






论文链接:https://arxiv.org/pdf/2503.01743
Phi-4-Mini Technical Report 解读
1. 背景与动机
论文旨在提出两种紧凑而高效的模型:
- Phi-4-Mini:一个拥有3.8B参数的语言模型,采用高质量的网络和合成数据进行训练。论文指出,尽管参数较少,但在数学与编程任务等复杂推理任务上能够达到甚至超过规模为其两倍的模型。
- Phi-4-Multimodal:在Phi-4-Mini语言模型基础上扩展多模态能力,能够同时处理文本、图像和语音/音频输入。该模型采用“Mixture of LoRAs”技术,即在保持基础语言模型冻结的前提下,通过针对各模态设计专用的LoRA适配器,实现多模态推理而不产生相互干扰。
论文的核心动机在于证明:
- 通过精心构造的高质量合成数据和数据混合策略,即使是紧凑型模型也可以获得与大型模型相当甚至更优的性能;
- 利用冻结基础模型,加上模态专用的可微调LoRA模块,不仅能在纯语言任务上保持竞争力,同时在多模态任务上也能实现统一高效的推理。
2. 模型架构
论文提出的Phi-4系列模型分为两部分,均基于解码器式Transformer架构,并支持长达128K的上下文长度(基于LongRoPE):
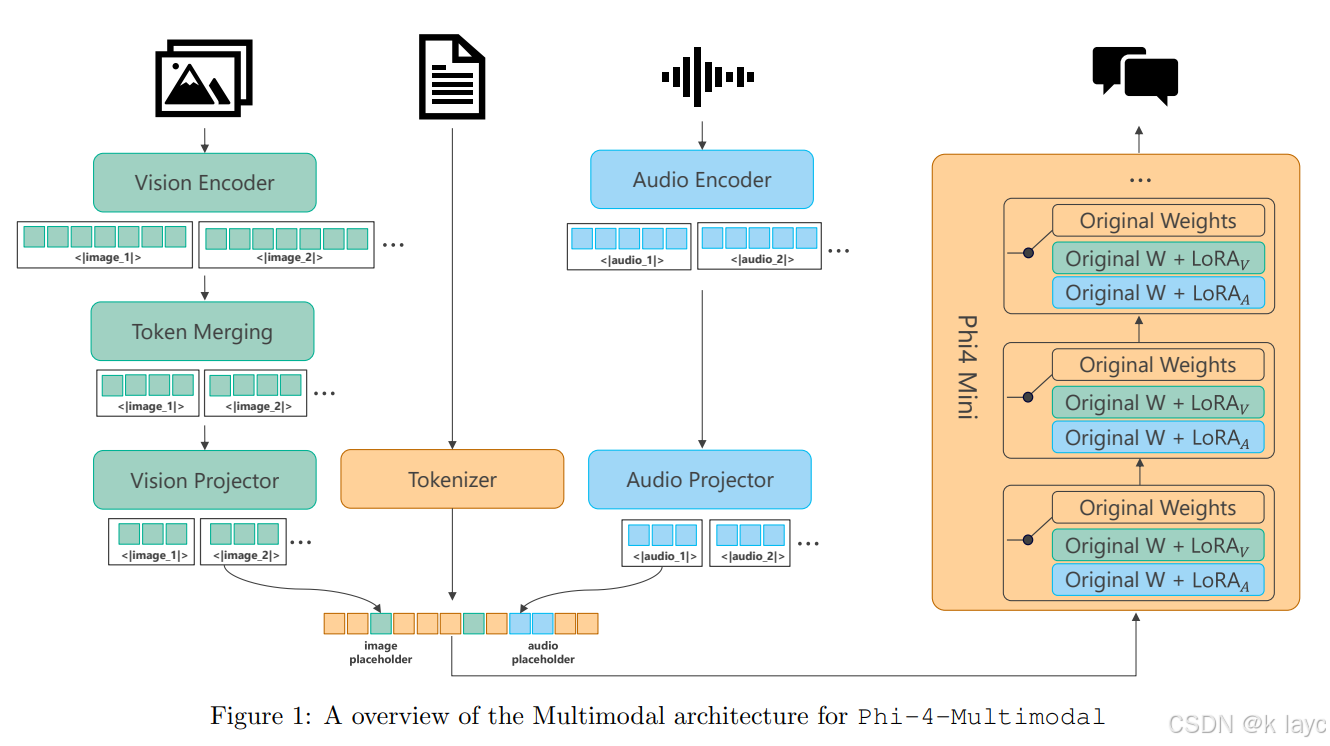
2.1 语言模型部分——Phi-4-Mini
-
结构:
Phi-4-Mini由32层Transformer组成,每层的隐藏状态维度为3072,并采用输入/输出共享嵌入(tied embedding)以减少内存消耗,同时扩大词汇覆盖范围,相比前代Phi-3.5有显著提升。 -
Group Query Attention (GQA):
每个Transformer块使用GQA机制来优化长序列生成时键值缓存的使用。具体而言,模型采用24个查询头和8个键/值头,从而将KV缓存消耗降低到标准配置的三分之一。 -
RoPE 机制:
在位置编码方面,采用了分数RoPE配置,确保25%的注意力头维度保持与位置无关,这有助于更平滑地处理长上下文。 -
学习率调度:
为了确定峰值学习率,论文遵循如下公式:
L R ∗ ( D ) = B D − 0.32 , LR^*(D) = B D^{-0.32}, LR∗(D)=BD−0.32,
其中 B B B为常数,通过在训练数据量 D D D为 12.5 B , 25 B , 37.5 B , 50 B 12.5B, 25B, 37.5B, 50B 12.5B,25B,37.5B,50B时调优获得。
2.2 多模态模型部分——Phi-4-Multimodal
-
统一多模态设计:
Phi-4-Multimodal与Phi-4-Mini共享相同的语言模型基础,但通过引入额外的LoRA模块实现多模态扩展。该模型支持单模态文本,也支持文本与图像、语音/音频的组合输入。 -
Mixture of LoRAs:
采用了多模态LoRA混合策略,各模态(例如视觉、语音)各自使用专门的LoRA适配器、编码器和投影器,而基础语言模型参数保持冻结状态。这种设计既保证了语言模型的原始性能,又能高效融入额外模态信息。 -
视觉模块:
- 使用基于SigLIP-400M的图像编码器(经过LLM2CLIP微调)处理448×448分辨率的图像。
- 配合一个两层MLP投影器将视觉特征映射到与文本嵌入相同的维度。
- 附加的视觉适配器LoRA引入约370M参数,整体视觉模块(编码器+投影器)大约占用440M参数。
-
语音/音频模块:
- 输入为80维log-Mel滤波器组特征,帧率10ms。
- 使用3层卷积和24个Conformer块构成音频编码器(1024维注意力、1536维前馈、16个注意力头),经卷积降采样后得到约80ms的token率。
- 两层MLP投影器将1024维音频特征映射到3072维,与文本嵌入一致。
- 语音适配器LoRA( L o R A A LoRA_A LoRAA)应用于所有注意力和MLP层,rank设置为320,音频模块整体大约占460M参数(编码器和投影器)及额外460M参数( L o R A A LoRA_A LoRAA)。
-
训练pipeline:
多模态训练分为以下阶段:- 视觉训练:分为投影器对齐、联合视觉训练、生成视觉语言训练以及多帧训练四个阶段;
- 语音/音频训练:采用预训练(大规模ASR数据)和后训练两个阶段;
- 视觉-语音联合训练:在视觉后训练和语音后训练后,冻结基础语言模型和语音模块,微调视觉适配器以协调视觉与语音间的信息。
-
推理加速策略:
针对长时间序列文本提示计算成本较高的问题,论文提出“最后token嵌入存储”策略。具体来说,通过设计使得每个提示的最后一个token能够浓缩最关键信息,然后只传递该最后token用于后续对齐与预测,从而大幅降低计算成本并加速推理。
3. 数据与训练
3.1 语言训练数据
3.1.1 预训练数据
- 数据过滤:使用增强版质量分类器对多语言、多领域数据进行清洗,确保数据质量;
- 数学与编程数据:特别构建指令化数学与编程数据集,提升在复杂推理任务上的表现;
- 合成数据:引入Phi-4合成数据,并进行严格的去污处理;
- 数据混合:通过消融实验调优数据混合比例,尤其提高了推理数据的比例。
最终构建了一个规模达5万亿( 5 T 5T 5T)tokens的预训练数据集,比前代数据更大、质量更高。
3.1.2 后训练数据
- 包括大量函数调用、摘要生成以及指令跟随数据,进一步增强模型的指令执行能力;
- 在代码任务上,使用丰富的代码补全数据,提高模型对上下文的理解与生成能力。
3.1.3 推理数据
- 通过生成大量合成Chain-of-Thought数据,并采用规则和模型联合的拒绝采样机制过滤错误生成,同时构建了300K条基于DPO训练的偏好数据,用于进一步提升推理性能。
3.2 多模态训练数据
- 视觉语言数据:包含图像文本混合文档、图像-文本对、图像标注数据以及OCR数据等,总计约 0.5 T 0.5T 0.5T tokens用于预训练,SFT阶段使用约 0.3 T 0.3T 0.3T tokens数据;
- 视觉语音数据:利用现有视觉语言SFT数据的子集,通过文本转语音(TTS)技术转换生成语音数据,确保多模态数据一致性;
- 语音/音频数据:预训练阶段采用大规模ASR数据(约2M小时的语音-文本对),后训练阶段采集了覆盖ASR、AST、语音问答、语音摘要等任务的数据,总体构成了丰富的语音指令数据。
4. 实验与评估
论文在多个任务和数据集上对Phi-4系列模型进行了广泛评估,主要包括以下几个方面:
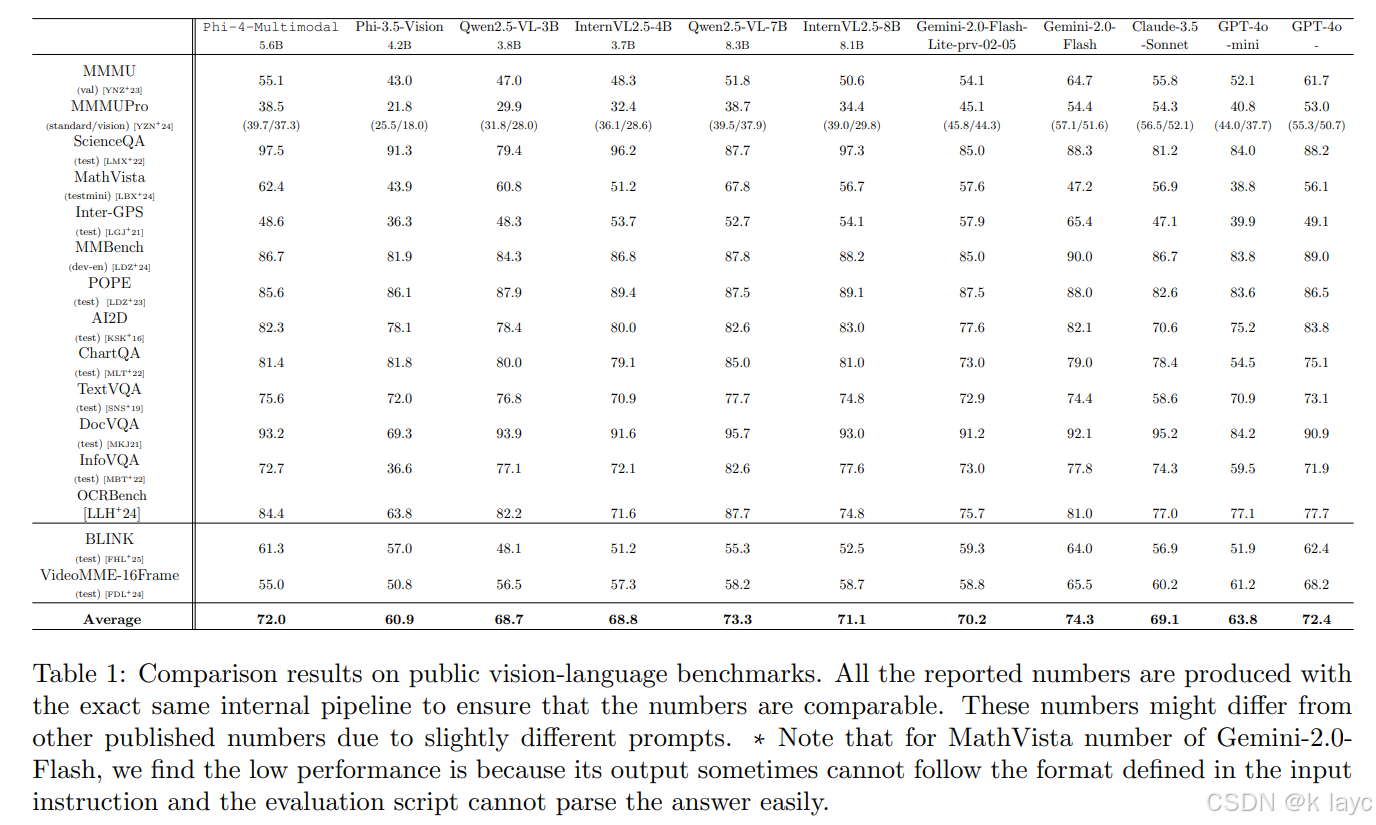
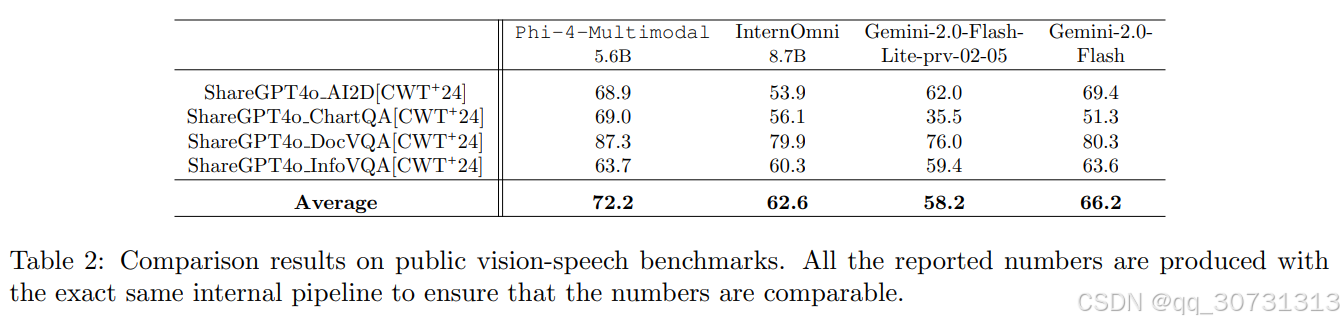
4.1 视觉与多模态评估
-
视觉语言基准:论文评估了Phi-4-Multimodal在13个单图视觉语言任务、2个多图/视频任务以及4个视觉-语音任务上的表现,并与Phi-3.5-Vision、Qwen2.5-VL、InternVL系列、以及私有模型(如Gemini、GPT-4o等)进行对比。结果显示,Phi-4-Multimodal在图表理解、科学推理等任务上甚至超越了部分私有模型。
-
多模态对齐优势:利用冻结的基础语言模型和额外的LoRA模块,Phi-4-Multimodal既保留了强大的语言生成能力,又通过“Mixture of LoRAs”实现了各模态间的高效融合,降低了跨模态干扰。
4.2 语音与音频评估

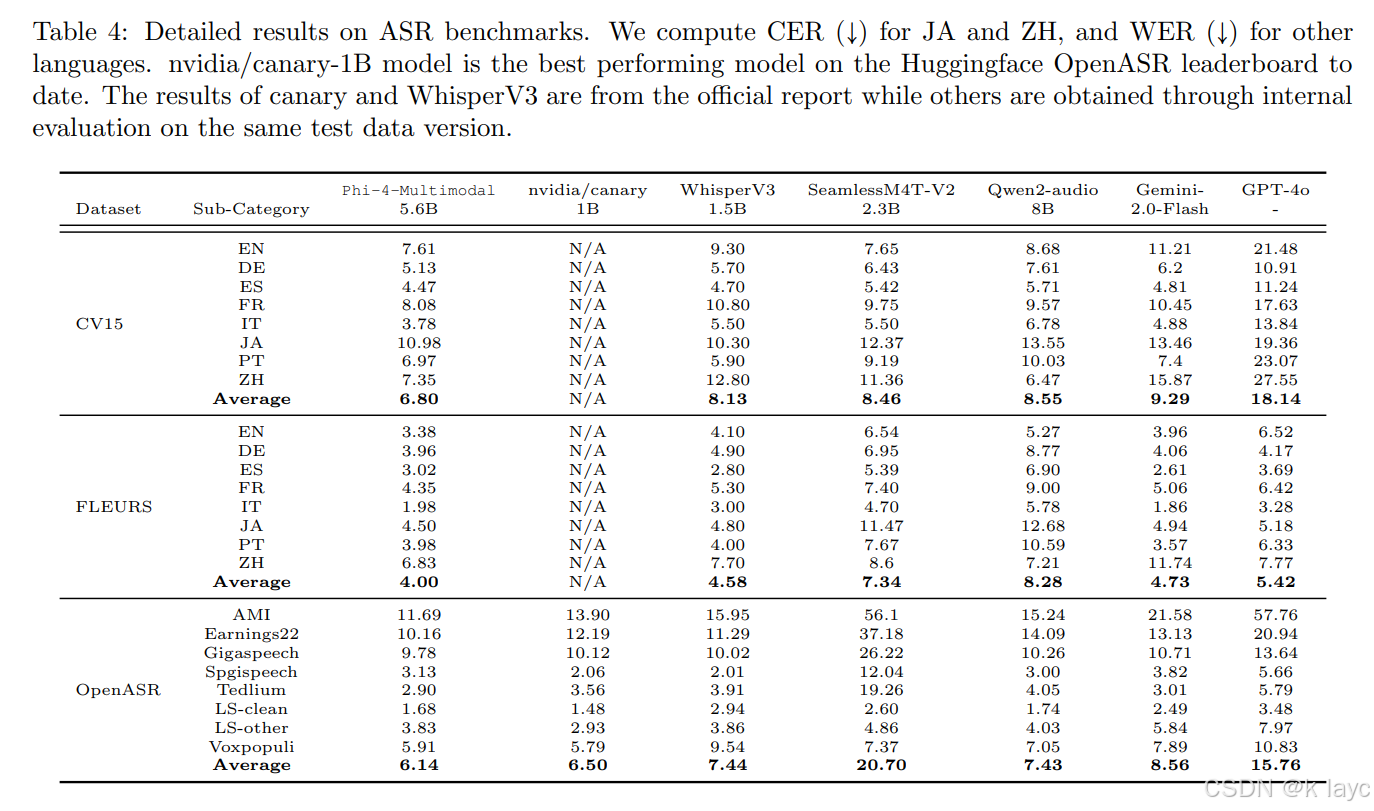
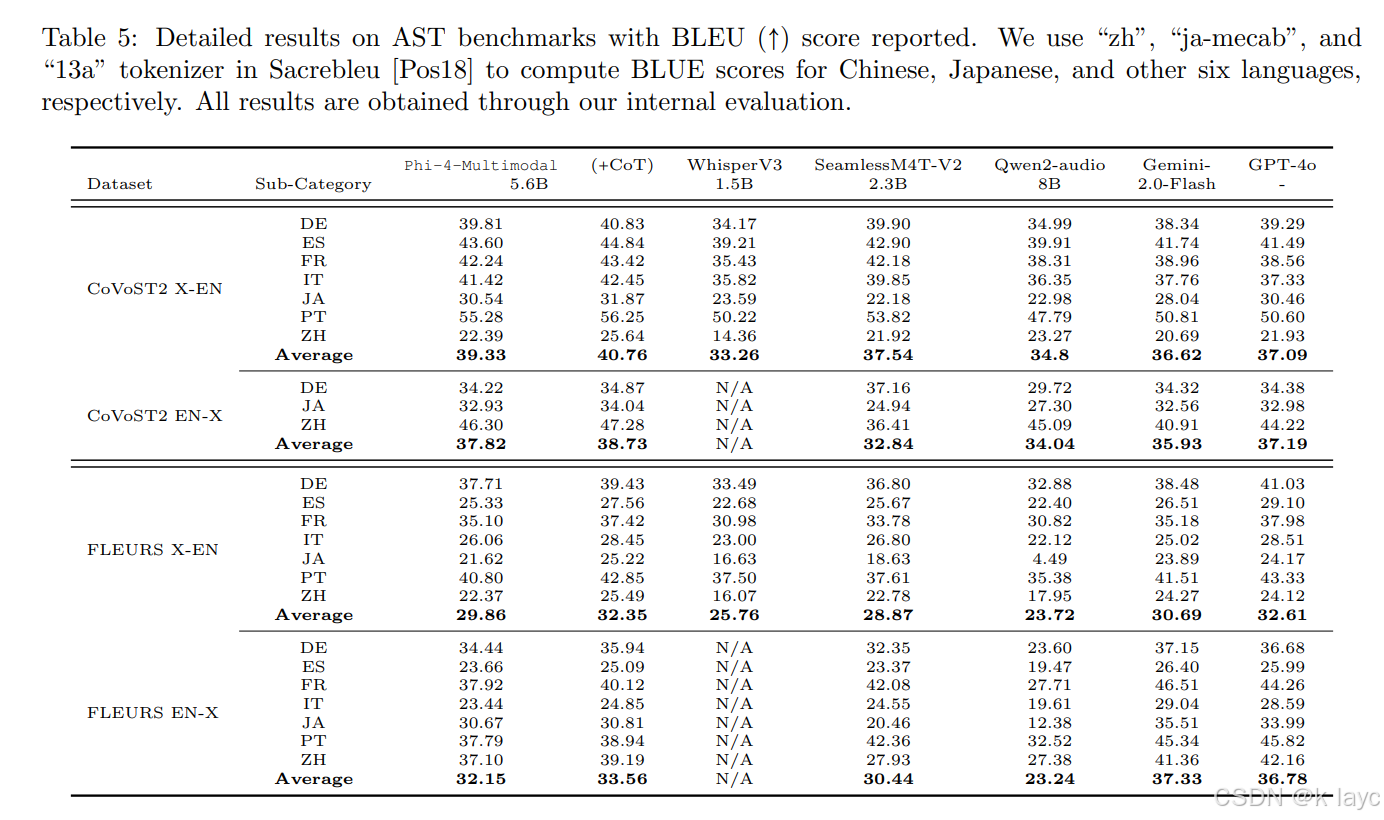
-
ASR与AST:在CommonVoice、FLEURS、OpenASR等公开基准上,Phi-4-Multimodal在自动语音识别(ASR)和自动语音翻译(AST)任务上均取得了领先表现,WER相比于专家模型WhisperV3有明显改善,并在OpenASR排行榜上排名第一。
-
语音问答与摘要:该模型在语音问答(SQQA)和语音摘要任务上也展示出较强的能力,虽然在SQQA上与部分大型模型存在差距,但已明显优于开源的Qwen2-audio。
4.3 语言理解与推理评估
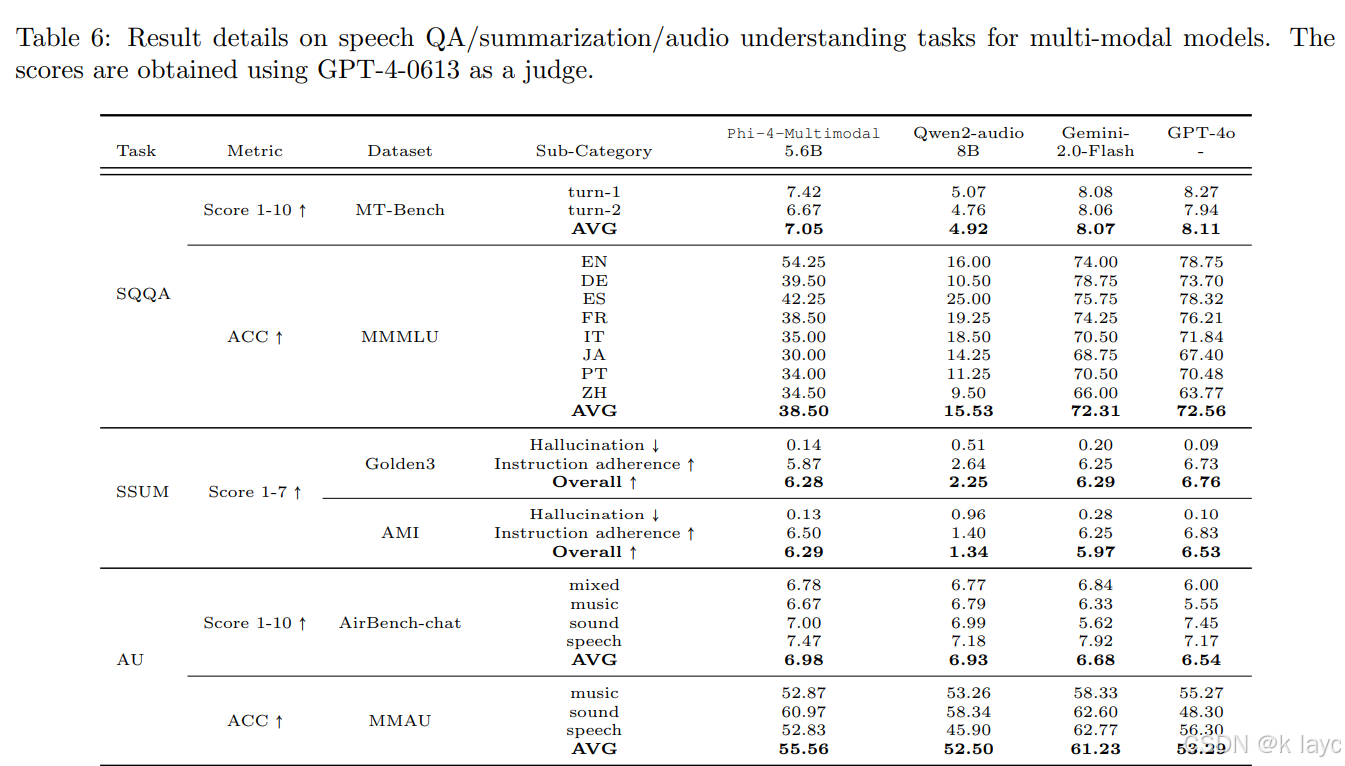
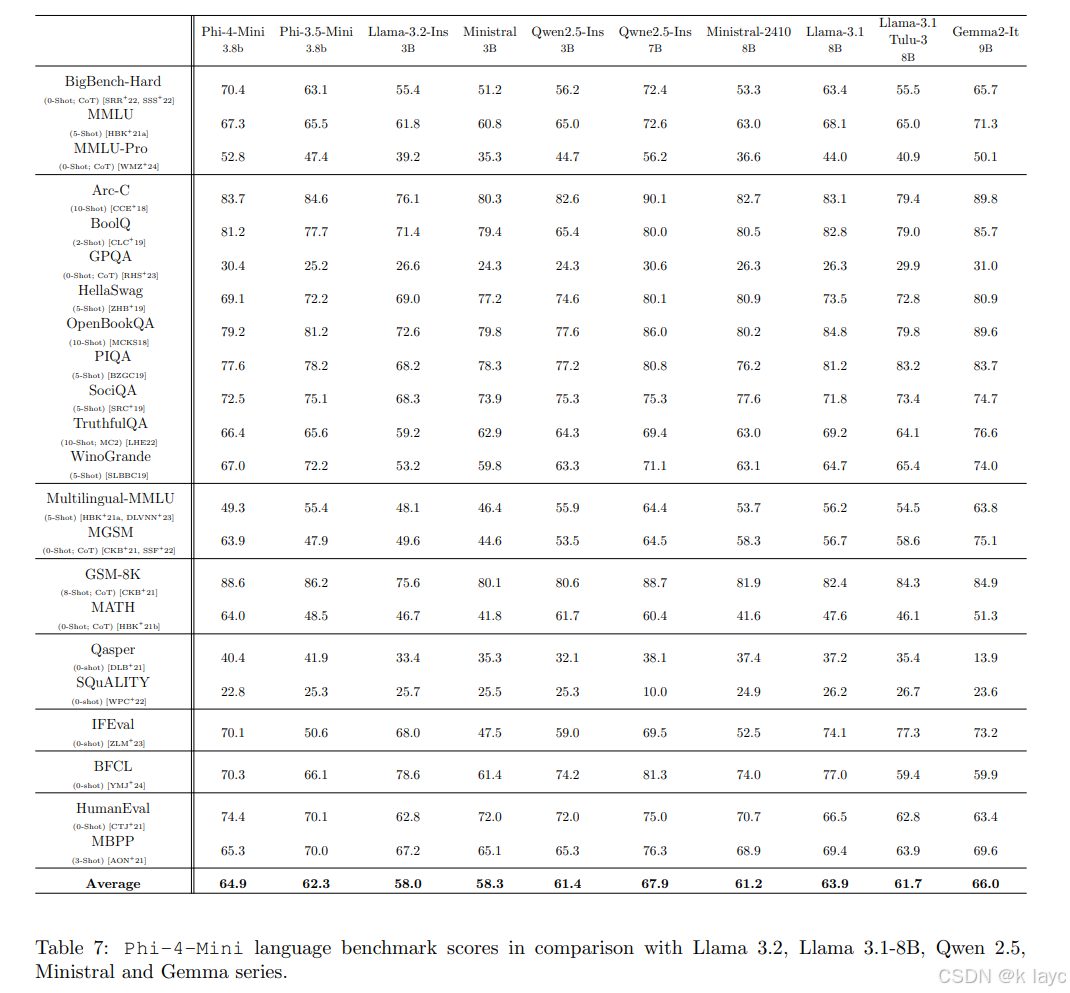
- 多语言与推理任务:Phi-4-Mini在BigBench、MMLU、数学、推理等任务上表现出色,尤其在数学和复杂推理任务上得益于高质量的推理数据,其表现往往超越同尺寸或甚至是规模更大的模型。
5. 结论
论文的主要贡献可以归纳为:
- 统一多模态支持:通过“Mixture of LoRAs”策略,在保持基础语言模型冻结的前提下,实现了文本、图像与语音/音频的高效融合,解决了多模态任务中不同信号之间的干扰问题。
- 紧凑但强大的语言能力:Phi-4-Mini虽然只有3.8B参数,但凭借高质量的预训练数据和精细的数据混合策略,在语言理解、数学推理和代码生成等任务上均展现出与大模型相媲美甚至超越的性能。
- 多模态扩展与推理:Phi-4-Multimodal不仅在视觉、语音任务上表现卓越,还能保持原有的语言模型性能,其模块化设计和动态多裁剪策略使其在处理不同分辨率图像时既高效又准确。
- 高效推理与训练优化:通过“最后token嵌入存储”策略大幅降低计算成本,加速了推理过程;同时,在各模态数据预训练、后训练及联合训练上采用多阶段训练策略,确保模型在各个任务上均有稳健表现。
论文证明了即使在参数较小的情况下,借助精心设计的数据预处理、数据混合和模态适配策略,也可以构建出既紧凑又功能强大的多模态模型,对学术界和工业界均具有重要意义。
6. 关键公式
-
学习率调度公式:
L R ∗ ( D ) = B ⋅ D − 0.32 LR^*(D) = B \cdot D^{-0.32} LR∗(D)=B⋅D−0.32
其中, B B B为调优常数, D D D为训练tokens总数。 -
输入变换(反转嵌入):
H T = W e X T + b e H_T = W_e X_T + b_e HT=WeXT+be
其中 X T ∈ R T × N X_T\in \mathbb{R}^{T \times N} XT∈RT×N表示输入的多变量时间序列, W e W_e We和 b e b_e be为可学习参数, H T ∈ R C × N H_T \in \mathbb{R}^{C \times N} HT∈RC×N为得到的嵌入矩阵。 -
多头自注意力及残差连接:
H T i = M H S A ( LN ( H T i ) ) + H T i H^i_T = MHSA(\text{LN}(H^i_T)) + H^i_T HTi=MHSA(LN(HTi))+HTi
Attention ( H T i ) = softmax ( H T i H T i T d k ) H T i \text{Attention}(H^i_T) = \text{softmax}\left(\frac{H^i_T {H^i_T}^T}{\sqrt{d_k}}\right) H^i_T Attention(HTi)=softmax(dkHTiHTiT)HTi -
最终预测函数:
X ^ M = W p H ^ C + b p \hat{X}_M = W_p \hat{H}_C + b_p X^M=WpH^C+bp
其中 X ^ M ∈ R M × N \hat{X}_M\in \mathbb{R}^{M \times N} X^M∈RM×N为预测输出, H ^ C \hat{H}_C H^C为经过多模态对齐和解码后得到的时间序列嵌入, W p W_p Wp和 b p b_p bp为投影层参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









