






论文链接:https://arxiv.org/pdf/2406.01638
1. 摘要
-
研究目标
本文针对多变量时间序列预测(Multivariate Time Series Forecasting,MTSF)任务,提出了一种新型框架 TimeCMA,通过跨模态对齐(Cross-Modality Alignment)充分利用大语言模型(LLMs)的强大表示能力,从而提升时间序列预测的鲁棒性和精度。 -
核心思想
- 利用双模态编码:
- 一条分支专门对时间序列数据进行编码,得到“解耦”但较弱的时间序列嵌入。
- 另一条分支通过将时间序列数据包装成文本提示,利用预训练的 LLM 获得“纠缠”但鲁棒的提示嵌入。
- 通过跨模态对齐模块,从提示嵌入中“检索”出既解耦又鲁棒的时间序列特征,融合两者“各取所长”。
- 针对计算成本问题,设计了一种“最后 token 存储”策略,只保留每个提示的最后一个 token 用于下游预测,从而大幅降低计算开销与推理延迟。
- 利用双模态编码:
-
实验结果
在 8 个真实数据集上的大量实验表明,TimeCMA 超越了现有的 SOTA 方法,无论是在预测精度(MSE、MAE)还是在计算效率上都有显著优势。
2. 背景与动机
-
多变量时间序列预测的重要性
多变量时间序列数据广泛存在于交通、环境、金融等领域。通过挖掘变量间的时序动态,可以为投资决策、天气预报等提供支持。
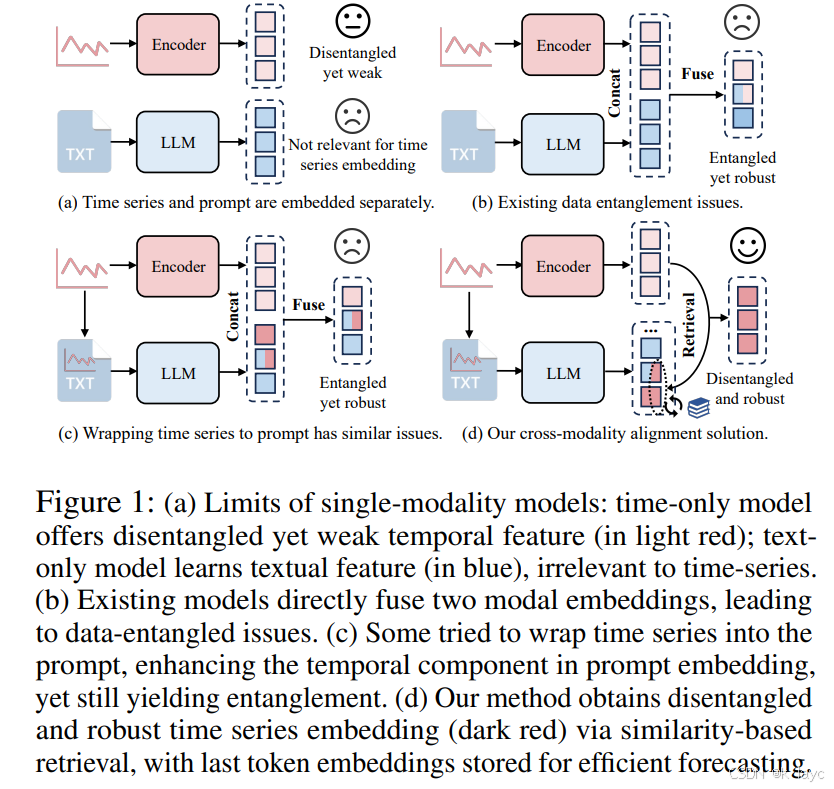
-
传统方法的局限
- 统计方法与深度学习模型:参数较少、训练数据规模有限,难以捕捉复杂动态。
- LLM-based 方法:近来尝试将 LLM 与时间序列结合,通过文本提示提升预测性能。但两类方法存在各自问题:
- 时间序列-based LLMs:使用随机初始化的嵌入层处理时间序列,往往因数据量有限而导致嵌入质量较弱。
- Prompt-based LLMs:将时间序列包装成文本提示,虽然能利用 LLM 的强大语义知识,但直接拼接得到的嵌入容易出现“纠缠”问题,噪声干扰较大,从而影响预测效果。
-
数据纠缠问题
现有方法通常将“解耦”的时间序列嵌入和“鲁棒”的文本提示嵌入直接拼接,导致混合后的表示既保留了弱的时间信息,也夹杂了噪声,进而降低了预测性能。
3. 方法论
TimeCMA 的设计主要包括三个模块:双模态编码、跨模态对齐以及时间序列预测。
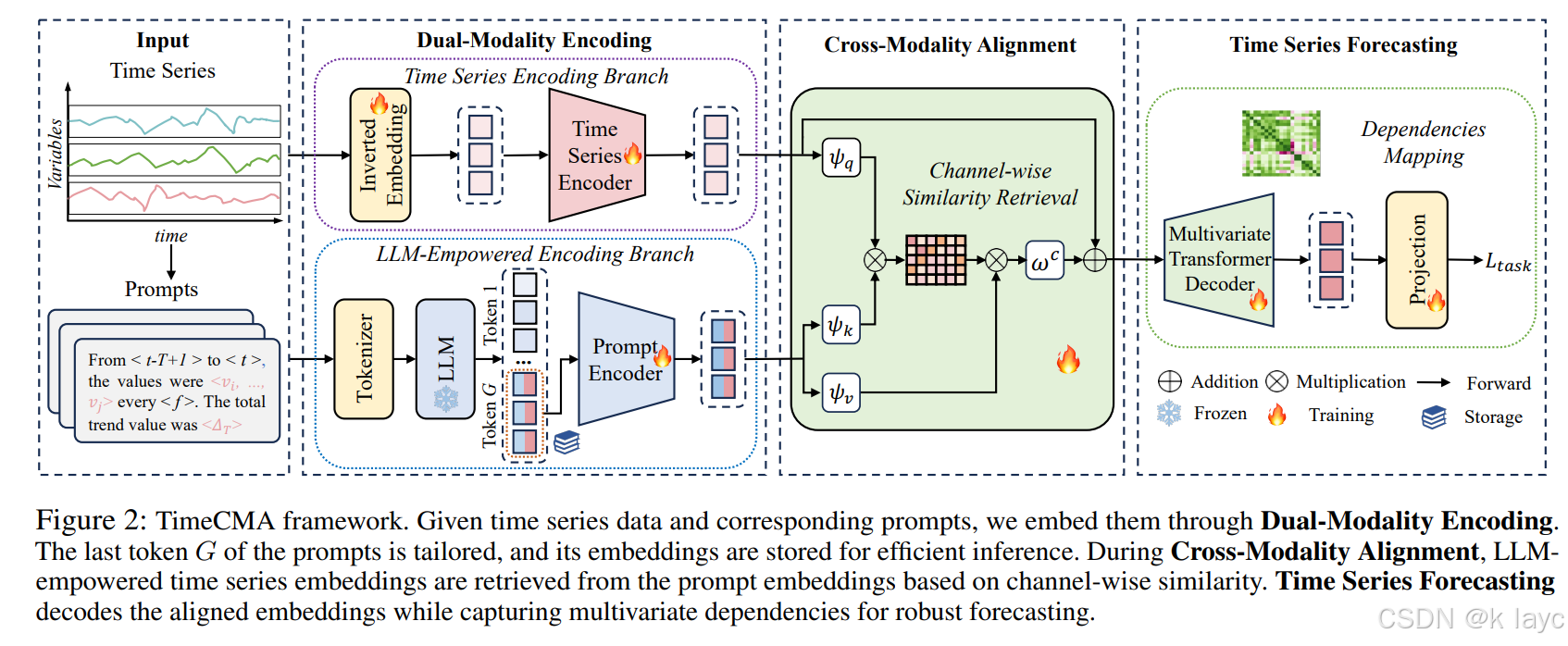
3.1 双模态编码
3.1.1 时间序列编码分支
-
预处理与归一化
将输入的多变量时间序列数据 X ∈ R L × N X \in \mathbb{R}^{L \times N} X∈RL×N 进行归一化处理(零均值、单位方差),以缓解分布偏移问题。 -
Inverted Embedding
利用可学习的参数将整个时间序列看作一个 token,得到变量嵌入:
H T = W e X T + b e H_T = W_e X_T + b_e HT=WeXT+be
其中, W e W_e We 和 b e b_e be 为可学习参数, H T ∈ R C × N H_T \in \mathbb{R}^{C \times N} HT∈RC×N 表示时间序列的嵌入矩阵。 -
时间序列编码器
采用 Pre-LN Transformer 架构对 H T H_T HT 进行编码。具体步骤包括:- 层归一化:
H ~ i T = L N ( H i T ) \tilde{H}_i^T = LN(H_i^T) H~iT=LN(HiT)
其中, L N ( ⋅ ) LN(\cdot) LN(⋅) 由可学习参数 γ \gamma γ 和 β \beta β 调整:
L N ( H i T ) = γ ⊙ H i T − μ σ + β LN(H_i^T) = \gamma \odot \frac{H_i^T - \mu}{\sigma} + \beta LN(HiT)=γ⊙σHiT−μ+β - 多头自注意力(MHSA):
H i T = M H S A ( H ~ i T ) + H i T H_i^T = MHSA(\tilde{H}_i^T) + H_i^T HiT=MHSA(H~iT)+HiT - 前馈网络(FFN)与残差连接:
H i + 1 T = F F N ( L N ( H i T ) ) + H i T H_{i+1}^T = FFN(LN(H_i^T)) + H_i^T Hi+1T=FFN(LN(HiT))+HiT
FFN 的形式为:
F F N ( H i T ) = max ( 0 , W 1 H i T + b 1 ) W 2 + b 2 FFN(H_i^T) = \max(0, W_1 H_i^T + b_1)W_2 + b_2 FFN(HiT)=max(0,W1HiT+b1)W2+b2
- 层归一化:
3.1.2 LLM-赋能编码分支
-
文本提示包装
将相同的时间序列数据包装成文本提示 P S ∈ R S × N P_S \in \mathbb{R}^{S \times N} PS∈RS×N,其中包含时间信息(如时间戳、频率)以及数值信息。 -
预训练 LLM
使用 GPT-2 模型处理提示文本,模型参数均被冻结。通过分词器将文本转为 token 序列,并生成提示嵌入:
P G = Tokenizer ( P S ) P_G = \text{Tokenizer}(P_S) PG=Tokenizer(PS)
随后通过 GPT-2 得到嵌入:
P G ( i + 1 ) = F F N ( L N ( P G ( i ) ) ) + P G ( i ) P_G^{(i+1)} = FFN(LN(P_G^{(i)})) + P_G^{(i)} PG(i+1)=FFN(LN(PG(i)))+PG(i)
其中, P G ( 0 ) = P G + P E P_G^{(0)} = P_G + P_E PG(0)=PG+PE( P E P_E PE 为位置编码)。 -
最后 Token 存储
为降低计算成本,设计提示使得最后一个 token 能够捕捉最关键的时间序列信息,并将其表示存储下来用于后续对齐与预测。
3.2 跨模态对齐模块
-
目标
利用跨模态对齐将时间序列分支生成的嵌入 H T H_T HT 与 LLM 分支的提示嵌入 L N L_N LN 进行融合,从而提取出既解耦又鲁棒的时间序列特征。 -
线性变换与相似性计算
对 H T H_T HT 和 L N L_N LN 分别通过三个线性层转换:
ψ q ( H T ) , ψ v ( L N ) , ψ k ( L N ) \psi_q(H_T),\quad \psi_v(L_N),\quad \psi_k(L_N) ψq(HT),ψv(LN),ψk(LN)
然后计算通道级相似性矩阵:
M T = F s o f t m a x ( ψ q ( H T ) ⊗ ψ k ( L N ) ) M_T = F_{softmax}(\psi_q(H_T) \otimes \psi_k(L_N)) MT=Fsoftmax(ψq(HT)⊗ψk(LN))
其中, ⊗ \otimes ⊗ 表示矩阵乘法。 -
特征聚合
利用相似性矩阵将提示嵌入中的鲁棒时间序列信息聚合回来,并与原始时间序列嵌入相加:
H C = ω c ( ψ v ( L N ) ⊗ M T ) ⊕ H T H_C = \omega_c (\psi_v(L_N) \otimes M_T) \oplus H_T HC=ωc(ψv(LN)⊗MT)⊕HT
其中, ω c \omega_c ωc 为线性层, ⊕ \oplus ⊕ 表示矩阵加法。
3.3 时间序列预测模块
-
Transformer 解码器
将融合后的嵌入 H C H_C HC 输入到多变量 Transformer 解码器 M T D e c o d e r ( ⋅ ) MTDecoder(\cdot) MTDecoder(⋅) 中,捕捉不同变量之间的长期依赖关系。 -
预测投影
最后使用投影函数生成未来 M M M 个时刻的预测:
X ^ M = W p H ^ C + b p \hat{X}_M = W_p \hat{H}_C + b_p X^M=WpH^C+bp
其中 H ^ C \hat{H}_C H^C 为解码器输出, W p W_p Wp 和 b p b_p bp 为投影层参数。
3.4 总体目标函数
-
预测损失
使用均方误差 (MSE) 作为预测损失:
L p r e = 1 M ∑ i = 1 M ( X ^ M − X M ) 2 L_{pre} = \frac{1}{M} \sum_{i=1}^{M} (\hat{X}_M - X_M)^2 Lpre=M1i=1∑M(X^M−XM)2 -
正则化损失
加入 L2 正则化损失 L r e g L_{reg} Lreg 以防止过拟合。 -
总损失
最终目标函数为:
L t a s k = L p r e + λ L r e g L_{task} = L_{pre} + \lambda L_{reg} Ltask=Lpre+λLreg
其中 λ \lambda λ 是用于平衡两部分损失的超参数。
4. 实验设计与结果
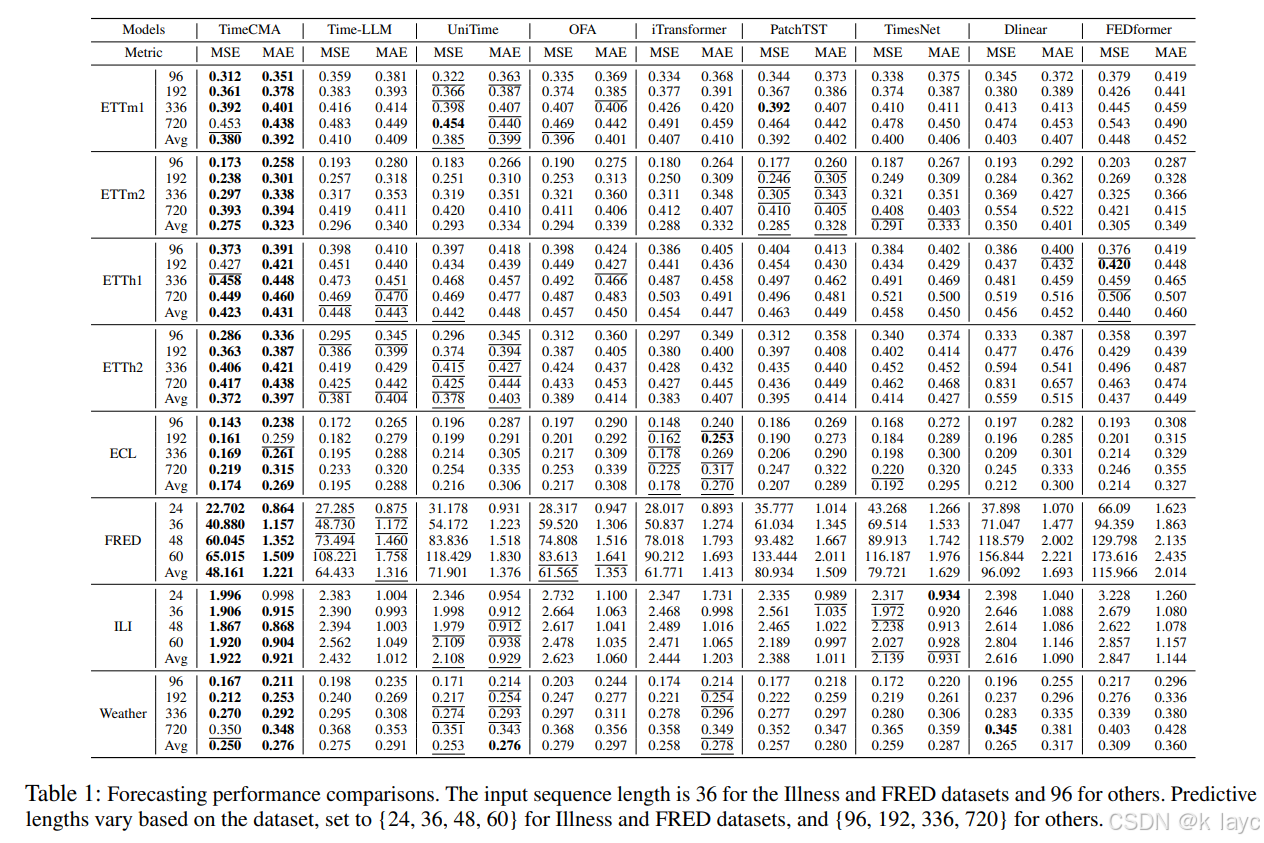
4.1 数据集与基线
-
数据集:
实验在 8 个真实数据集上进行,包括 ETTm1、ETTm2、ETTh1、ETTh2、ECL、FRED、ILI 和 Weather 数据集。 -
基线方法:
包括:- Prompt-based LLMs(如 Time-LLM、UniTime)
- 时间序列-based LLM(如 OFA)
- Transformer-based 模型(iTransformer、PatchTST、FEDformer)
- 线性方法(Dlinear)
- CNN-based 方法(TimesNet)
-
评价指标:
使用均方误差 (MSE) 和平均绝对误差 (MAE) 作为主要评价指标。
4.2 主要实验结果
-
总体表现:
TimeCMA 在所有数据集上均优于现有基线方法,证明了其对多变量时间序列预测的有效性。 -
关键对比:
- LLM-based 方法优于传统方法:利用 LLM 的丰富知识和大规模预训练数据,TimeCMA 通过跨模态对齐有效提升了预测精度。
- Prompt-based 优于时间序列-only 方法:引入文本提示后,TimeCMA 的表现相比纯时间序列模型(如 OFA)提升了约 16.1%(MSE 改进)和 11.9%(MAE 改进)。
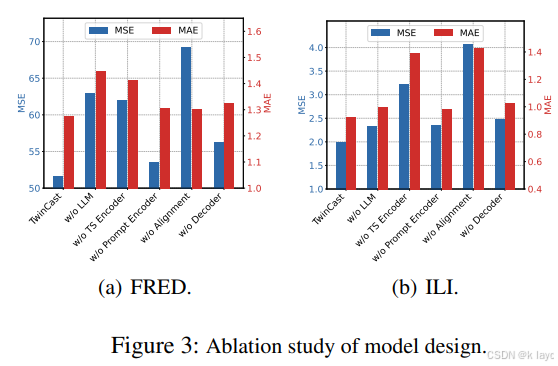
- 消融实验:
- 移除跨模态对齐(w/o Alignment)后性能显著下降,证明了该模块在融合“解耦”与“鲁棒”特征中的关键作用。
- 移除 LLM 赋能分支(w/o LLM)和时间序列编码器(w/o TS Encoder)同样会导致预测性能的下降。
4.3 效率分析
-
最后 Token 存储:
通过将提示的最后 token 表示提取并存储,仅用该部分进行下游对齐与预测,大幅降低了计算开销和推理延迟。 -
实验对比:
与传统 Time-LLM 和 OFA 方法相比,TimeCMA 在参数量、内存占用和推理速度上均有优势。例如,在 ETTm1 数据集上,TimeCMA 显示出更低的参数和内存使用,同时推理速度更快。
4.4 注意力与可视化分析
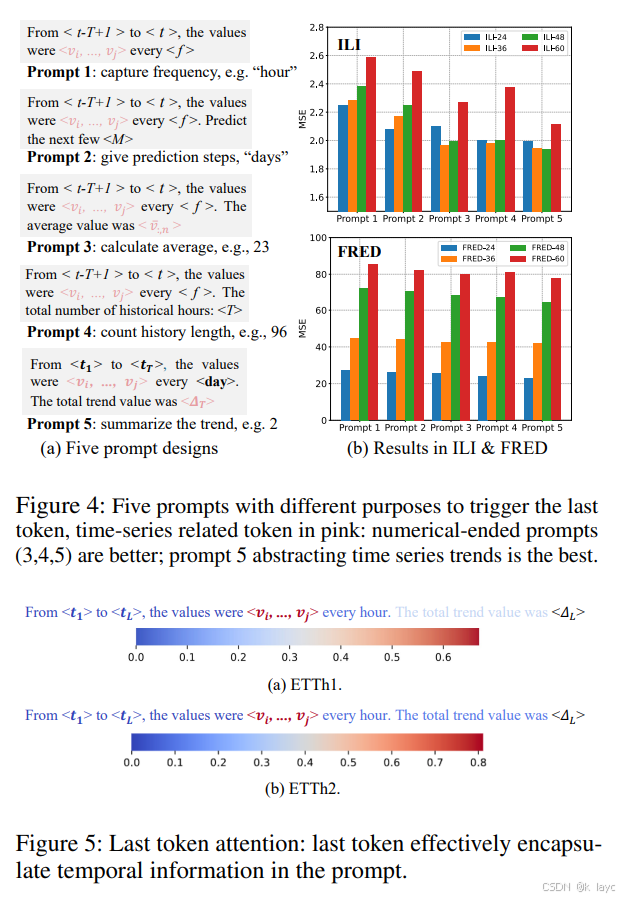
-
注意力机制:
可视化分析显示,Transformer 编码器(用于时间序列)主要捕捉局部、变量特异性的时序依赖,而 LLM 编码器(处理提示文本)则捕捉全局变量之间的依赖。两者互补的特性通过跨模态对齐得以有效融合。
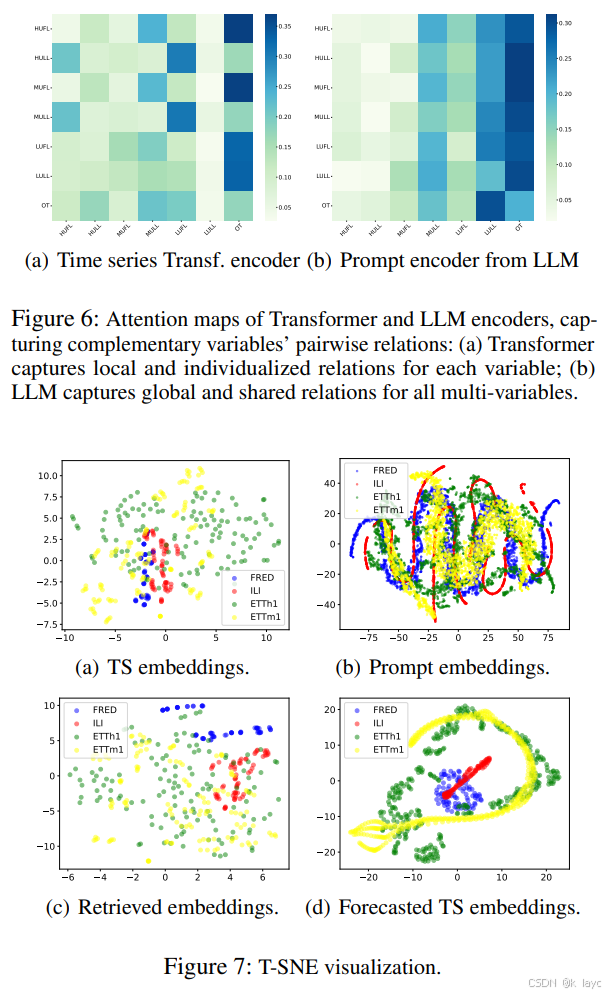
-
T-SNE 可视化:
T-SNE 分析展示了:- 时间序列嵌入在不同数据集之间形成较为清晰的聚类;
- 提示嵌入显示出更复杂的交互关系;
- 经过对齐后的预测嵌入形成了分布良好的聚类,证明了模型的投影函数能够有效利用检索到的跨模态特征。
5. 结论与讨论
-
主要贡献:
- 提出了一种全新的 LLM-赋能多变量时间序列预测框架 TimeCMA,通过跨模态对齐实现“解耦且鲁棒”的时间序列嵌入。
- 设计了双模态编码分支,其中时间序列编码器利用 Inverted Embedding 和 Pre-LN Transformer 捕捉局部时序特征,而 LLM 赋能分支通过文本提示捕捉全局信息。
- 利用跨模态对齐模块,通过线性变换与通道级相似性检索,从提示嵌入中提取出更优质的时间序列特征。
- 引入“最后 token 存储”策略,大幅降低计算成本与推理延迟,提升了模型在实际应用中的效率。
- 在 8 个真实数据集上的实验验证了 TimeCMA 在预测精度(MSE、MAE)以及计算效率上的显著优势。
-
局限性与未来工作:
- 当前框架在跨模态对齐部分依赖于预训练 LLM(如 GPT-2)和特定的提示设计,未来可探索更多自适应对齐策略。
- 针对更长时间序列和更多变量的数据,如何进一步优化 Transformer 结构以捕捉复杂依赖关系仍需深入研究。
- 实验中使用的多个数据集均为公开数据集,未来可尝试在更多真实工业场景下验证模型的泛化能力。
6. 总结
论文 TimeCMA: Towards LLM-Empowered Multivariate Time Series Forecasting via Cross-Modality Alignment 提出了一种创新性的框架,通过双模态编码、跨模态对齐和高效的预测策略,实现了从大量文本提示中提取高质量时间序列特征。该方法不仅有效提升了多变量时间序列预测的准确率(通过显著降低 MSE 和 MAE),还通过最后 token 存储策略大幅降低了计算成本与推理延迟。大量实验结果表明,TimeCMA 在多个数据集上均超越现有最先进方法,展示了 LLM 在时间序列领域的巨大潜力。

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









