




 该博客详细记录了使用PaddlePaddle复现D4LCN论文的过程,包括数据预处理、网络结构复现、精度对齐及模型训练、预测和评估。作者克服了深度图处理、二维卷积限制等问题,实现了在KITTI数据集上的单目3D目标检测。博客提供了从Pytorch到PaddlePaddle的模型转换及精度对齐的技巧,并分享了训练和预测的步骤,为后续研究者提供了参考。
该博客详细记录了使用PaddlePaddle复现D4LCN论文的过程,包括数据预处理、网络结构复现、精度对齐及模型训练、预测和评估。作者克服了深度图处理、二维卷积限制等问题,实现了在KITTI数据集上的单目3D目标检测。博客提供了从Pytorch到PaddlePaddle的模型转换及精度对齐的技巧,并分享了训练和预测的步骤,为后续研究者提供了参考。
D4LCN: Learning Depth-Guided Convolutions for Monocular 3D Object Detection (CVPR2020)
基于深度引导卷积的单目3D目标检测
1. 论文简介
(1)简介
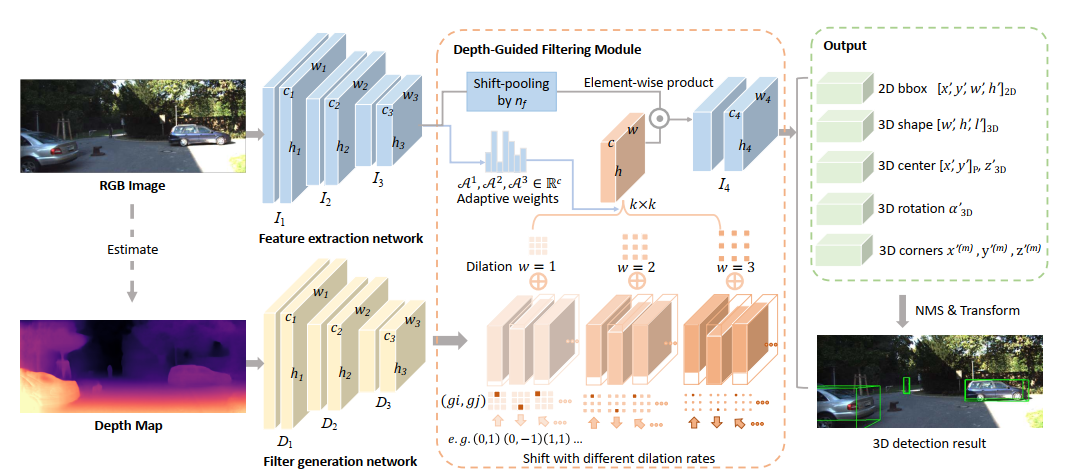
单目3D目标检测最大的挑战在于没法得到精确的深度信息,传统的二维卷积算法不适合这项任务,因为它不能捕获局部目标及其尺度信息,而这对三维目标检测至关重要。为了更好地表示三维结构,现有技术通常将二维图像估计的深度图转换为伪激光雷达表示,然后应用现有3D点云的物体检测算法。因此他们的结果在很大程度上取决于估计深度图的精度,从而导致性能不佳。在本文中,作者通过提出一种新的称为深度引导的局部卷积网络(LCN),更改了二维全卷积Dynamic-Depthwise-Dilated LCN ,其中的filter及其感受野可以从基于图像的深度图中自动学习,使不同图像的不同像素具有不同的filter。D4LCN克服了传统二维卷积的局限性,缩小了图像表示与三维点云表示的差距。D4LCN相对于最先进的KITTI的相对改进是9.1%,单目3D检测的SOTA方法。
(2)网络主要结构
(3)论文地址
https://arxiv.org/pdf/1912.04799v1
(4)官方代码地址
https://github.com/dingmyu/D4LCN
2.复现心得
先回顾下之前百度论文复现营老师指导的复现流程
(1)整体流程
- 数据集获取
- 数据预处理
- 构建前向网络
- 构建反向传播
- 精度对齐,小数据集训练两轮
(2)精度对齐
- 去除随机性:对项目中dropout项,数据预处理中mirror的随机性置0
- 数据对齐,输入数据:本项目数据预处理部分涉及深度图,需要对其进行预处理
- 模型参数对齐
Pytorch 和 Paddle 网络参数输出并手动对齐
Pytorch参数转化为Paddle
将保存的模型载入并设置Paddle模型初始化 - loss对齐
- 小规模实验
3.复现过程
(1)数据处理
- 数据集采用kitti 数据集
- dataloader 因PaddlePaddle官方给的dataloader方式,无法载入字典easydict类型的文件(原代码需要,保存相机参数等),固参考之前论文复现营的方法,自己定义了dataloader类,详细可见我的博客Paddle复现Pytorch踩坑(十):dataloader读取
(2)模型的复现
这一步是项目的核心,主要分成两个部分:
- 前向传播
主要分为ResNet、ResNet、DeformConv2d、RPN这
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2631
2631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









