







Word2vec简单理解
思路
Word2vec是word embedding 的一种
思路:学习一种语言模型能够判断(x,y)是否符合自然语言规则,其中x为一个词语,y为理解的语义,而word2vec是选择模型的部分中间产物来代表这个词语,将输入x向量化,这个向量则为–词向量。
word2vec的相似,指的是结构上的相似,如下:

语言模型
对于语言模型的训练,首先将输入做one-hot encoder 作为输入,而将下一个词的one-hot encider 的结果作为结果。
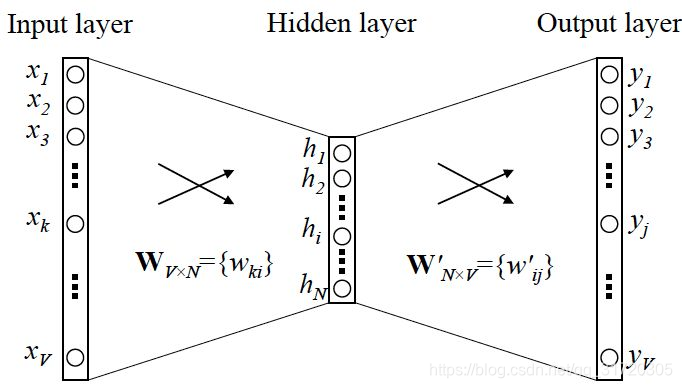
这个有一个特别的地方在于hidden layer的activation function 是线性的。
对于隐层来说,由于输入是稀疏的,只有代表one-hot编码后为1的位置相连的权重被激活,将输入x映射为vx,这个vx中的权重v对于每个输入x各不相同,所以能够将vx来代表x。由于做Word2vec的目的之一在于降维,所以隐层的节点数N是要远小于输入个数v的。
具体语言模型主要两种:CBOW和 skip_gram
CBOW模型根据中心词W(t)周围的词来预测中心词
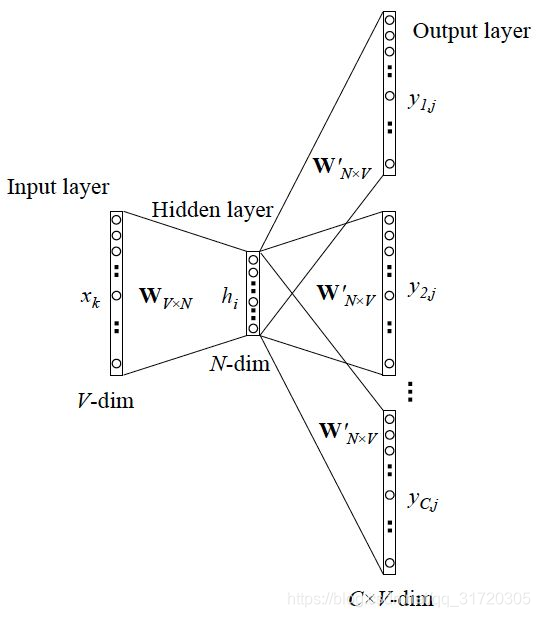
Skip-gram模型则根据中心词W(t)来预测周围词
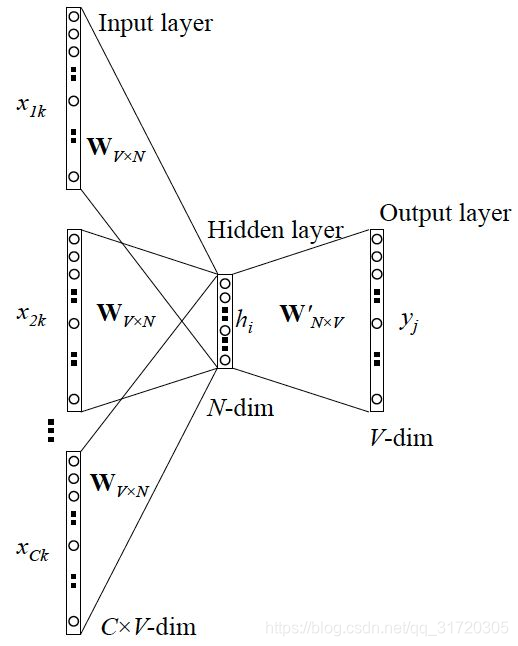
cbow比sg训练快,sg比cbow更好地处理生僻字(出现频率低的字)
加速
由于训练中语言的个数非常庞大,需要特别的技巧来加速训练,这个有两种方法:Negative Sample与Hierarchical Softmax
Negative Sample 本质是预测总体类别的一个子集
Hierachical softmax 本质是把 N 分类问题变成 log(N)次二分类

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









