






论文链接:https://arxiv.org/pdf/2502.12470
1. 文章概述
标题:
Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking
作者:
Alireza S. Ziabari, Nona Ghazizadeh, Zhivar Sourati, Farzan Karimi‐Malekabadi, Payam Piray, Morteza Dehghani
(均来自南加州大学)
研究背景与动机:
- 现有大语言模型(LLMs)在推理任务上展现了很强的能力,但主要依赖类似“链式推理(Chain-of-Thought, CoT)”的结构化、逐步推理方式。
- 然而,人类在面对问题时会根据任务需求在快速直觉(System 1)和慢速、分析(System 2)之间灵活切换。
- 论文的核心思路在于:将LLMs显式对齐到两种不同的认知模式,从而使模型在处理不同类型任务时能在准确性和效率之间取得更优平衡。
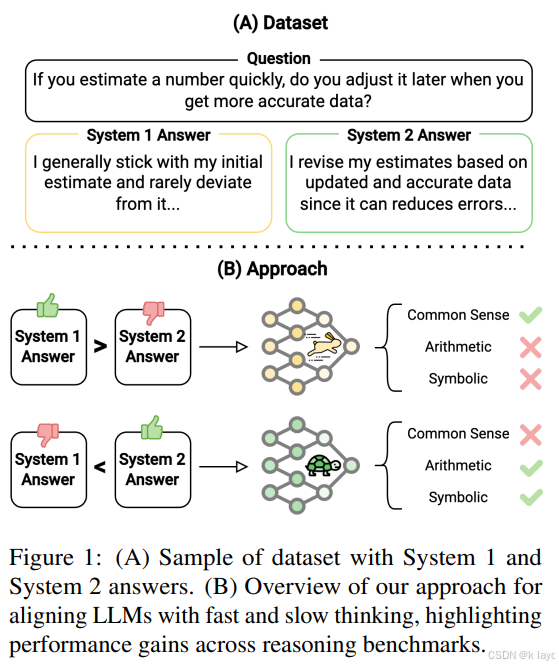
2. 摘要与核心贡献
-
主要发现:
- 利用一个包含2000个问题的双模态数据集,每个问题都配有两种答案——一种体现直觉、启发式的 System 1 答案,另一种体现逐步推理、逻辑严密的 System 2 答案。
- 通过对齐训练,模型在算术和符号推理任务上,System 2 对齐的模型表现更佳;而在常识推理任务中,System 1 对齐的模型则优势明显。
- 实验中还揭示了一个准确性与效率之间的权衡:System 2 模型虽然能提供更精确的多步推理,但生成的答案较长,计算开销更大;System 1 模型则生成更简洁、决断性更强的回答。
-
核心贡献:
- 提出了一种通过偏好对齐框架(preference alignment)引导模型倾向于不同思维模式的方案。
- 利用中间插值方法探索了从 System 1 到 System 2 的平滑过渡,发现各类推理任务中准确率随着两种模式成分的不同呈现出单调变化趋势。
3. 理论背景与相关工作
3.1 人类双过程理论
- System 1:
- 快速、自动、基于启发式的直觉判断,适用于低计算量、需要迅速反应的情景(如闪避危险)。
- System 2:
- 缓慢、刻意、基于逻辑推理的分析过程,适用于复杂、多步推理任务(如解决数学问题)。
- 这一理论在心理学、行为经济学及神经科学中均有大量论证(参见 Kahneman, 2011 等)。
3.2 现有LLMs推理方法
- Chain-of-Thought (CoT) 提示:
- 通过引导模型逐步展开推理过程来提高解题准确率。
- 不过,始终采用结构化推理可能导致在简单问题上产生不必要的冗长解释。
- 论文指出:大部分现有工作都隐含地假设结构化推理(即 System 2)始终最优,而忽视了实际任务中对直觉型推理(System 1)的需求。
4. 方法

4.1 对齐不同思维模式
- 基本思想:
- 将大模型已有的两种推理能力视作内在的“认知工具”,通过训练使模型在生成回答时更倾向于一种特定风格。
- 对齐策略:
- System 1 对齐: 将直觉型、启发式答案视为优胜答案,而将更为分析的答案视为劣势。
- System 2 对齐: 则反之,将详细、逐步推理的答案视为优胜。
4.2 数据集构建
-
数据集特点:
- 共2000个问题,每个问题包含两种回答,分别对应 System 1 和 System 2。
- 涵盖了10种常见认知偏见和启发式,如锚定效应、光环效应、过度自信、乐观偏差、可得性启发、现状偏好、近期偏差、确认偏差、计划谬误和从众效应。
-
构建流程:
-
专家初始示例:
- 专家先选定10个认知偏见类别,为每个类别生成一个示例问题及两种回答。
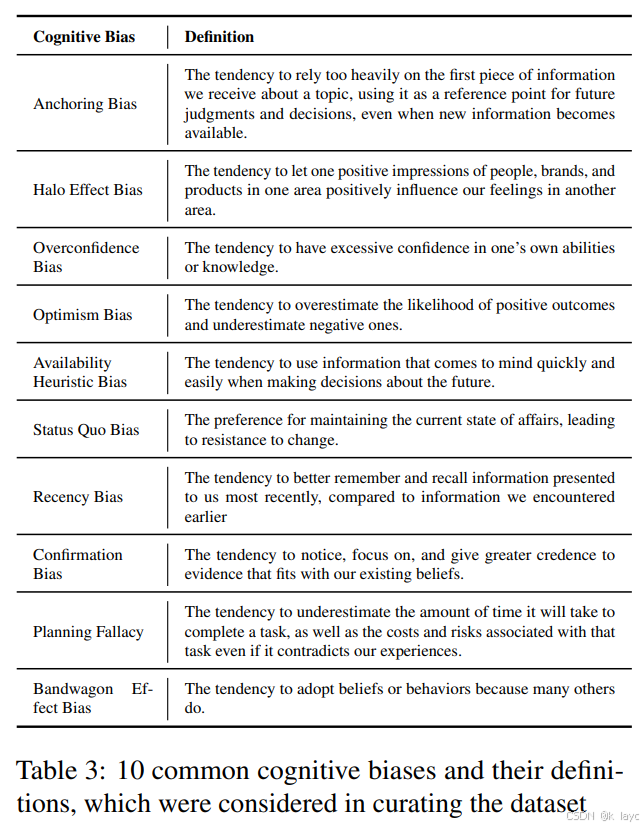
- 专家先选定10个认知偏见类别,为每个类别生成一个示例问题及两种回答。
-
利用 LLM 数据扩充:
- 使用 GPT-4o 进行一拍扩充,输入包括偏见定义、System 1 与 System 2 的不同应对策略等信息

- 使用 GPT-4o 进行一拍扩充,输入包括偏见定义、System 1 与 System 2 的不同应对策略等信息
-
人工校正:
- 专家对大约20%的回答进行人工审核和修改,确保符合设计要求。
-
长度调整:
- 由于 System 2 回答通常更长,使用 GPT-4o 的零样本提示将两种答案调整到相近的 token 数(调整后 System 1 平均 82.19 82.19 82.19 token,System 2 平均 83.93 83.93 83.93 token,统计检验: t ( 2090.1 ) = − 184.74 , p < . 001 , d = − 5.84 t(2090.1) = -184.74,\; p < .001,\; d = -5.84 t(2090.1)=−184.74,p<.001,d=−5.84)。
-
4.3 对齐算法
- 直接偏好优化(DPO):
- 利用参考模型比较“优胜”与“劣势”答案进行离线微调,不需要单独训练奖励模型。
- 简单偏好优化(SimPO):
- 基于 DPO 思路,但采用参考模型自由的方式,在模型内部直接优化偏好信号,计算上更高效。
4.4 实验设置
- 模型选择:
- 采用 Llama-3-8B-Instruct 和 Mistral-7B-Instruct-v0.1 作为基础模型进行微调。
- 比较方案:
- 对比基础模型、零样本 CoT 模型以及对齐后的 System 1 与 System 2 模型。
- 混合比例实验:
- 训练过程中设定多个中间模型,混合不同比例的 System 1 和 System 2 优胜答案(例如 87.5%-12.5%、75%-25%、50%-50% 等),以研究从直觉到分析推理的平滑过渡。
5. 实验结果与分析
5.1 推理基准测试
-
测试任务类别:
-
算术推理任务:
- 包括 MultiArith、GSM8K、AddSub、AQuA、SingleEq 和 SVAMP。
- 结果显示,System 2 模型在这些任务上表现优于基础模型和 System 1 模型,尤其在 AddSub 和 SingleEq 上提升显著。
-
常识推理任务:
- 使用 CSQA 和 StrategyQA 数据集。
- System 1 模型由于依赖启发式判断,在此类任务中更具优势,准确率高于 System 2 以及基础模型。
-
符号推理任务:
- 包括 Last Letter Concatenation 和 Coin Flip。
- 同样,System 2 模型在模式识别和逻辑结构化推理上占优。
-
-
表格展示(表 2):
- 表中详细列出了不同模型在各任务上的准确率以及与基线模型相比的提升或下降值。例如,在某些算术任务中,System 2 模型的提升高达 + 7.4 % +7.4\% +7.4%;而在常识任务中,System 1 模型则展现了更高的准确率citeturn0file0。
5.2 模型响应的深入分析
-
回答长度差异:
- 实验采用两阶段提示(初始回答和后续优化)生成最终答案。
- 分析显示,在第二阶段中,System 2 模型会生成更多 token(例如,DPO 对齐下 t ( 8836 ) = 57.14 , p < . 001 t(8836)=57.14,\; p<.001 t(8836)=57.14,p<.001;SimPO 下 t ( 8586 ) = 9.833 , p < . 001 t(8586)=9.833,\; p<.001 t(8586)=9.833,p<.001),表明其在必要时会展开更详细的推理。
-
不确定性与模糊性:
- Token-level 不确定性:
- 通过比较生成 token 的 logits,发现 System 2 模型的 token 平均对数概率更低,意味着其在输出时表现出更高的不确定性。
- 词汇层面的模糊词使用:
- System 2 模型倾向于使用“可能”、“也许”等模糊性词汇,而 System 1 模型则更倾向于给出确定性的回答。
- 定性评估:
- 在常识推理任务中,使用 LLM-as-Judge 评估发现 System 1 模型更早、更果断地产生明确答案(例如 McNemar 检验结果 χ 2 ( 1 , 400 ) = 20.0 , p < . 001 χ^2(1,400)=20.0,\; p<.001 χ2(1,400)=20.0,p<.001)。
- Token-level 不确定性:
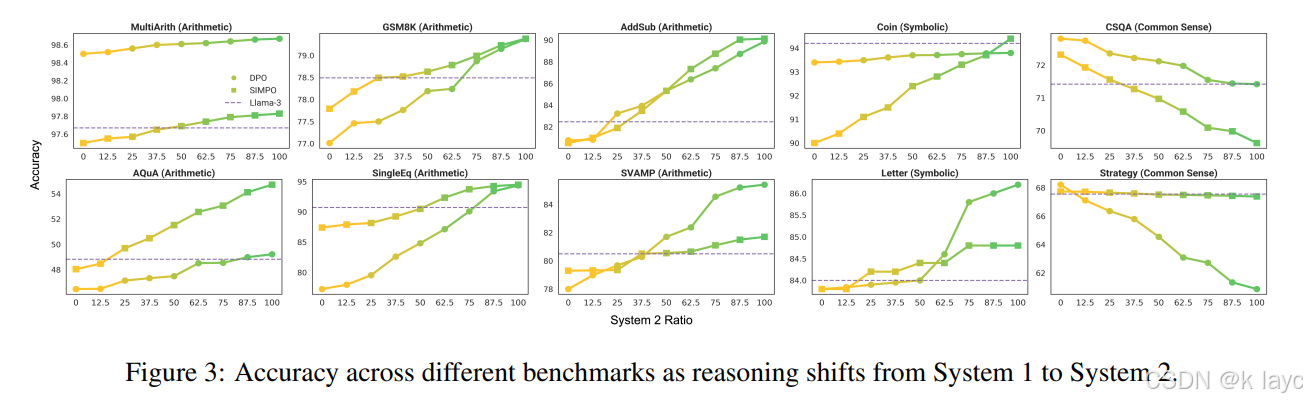
5.3 从快思到慢思的平滑过渡
- 插值实验:
- 通过设定不同 System 1 与 System 2 答案的混合比例,观察到在所有任务中准确率均呈现出单调变化。
- 图 3 显示:
- 在算术和符号任务中,随着 System 2 成分增加,准确率呈现逐步上升的趋势;
- 而在常识任务中,则随着 System 1 成分增加,准确率提升更明显。
- 这种单调变化说明两种推理风格之间转换平滑、可控,无突变现象。
6. 结论与讨论
-
主要结论:
- 通过显式对齐 LLMs 至 System 1(直觉、启发式)与 System 2(分析、逐步推理)两种思维模式,能够根据任务需求优化模型表现。
- System 2 模型在需要多步逻辑推理和符号计算的任务中更为优越,而 System 1 模型在常识性、快速决策场景下更具优势。
- 模型在两种思维模式下的响应不仅在准确率上表现不同,在回答长度、不确定性指标以及词汇使用上也存在明显差异。
-
理论与实践意义:
- 该研究为理解和改进大模型推理提供了新的视角,证明了将模型推理能力与人类双过程理论相结合的有效性。
- 在实际应用中,能够根据任务需求动态选择或混合两种推理风格,有望提升对话系统、决策支持系统等场景下的表现。
7. 限制与未来展望
- 数据集规模与覆盖面:
- 2000个问题虽涵盖多种认知偏见,但可能仍不足以代表现实中所有复杂推理场景。
- 依赖提示工程与对齐算法:
- 本方法依赖于特定的提示工程(prompt engineering)和对齐策略(DPO、SimPO),不同模型架构或训练流程可能导致不同效果。
- 不确定性测量局限性:
- 虽然通过 token logits 和模糊词分析能反映出一定的不确定性,但仍难以完全捕捉人类推理中的复杂主观感受。
- 未来工作方向:
- 可尝试扩展数据集、探索更多对齐策略以及在更复杂、动态的决策场景中检验该方法的泛化能力。
8. 道德声明与影响
- 伦理考量:
- 论文在数据收集、模型对齐和实验设计中均考虑了伦理问题。
- 同时指出,System 1 模型可能因过于自信而给出错误答案,而 System 2 模型则可能因推理过于冗长而影响响应速度。因此,在实际部署中需要权衡这两种模式的利弊,防止输出偏差或误导信息。
总结
本文通过将大语言模型对齐到两种典型的认知思维模式——直觉型的 System 1 与分析型的 System 2,展示了在不同任务中如何通过选择适当的推理策略来优化模型性能。实验结果不仅验证了两种模式各自的优势,还揭示了从直觉到分析之间的平滑过渡,为未来开发更加灵活高效的推理系统提供了重要参考。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









