






论文链接:https://arxiv.org/pdf/2502.05177
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy
1. 简介
-
背景与动机
- 近年来,多模态大模型(LMMs)正迅速发展,将大语言模型(LLMs)的能力扩展到视觉、视频及文本等多模态信息处理上。
- 现有开源模型大多聚焦于静态图像和短视频,而专有模型(如 Gemini 1.5 pro)已实现长达 1 M 1M 1M tokens 的处理能力,以及同时处理长视频(高达数千帧)的能力。
- 因此,如何在开源领域实现长上下文(long-context)多模态理解成为亟待解决的问题,Long-VITA 正是在这一背景下提出的。
-
论文目标
- 提出 Long-VITA 模型,该模型能够同时处理图像、视频与文本,支持高达 1 M 1M 1M tokens 的长上下文处理,且在短上下文任务上依然保持领先性能。
- 利用全开放数据构建模型,并通过一系列创新设计实现推理时的高效扩展与加速。
2. 主要贡献
-
开放性与高效性
- Long-VITA 完全基于开源数据(约 17M 样本)训练,不依赖内部数据,并支持 NPU 与 GPU 平台,具有极高的复现性。
-
四阶段训练策略
- 从预训练的大语言模型出发,经过视觉-语言对齐、通用知识学习、以及两阶段的长序列微调(分别扩展到 128 K 128K 128K 和 1 M 1M 1M 上下文),逐步增强模型的长上下文处理能力。
-
推理阶段创新设计
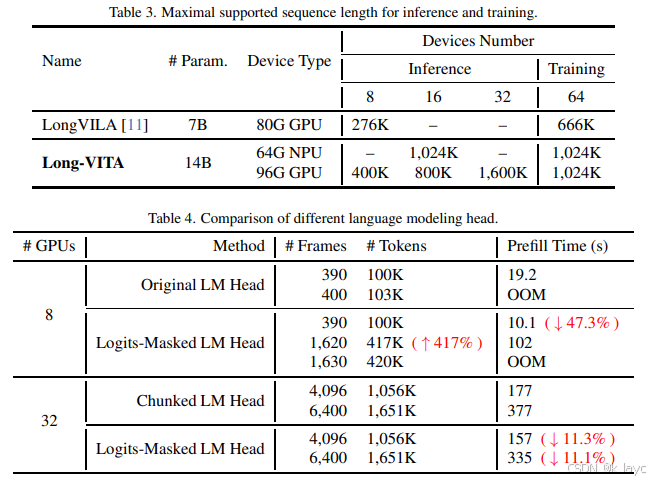
- 实现了上下文并行(context-parallelism)分布式推理,支持无限长输入;
- 引入 logits-masked 语言建模头,大幅降低长上下文推理时的内存消耗。例如,原始 logits 矩阵对 1 M 1M 1M tokens 与 1 0 5 10^5 105 词表需要约 400GB 内存,而经过遮掩后仅需 0.0004 0.0004 0.0004 GB(约 1 0 6 × 1 0 5 10^6 \times 10^5 106×105 缩减)。
-
性能提升
- 在单节点 8 个 GPU 环境下,实现了 2 倍的 prefill 加速以及 4 倍的上下文长度扩展,同时在多项多模态基准测试中表现出色。
3. 相关工作
-
大视觉语言模型(LVLMs)
- 例如 Flamingo、BLIP-2、LLaVA、Qwen-VL 等,这些方法通过连接预训练图像编码器和大语言模型实现多模态任务,但多数关注短上下文任务。
-
长上下文处理技术
- 针对长序列问题,已有方法如 Position Interpolation、YaRN、LongRoPE、LongLoRA 等在文本领域取得进展;在视频领域,部分方法通过视觉 token 压缩或特定架构(如 LongVILA、LongLLaVA、LongVU 等)扩展上下文,但往往牺牲部分性能。
-
本论文定位
- Long-VITA 在保证短上下文高精度的同时,进一步扩展上下文至 1 M 1M 1M tokens,兼顾静态图像和长视频理解,弥补了现有开源模型在长上下文多模态任务上的短板。
4. 方法论
4.1 模型架构
-
整体架构
- 模型主要由三部分构成:
- 视觉编码器(Vision Encoder)
- 采用 InternViT-300M,并引入动态切片(dynamic tiling)策略以适应高分辨率与多种宽高比图像。
- 视觉-语言投射器(Vision-Language Projector)
- 使用两层 MLP 将视觉特征投影到词嵌入空间,同时采用像素重排(pixel shuffle)将视觉 token 数量缩减至原来的四分之一。
- 大语言模型(LLM)
- 选用 Qwen2.5-14B-Instruct,作为生成与理解长上下文的核心模块。
- 视觉编码器(Vision Encoder)
- 模型主要由三部分构成:
-
架构亮点
- 无需采用 token 压缩或稀疏局部注意力(sparse local attention),而是通过全并行设计保证长上下文的充分信息传递。
4.2 数据构建
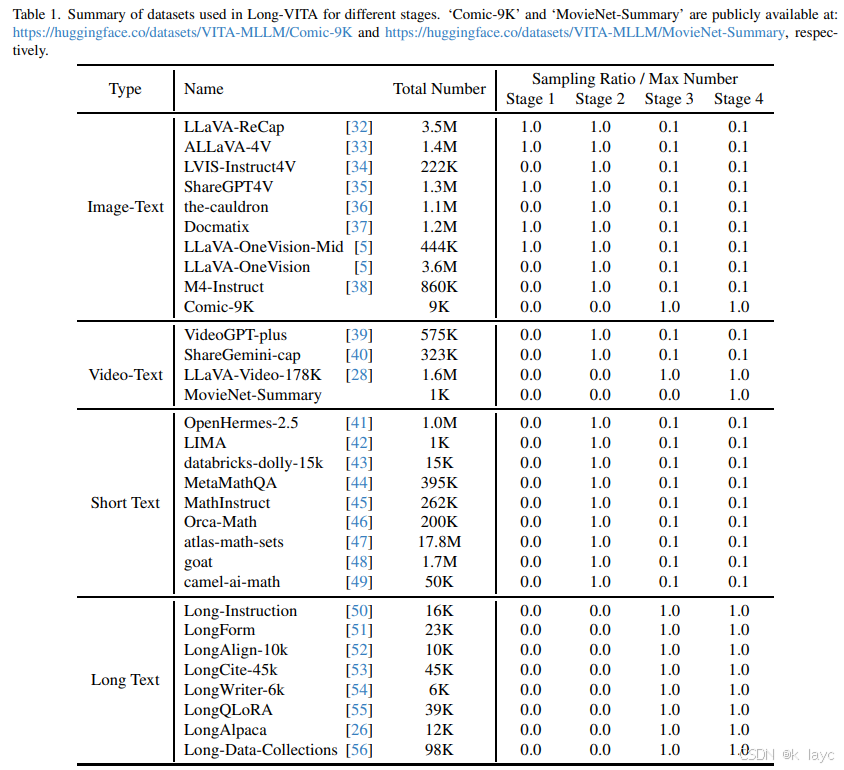
- 多源数据整合
- 数据集涵盖了图像-文本、视频-文本、短文本及长文本四大类,详细配置见论文中的表格(Tab. 1)。
- 图像-文本数据
- 包含图像描述数据(如 LLaVA-ReCap、ALLaVA-4V 等)、视觉问答数据(如 LVIS-Instruct4V、the-cauldron 等)以及 interleaved 多图像数据(Comic-9K 数据集,收录了约 200K 张图像和 9K 本漫画书的详细 synopsis)。
- 视频-文本数据
- 数据来源包括 VideoGPT-plus、ShareGemini-cap、LLaVA-Video-178K 等,同时构建了 MovieNet-Summary 数据集,用于电影级视频理解。
- 短文本与长文本数据
- 短文本数据来源于 OpenHermes-2.5、LIMA 等;长文本数据则选自 Long-Instruction、LongForm、LongAlign-10k 等数据集,用于迁移上下文长度。
4.3 训练流水线
-
四阶段训练
-
Stage 1: 视觉-语言对齐
- 序列长度设定为 32 K 32K 32K,主要利用图像描述数据进行预训练,对齐视觉和文本特征。
- LLM 与视觉编码器均被冻结,仅训练视觉投射器,同时引入 Docmatix 数据以提升文档问答能力。
-
Stage 2: 通用知识学习
- 序列长度降至 16 K 16K 16K,大规模整合图像-文本数据,涵盖图像描述、常规问答、OCR 与多模态对话任务;同时融入纯文本(包含数学题与算术计算)。
- 视频数据在此阶段只包含 VideoGPT-plus 与 ShareGemini-cap。
- 数据通过随机抽样拼接成固定长度( 32 K 32K 32K 或 16 K 16K 16K)的训练样本,重置位置嵌入与注意力 mask,确保各数据段之间独立。
-
Stage 3: 长序列微调
- 上下文长度扩展至 128 K 128K 128K,降低 Stage 2 数据的采样比例至 0.1,并引入更多长文本指令、漫画书摘要以及视频理解数据。
-
Stage 4: 超长序列微调
- 进一步扩展上下文至 1 M 1M 1M(或 1,024K),加入额外的电影摘要数据。此阶段不重置位置嵌入与注意力 mask,迫使模型捕捉跨长序列的信息相关性。
-
-
数据打包策略
- Stage 1 与 2 中数据打包后重置位置嵌入,而 Stage 3 与 4 则保持原有位置关系,适应长上下文信息的连续性。
4.4 超参数与基础设施
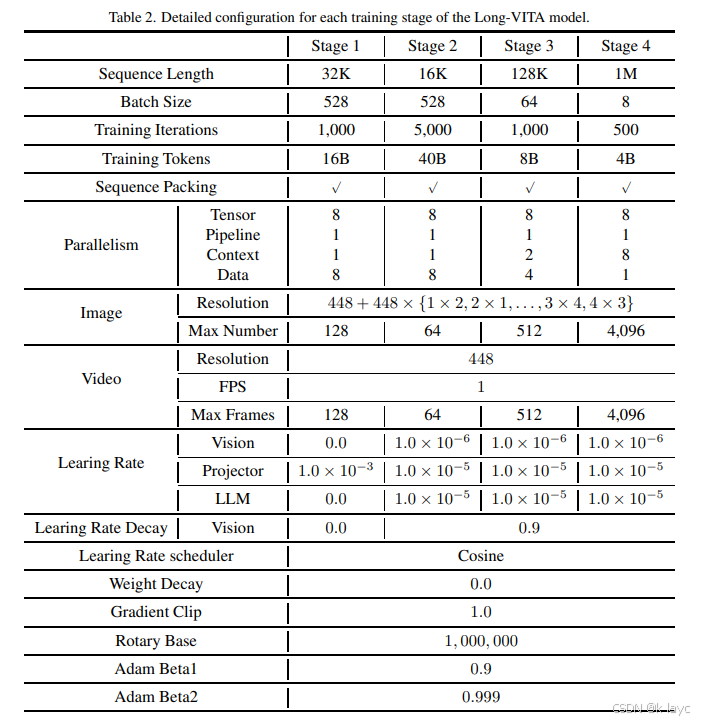
-
训练超参数
- 表 2 中列出了各阶段的详细配置:
- 如 Stage 1:序列长度 32 K 32K 32K, batch size 为 528, 训练迭代 1,000 次,训练 tokens 总数 $16B$;
- Stage 3 与 4 分别使用
128
K
128K
128K 与
1
M
1M
1M 上下文,迭代次数与 batch size 随之调整。
- 表 2 中列出了各阶段的详细配置:
-
并行训练策略
- 采用数据、管道、张量、序列与上下文并行,确保长序列训练时的高效扩展。
- 同时,使用 Ring Attention 分布长序列于多设备上。
-
推理阶段设计
- 上下文并行分布式推理:实现 tensor 并行与上下文并行,固定解码阶段的输出长度,通过 padding 和截断实现无限长输入的生成。
- logits-masked 语言建模头:显著降低输出 logits 矩阵的内存需求(例如,对于 1 M 1M 1M tokens 与词表大小 1 0 5 10^5 105,原始矩阵需要约 400GB,而遮掩后仅需 0.0004 0.0004 0.0004 GB),同时相较于 chunked LM head 提供 11% 左右的加速。
- 推理时温度设为 0,以确保结果稳定可重复。
5. 实验
5.1 图像评估
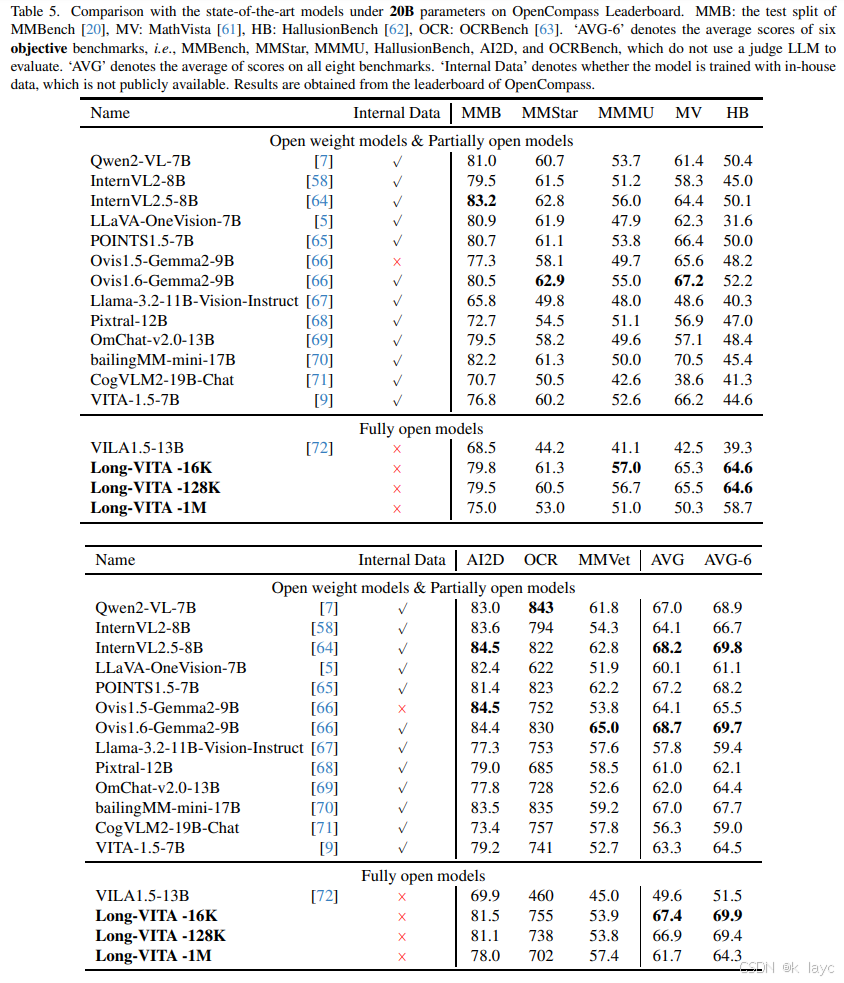
- 评测基准
- 使用 OpenCompass 基准,涵盖图像问答、多模态对话、知识推理、OCR 与幻觉检测等任务。
- 性能表现
- Long-VITA-16K 在大部分图像任务中超过了 Qwen2-VL-7B、InternVL2-8B 等模型,取得了在 MMMU 与 HallusionBench 上的新 SOTA 性能。
- 但在超长上下文(
1
M
1M
1M)训练下,由于数据打包未能隔离 attention mask,性能略逊于 16K 与 128K 模型。
5.2 视频评估
-
评测指标
- 使用 Video-MME 评估视频理解能力,涵盖短、中、长视频(平均时长约 1017 秒)。
-
模型表现
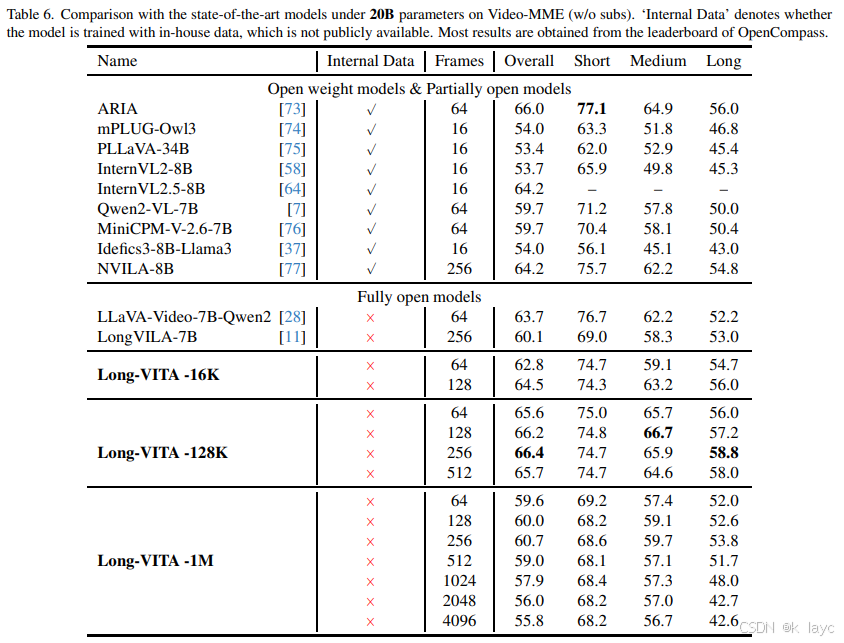
- Long-VITA-128K(输入 256 帧)在 Video-MME 上超越同规模其他模型;
- Long-VITA-1M 支持最多 4096 帧输入,并在不同视频时长的子集上展现出竞争力的表现。
- 同时,模型兼容 slow-fast 与 progressive pooling 策略,可进一步扩展视频上下文。
-
加速与扩展效果
- 在单节点 8 GPU 环境下,Long-VITA 推理阶段实现了 2 倍 prefill 加速和 4 倍上下文长度扩展。
- 在单节点 8 GPU 环境下,Long-VITA 推理阶段实现了 2 倍 prefill 加速和 4 倍上下文长度扩展。
6. 结论
-
研究成果
- Long-VITA 系列模型成功实现了在开源数据条件下的长上下文多模态理解,兼具短上下文高精度与超长上下文处理能力。
- 模型在图像和视频理解多个基准上均表现优异,证明了通过分阶段训练与创新推理设计扩展上下文的可行性与有效性。
-
理论与实践意义
- 为开源多模态模型在长上下文任务上提供了一个有力的竞争基线,同时为后续研究在数据筛选、训练策略和推理优化等方面提供了参考。
7. 限制与未来展望
-
数据筛选
- Long-VITA 训练使用大规模开源数据,但未进行严格过滤,未来可通过数据质量控制进一步提升性能。
-
长上下文训练策略
- 当前超长上下文( 1 M 1M 1M)训练中,数据打包未能有效隔离 attention mask,可能导致信息混杂,未来需要改进训练流水线与数据处理策略。
-
多模态扩展
- 虽然本工作主要针对图像、视频和文本,未来工作可进一步扩展至 3D 点云、音频等更多模态,实现更全面的多模态理解。
8. 参考文献
- 论文中引用了大量相关工作,包括 Flamingo、BLIP-2、LLaVA、Qwen-VL 等多模态模型,以及针对长上下文处理的技术如 YaRN、LongRoPE、LongLoRA 等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









