




 word2vec是Google的词向量计算工具,它利用浅层神经网络生成词向量,揭示词与词之间的相似性。本文介绍了word2vec的CBoW和Skip-gram模型,以及其在商品推荐、社交网络推荐等领域的应用。
word2vec是Google的词向量计算工具,它利用浅层神经网络生成词向量,揭示词与词之间的相似性。本文介绍了word2vec的CBoW和Skip-gram模型,以及其在商品推荐、社交网络推荐等领域的应用。
一.什么是word2vec
word2vec是Google开源的一款用于词向量计算的工具。word2vec不仅可以在百万数量级的词典和上亿的数据集上进行高效地训练,还可以得到训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。其实word2vec算法的背后是一个浅层神经网络,而且还是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型
举一个例子:
先给出一个句子
[小赖是我最喜欢的人]
假设x是[我],那么y就可以是[小赖],[是我],[最喜欢的],[人]
现给出另一个句子
[小赖是他最讨厌的人]
如果输入x是[他],那么根据关联度就知道了[我==他]
二.具体过程
实现原理
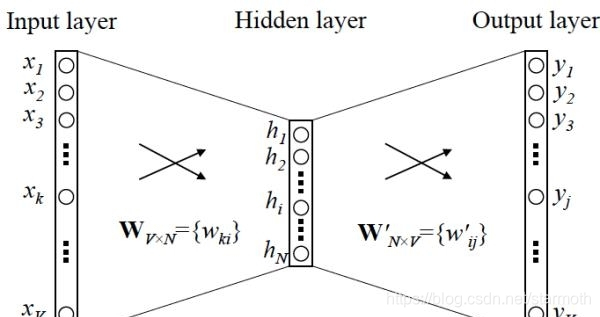
众所周知,word2vec是根据网络模型构建的,有输入层,隐藏层,输出层。下面就来介绍他的两个模型
1.CBOW 模型:
根据词的上下文预测词
输入层:包含层的上下文
隐藏层:对输入层的东西做向量求和累加
输出层:输出一颗Huffman树,叶子节点对应词典的词
2.skip-gram模型
根据该词预测上下文
输入层:只包含中心词向量
隐藏层:多余,无实际用处
输出层:输出Huffman树
三.应用
1、计算商品的相似度
在商品推荐中,竞品推荐和搭配推荐时都有可能需要计算任何两个商品的相似度,根据浏览/收藏/下单/App下载等行为,可以把商品看做词,把每一个用户的一类行为序看做一个文档,通过word2vec将其训练为一个向量。
同样的,在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









