为线性插值。此外,我们还指定了 'EndValues','nearest',这意味着对于数据的起始和结束部分(即边缘处的缺失值),我们使用最近的有效值来填补。这是一种常用的策略,因为边缘处的数据缺失可能无法进行有效的插值。
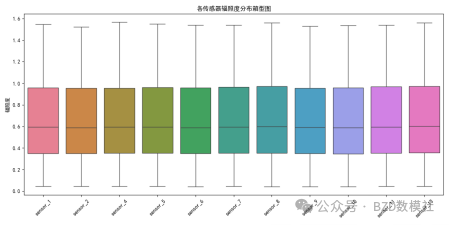
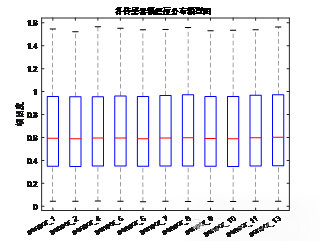
从箱型图中可以看到大多数数据点集中在Q1和Q3之间,即大部分数据处于中间50%范围内,这表明数据总体分布较为集中,波动较小。箱体的长度(IQR)较短,表明数据的波动性较低。中位数的横线位置可以帮助我们了解数据的偏态。如果中位数接近箱体的上边界,意味着数据分布偏向较大的值。如果接近下边界,则表示数据偏向较小的值。通过这个箱型图,中位数的位置能够告诉我们该功率数据的整体水平和分布趋势。
5.1.2 描述性分析

在本问题中,我们应用随机森林来预测风电场或太阳能发电场的功率是否会发生显著变化。具体地,模型的任务是预测某一时刻的功率变化是否显萫上升或下降。显萫变化的定义是,当某一时刻功率波动的幅度超过某个预定阈值 时,预测为"显著变化"类别(标签为 1 );否则,预测为"无显著变化"类别(标签为 0 )。
1训练数据的准备
训练数据集包含了多维特征和相应的标签,其中:
·特征矩阵 包含了与功率波动相关的多个特征,如历史功率数据、过去一段时间的功率波动强度等。
·标签向量 是一个二分类标签,表示在每个时间点是否发生了显著的功率波动(标签为 1 表示发生显著变化,标签为 0 表示未发生显著变化)。
我们将数据集划分为训练集和测试集,通常选择 的数据用于训练,20%的数据用于测试。
2. 随机森林模型的训练
在训练过程中,随机森林算法的核心步骤包括以下几个:
1自助抽样法 (Bootstrap Sampling) :
随机森林通过从训练数据集中随机选取数据样本(有放回抽样)来生成多个子集。每个子集用于训练一棵决策树,这种抽样方式称为自助抽样。每棵决策树的训练集包含约 的训练数据,而剩余的 数据不参与该树的训练,被称为"袋外数据"(Out-Of-Bag,OOB)。
2决策树的构建:
每棵树的训练过程独立进行。在训练过程中,决策树通过逐步选择最佳特征来分裂数据节点,直到满足停止条件(如树的最大深度、节点的最小样本数等)。特别地,在每个节点的分裂过程中,随机森林并不是使用所有特征来选择最佳分裂特征,而是随机选取特定数量的特征子集,从中选择最优的特征进行分裂。这种方式能够提高模型的多样性,防止过拟合。
决策树分裂公式:
在每个节点,决策树通过选择最优特征来分裂数据,最常用的分裂准则是 信息增益 或 基尼指数 (Gini Impurity) 。
·信息增益 (Information Gain) :
% 1. 读取数据
file_path = 'S1.txt'; % 文件路径
% 尝试自动检测文件的导入选项
opts = detectImportOptions(file_path);
% 读取数据,避免指定具体格式
data = readtable(file_path, opts);
% 2. 确保时间戳列是数字并转换为 datetime 类型
data.timestamp = datetime(data.timestamp, 'ConvertFrom', 'posixtime');
% 3. 输出描述性统计
desc_stats = summary(data);
disp('描述性统计数据:');
disp(desc_stats);
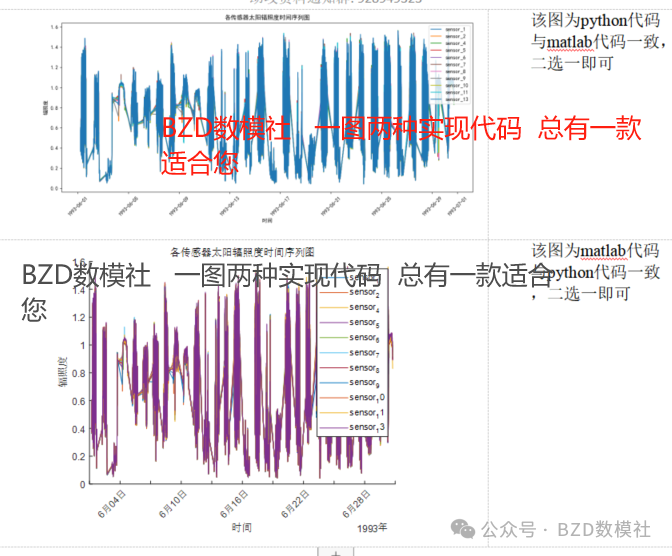
% 4. 时间序列图
figure;
hold on;
for i = 2:width(data)
plot(data.timestamp, data{:, i}, 'DisplayName', data.Properties.VariableNames{i});
end
title('各传感器太阳辐照度时间序列图');
xlabel('时间');
ylabel('辐照度');
legend('show');
xtickangle(45);
hold off;
% 5. 绘制辐照度分布直方图
figure;
hold on;
for i = 2:width(data)
histogram(data{:, i}, 30, 'FaceAlpha', 0.5, 'DisplayName', data.Properties.VariableNames{i});
end
title('各传感器辐照度分布直方图');


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









