






论文链接
1. 总览
论文背景与动机:
- RAG 的兴起与挑战: 随着大型语言模型(LLMs)在知识密集型任务中的表现不断提升,传统的“检索-生成”(retrieve-then-generate)范式(Naive RAG)逐渐暴露出诸多问题,如查询理解不足、冗余噪声干扰、以及面对复杂任务时检索准确性降低。
- Advanced RAG 的局限性: 尽管引入了预检索和后检索等策略,传统方法在面对真实场景时依然难以满足对系统透明度、控制性和可维护性的需求。
论文核心思想:
- 提出了一种**模块化 RAG(Modular RAG)**范式,将传统 RAG 系统拆分为多个独立但协调的模块和操作单元,就像 LEGO 积木一样,用户可以灵活重组系统结构,以适应不同数据源和任务场景。
2. 框架与符号定义
论文从数学符号和流程图的角度,给出了 RAG 系统的基本构成:
-
输入输出符号:
- q: 用户查询
- D: 文档集合(分为多个片段)
- Dq: 针对查询 q 检索到的相关文档片段集合
- y: 最终生成的答案
-
三大核心步骤:
- 索引(Indexing): 将文档切分为若干片段,并使用嵌入模型转换成向量。
- 检索(Retrieval): 基于查询 q,将其转换为向量并从向量数据库中选出与之最相似的文档片段。
- 生成(Generation): 将原始查询和检索到的文档片段拼接后输入到 LLM,生成最终答案。
-
模块化设计:
- L1 模块(Module): 表示系统的核心流程,每个模块负责一个关键任务。
- L2 子模块(Sub-module): 模块内部进一步拆分,形成更精细的功能单元。
- L3 操作符(Operator): 每个子模块内部的具体功能实现,例如查询扩展、重写、筛选等操作。
3. 各模块详细解读
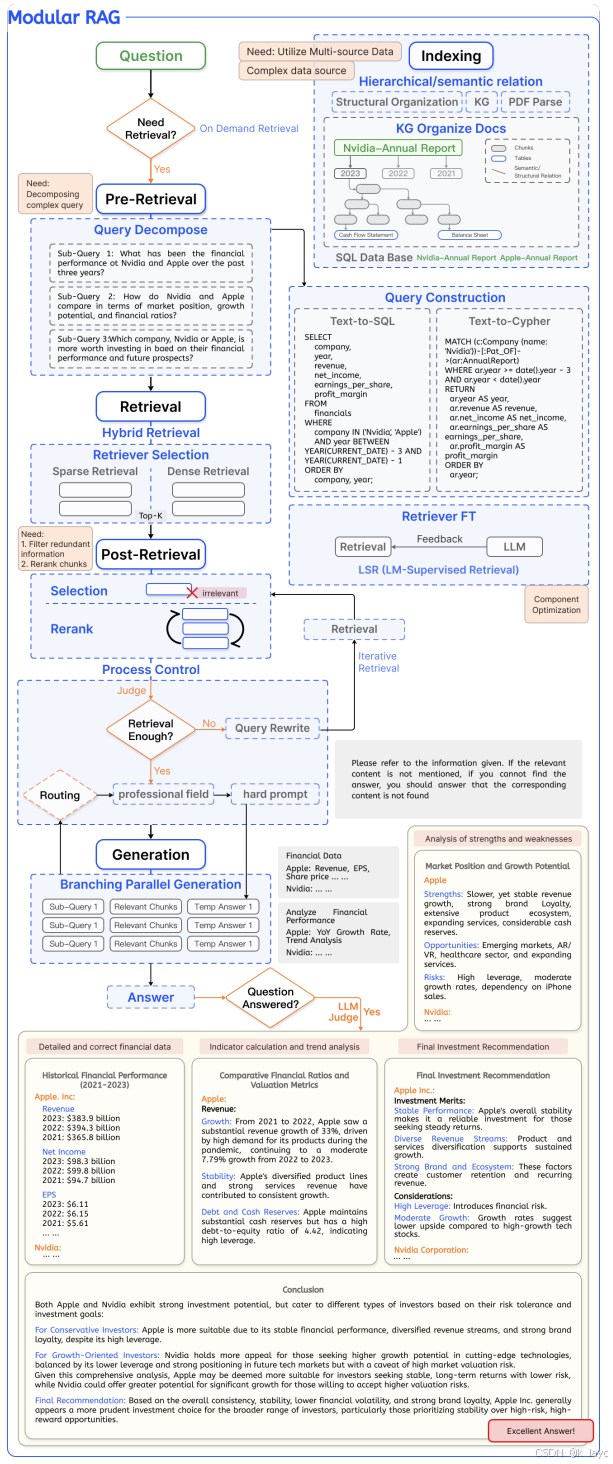
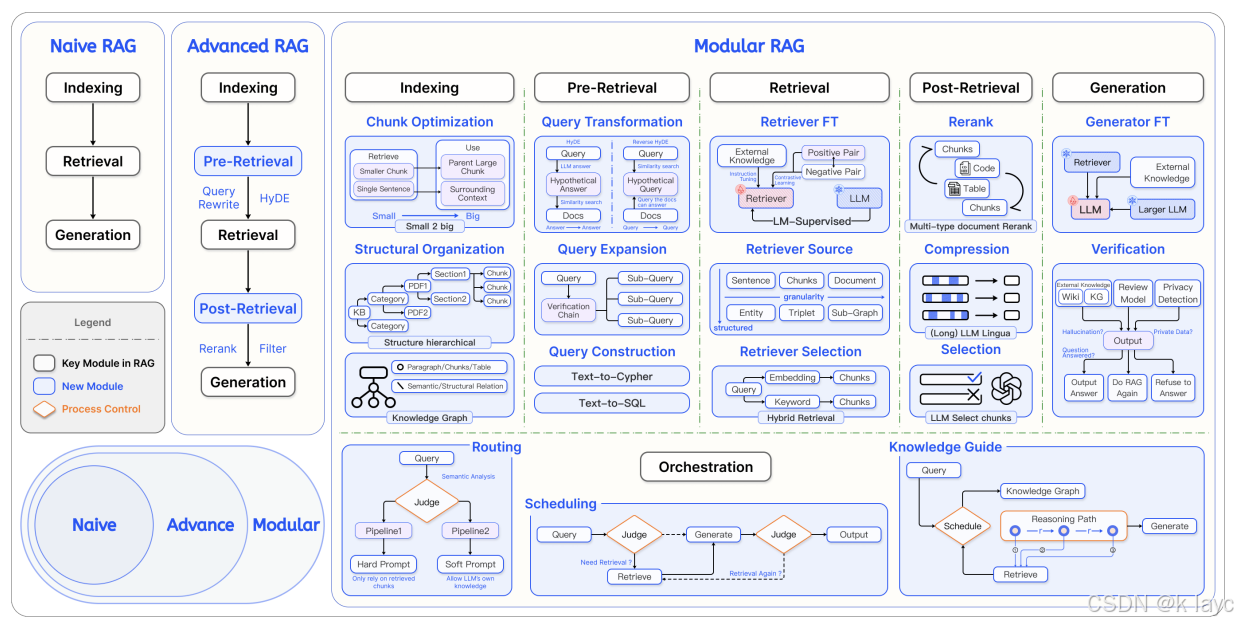
论文将传统 RAG 流程进一步细化为六大模块,每个模块内部又定义了多种操作符:
3.1 索引模块(Indexing)
主要挑战:
- 内容表示不全: 由于文档切分方式的限制,可能导致关键信息丢失或被稀释。
- 相似度搜索不准确: 数据量增加时,噪声信息增多,容易引入误匹配。
- 引用路径不清晰: 检索到的片段可能来自不同文档,缺乏有效引用跟踪。
解决方案与策略:
- 分块优化:
- 调整块的大小与重叠率,以兼顾上下文完整性和噪声控制。
- 引入“Small-to-Big”策略,即检索时用小块、生成时结合大块上下文。
- 结构化组织:
- 利用层次结构、段落与句子级别的切分来构造索引。
- 引入知识图谱(KG Index)来增强文档结构化表示,确保语义一致性。
3.2 预检索模块(Pre-retrieval)
核心问题:
- 直接使用用户原始查询进行检索可能导致不准确或遗漏信息。
关键操作:
- 查询扩展(Query Expansion):
- 利用多查询策略(Multi-Query)扩展原始查询,覆盖更多细节。
- 采用链式提示(Least-to-Most Prompting)和验证机制(Chain-of-Verification)降低生成失真。
- 查询转换(Query Transformation):
- 对原始查询进行重写(Rewrite)或利用 HyDE 构造假设答案,再基于假设答案进行检索。
- 查询构造(Query Construction):
- 将自然语言查询转换为结构化查询语言(如 SQL、Cypher),以适应异构数据源。
3.3 检索模块(Retrieval)
主要任务:
- 基于嵌入向量和相似度计算,从文档库中找出与查询最匹配的文档片段。
关键策略:
- 检索器选择:
- 稀疏检索器(Sparse Retriever): 如 TF-IDF、BM25,效率高但语义捕捉能力有限。
- 密集检索器(Dense Retriever): 基于 BERT 等预训练模型,捕捉复杂语义但计算成本较高。
- 混合检索器(Hybrid Retriever): 结合两者优点,提高检索鲁棒性。
- 检索器微调:
- 利用监督微调(SFT)和 LM-supervised 检索(LSR)优化检索器在特定领域的表现。
- 采用 Adapter 模块在无法直接微调大模型时进行灵活调整。
3.4 后检索模块(Post-retrieval)
目标:
- 对检索到的大量片段进行进一步处理,过滤噪音、提升关键信息的权重,从而为生成模块提供更优质的上下文。
核心操作:
- 重排(Rerank):
- 利用规则或模型对检索结果进行排序,以提升高相关性内容的显著性。
- 压缩(Compression):
- 对文档片段进行压缩,删除冗余或无关信息,确保 LLM 输入不超长且高效。
- 选择(Selection):
- 根据预设条件直接剔除不相关的文档片段(Selective Context、LLM-Critique)。
3.5 生成模块(Generation)
任务:
- 基于处理后的查询和上下文信息,通过 LLM 生成最终回答。
细节:
- 生成器微调(Generator Fine-tuning):
- 利用指令微调(Instruct-Tuning)、知识蒸馏和强化学习方法(RL from LLM/human feedback)提升生成质量。
- 验证机制(Verification):
- 通过知识库检验或小型模型的验证,降低 LLM 生成幻觉(hallucination)的风险。
- 双重微调(Dual Fine-tuning):
- 同时调整检索器和生成器,以实现两者间更紧密的协同。
3.6 调度与编排模块(Orchestration)
核心思想:
- 通过路由、调度和融合机制动态控制 RAG 流程,而不是采用固定的线性流水线。
关键策略:
- 路由(Routing):
- 根据查询内容及元数据动态选择合适的处理分支(利用关键字匹配和语义分析)。
- 调度(Scheduling):
- 决定何时进行新一轮检索或停止生成,常见方法包括基于规则、LLM 判断以及知识引导的调度。
- 融合(Fusion):
- 对多条生成分支的结果进行整合,如采用加权融合或 RRF(Reciprocal Rank Fusion)技术,确保最终输出内容的全面性和一致性。
4. RAG 流程与流模式
论文进一步总结了当前 RAG 系统中常见的几种流程模式,说明 Modular RAG 的灵活性和普适性。
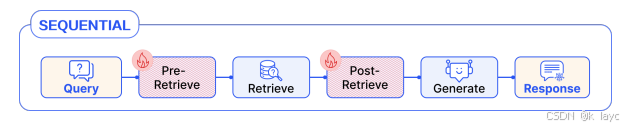
4.1 线性模式(Linear Pattern)
- 基本结构: 按照预检索 → 检索 → 后检索 → 生成的固定顺序进行处理。
- 实例: Naive RAG 就是线性模式的一个特例,而 RRR(Rewrite-Retrieve-Read)则在预检索阶段加入了查询重写模块。
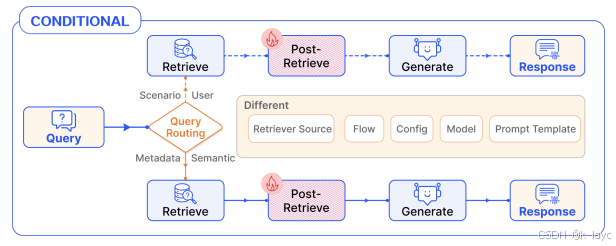
4.2 条件模式(Conditional Pattern)
- 特点: 系统在某个节点会根据当前输出或查询内容通过路由模块选择不同的后续处理分支。
- 应用场景: 针对不同类型的问题(如政治、法律、娱乐)动态选择不同的检索和生成策略。
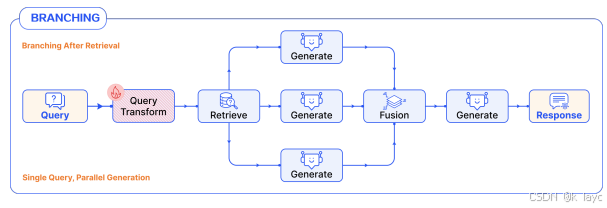
4.3 分支模式(Branching Pattern)
- 两种类型:
- 预检索分支: 对查询进行扩展生成多个子查询,各自并行进行检索和生成,最后聚合结果。
- 后检索分支: 单一查询检索到多个文档片段后,针对每个片段分别生成答案,再进行结果融合。
- 优势: 增加结果多样性,适用于复杂、多方面信息融合的任务。
4.4 循环模式(Loop Pattern)
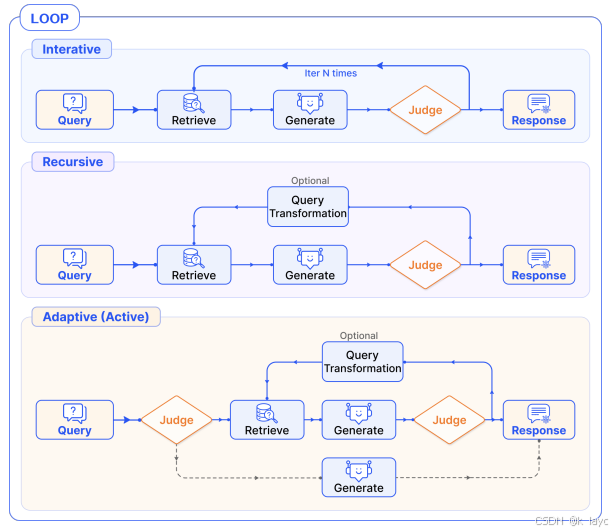
- 形式: 包括迭代、递归以及自适应(主动)检索。
- 迭代检索: 利用前一轮生成结果作为上下文,进行多轮检索与生成,直至满足终止条件。
- 递归检索: 通过树形结构不断细化查询,逐层深入处理复杂问题。
- 自适应检索: LLM 根据当前上下文主动判断是否需要再次检索,类似于 LLM Agent 的机制。
4.5 调优模式(Tuning Pattern)
- 内容: 包括针对检索器、生成器以及两者协同的微调策略。
- 意义: 通过微调,使得各个组件更好地适应特定领域任务,并提升整体系统的协同性。
5. 讨论与未来展望
论文在讨论部分指出:
-
模块化的优势:
- 灵活性与可扩展性: 用户可以根据具体需求自由组合现有模块,也可以插入新的操作符,实现定制化应用。
- 系统可维护性: 模块化设计使得问题定位和优化更加高效。
-
兼容性与创新机会:
- 重组现有模块: 例如 DR-RAG 通过二阶段检索和分类器选择机制解决多跳问答问题。
- 新流程设计: 如 PlanRAG 通过前置规划模块实现复杂问题的多步决策。
- 新型操作符的引入: 例如 Multi-Head RAG 利用 Transformer 的多头注意力来捕捉数据多样性,提升复杂查询的检索效果。
6. 结论
论文总结了以下几点主要贡献:
- 提出模块化 RAG 范式: 通过模块、子模块和操作符三层架构,统一、系统地定义和构造 RAG 系统,为后续研究和实际部署提供了坚实的理论基础与实践路线。
- 丰富的流程模式: 系统总结了线性、条件、分支、循环和调优等典型流模式,展示了 RAG 流程设计的多样性和适应性。
- 开放未来发展方向: 指出随着 LLM 技术和实际应用需求的发展,未来可能涌现出更多创新的操作符和流程模式,推动 RAG 技术的不断演进。
7. 总结
本文通过将 RAG 系统模块化,打破了传统“检索-生成”线性架构的局限,构建了一个类似 LEGO 积木式可重构的系统框架。该框架不仅能够有效应对复杂查询和多模态数据,还能通过灵活调度和动态路由机制,实现高效、透明、可控的知识增强生成过程。论文为研究人员和工程师提供了一份详细的设计蓝图,同时也为未来 RAG 技术的发展指明了方向。

















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









