




 本文探讨了Flink中的状态管理,包括状态的概念、作用、Storm与Flink的区别,重点讲解了Flink状态分类(OperatorState、KeyedState)、实战案例以及检查点与一致性保障,涉及无状态和有状态计算、状态后端存储机制和状态重新分配。
本文探讨了Flink中的状态管理,包括状态的概念、作用、Storm与Flink的区别,重点讲解了Flink状态分类(OperatorState、KeyedState)、实战案例以及检查点与一致性保障,涉及无状态和有状态计算、状态后端存储机制和状态重新分配。
1、状态State
1.1、状态基本概念
(1)状态:是一个Operator的运行状态/历史值(比如某个属性的值);
(2)流程:一个算子的子任务接受输入流,获取对应状态,计算新的结果,然后把结果更新到状态中
(3)数据类型:private Valuestate
1.2、状态作用
(1)容错:Job故障重启,程序升级
(2)增量计算:聚合操作,机器学习训练模式
全量计算模式
1.3、storm&Flink区别
-
Storm+Hbase,把这状态数据存放在Hbase中,计算的时候再次从Hbase读取状态数据,做更新在写入进去。这样就会有如下几个问题:
-
- 流计算任务和Hbase的数据存储有可能不在同一台机器上,导致性能会很差。这样经常会做远端的访问,走网络和存储
- 备份和恢复是比较困难,因为Hbase是没有回滚的,要做到Exactly onces很困难。在分布式环境下,如果程序出现故障,只能重启Storm,那么Hbase的数据也就无法回滚到之前的状态。比如广告计费的这种场景,Storm+Hbase是行不通的,出现的问题是钱可能就会多算,解决以上的办法是Storm+mysql,通过mysql的回滚解决一致性的问题。但是架构会变得非常复杂。性能也会很差,要commit确保数据的一致
1.4、Flink状态计算
(1)无状态计算
同个数据进入算子多次,都是一样的输出,比如filter
- 无状态计算不会存储计算过程中产生的结果,也不会将结果用于下一步计算过程中,程序只会在当前的计算流程中实行计算,计算完成就输出结果,然后下一条数据接入,然后再处理
(2)有状态计算
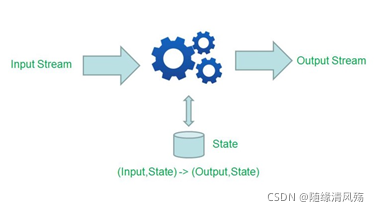
需要考虑历史状态,同个输入会有不同输出,比如sum,reduce聚合操作。
- 在程序计算过程中,在Flink程序内部存储计算产生的中间结果,并提供给后续Function或算子计算结果使用。
1.5、状态分类
1.5.1、Operator State(算子状态) - 用的少
- 原理:绑定到特定的Operator并行实例,每个operator的并行实例维护一个状态;
- 维护&访问:作用范围限定为算子任务,由同一并行任务处理的所有数据都可以访问到相同的状态,即对于同一子任务而言是共享的;
- 数据类型:ListState
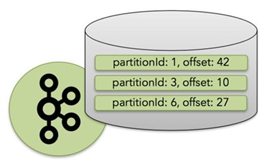
- 思考问题
问题:一个并行度为3的source有几个状态()
答案:有三个状态,分别保存相应状态
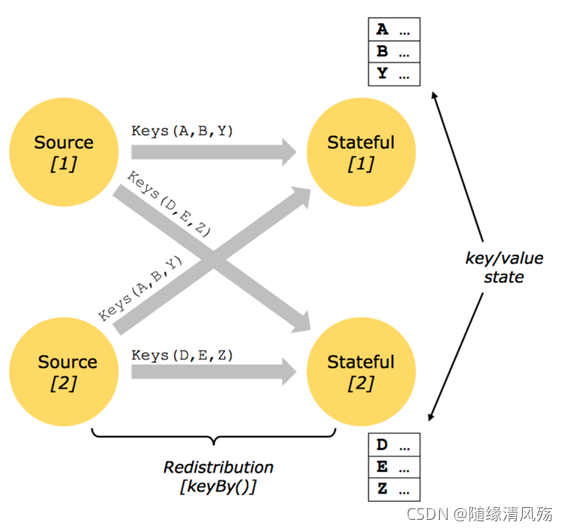
1.5.2、Keyed State(键控状态)- 用的多
-
原理:基于KeyedStream之上的状态,KeyBy之后的Oprator State(dataStream.keyby()),只能作用于KeyedStream上的function/Operator里使用
-
维护&访问:根据输入流中定义的键(key)来维护和访问
-
数据类型:
ValueState<T>:保留一个可以更新和检索的值
ListState<T>:保存一个元素列表
ReducingState<T>:保存一个值,该值表示添加到该状态所有值的聚合。
AggregatingState<IN,OUT>:保存一个值,该值表示添加到该状态的所有值的聚合。
- 思考题
问题:一个并性度为2的keyed Operator有多少个状态?(一个算子只有一个实例状态)
答案:有多少个key就有多少个状态
1.5.3、状态的表现形式
-
Keyed State和OperatorState,可以以两种形式存在:原始状态和托管状态
(1)managed(托管状态):指Flink框架管理的状态,通过框架提供的接口来更新和管理状态的值,用的较多
(2)raw(原始状态):由用户自行管理的具体的数据结构,自定义算子时才用。
•通常在DataStream上的状态推荐使用托管的状态,当用户自定义operator时,会使用到原始状态。
•大多数都是托管状态,除非自定义实现。
1.6、状态后端存储机制
- 状态后端:本地的状态管理&检查点状态写入远程存储,可存储到内存、磁盘、DB或其他分布式存储中。
1.6.1、HashMapStateBackend
- 作用:保存数据在内部作为JAVA堆的对象
存储:哈希表,用于存储值、触发器等
读取:读取非常快,每个状态的访问/更新都在java堆上的对象进行行操作
缺点:状态大小受集群内可用内存限制
- 应用场景
1、具有大状态、长窗口、大键/值状态的作业
2、所有高可用性设置
1.6.2、EmbeddedRocksDBStateBackend
- 作用:在RocksDB数据库中保存状态数据
存储:在RocksDB存储为序列化的字节数组,默认存储在TaskManager本地数据目录。
读取:读取相对慢,每个状态访问/更新都需要序列化&反序列化从磁盘读取/写入
- 应用场景
1、具有非常大状态、长窗口、大键值状态的作业
2、所有高可用设置
1.6.3、状态后端配置
- 后端文件配置:flink-conf.yaml中配置状态后端
(1)配置条目:hashmap(HashMapStateBackend)
state.backend:hashmap
(2)配置条目:rocksdb(EmbeddedRocksDBStateBackend)
state.backend:rocksd
2、状态实战
2.1、需求
- 根据需求进行分组,统计出每个商品最大的订单成交额
- 不用may实现,用Value实现
2.2、代码实战
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//java,2022-11-11 09-10-10,15
DataStream<String> ds = env.socketTextStream("127.0.0.1", 8888);
DataStream<Tuple3<String, String, Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, String, Integer>> out) throws Exception {
String[] arr = value.split(",");
out.collect(Tuple3.of(arr[0], arr[1], Integer.parseInt(arr[2])));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> maxVideoOrderDS = flatMapDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() {
@Override
public String getKey(Tuple3<String, String, Integer> value) throws Exception {
return value.f0;
}
}).map(new RichMapFunction<Tuple3<String, String, Integer>, Tuple2<String, Integer>>() {
// 1、声明局部变量
private ValueState<Integer> maxVideoOrderState = null;
// 2、拿到运行上下文,固定写法(背)
@Override
public void open(Configuration parameters) throws Exception {
maxVideoOrderState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("maxValue",Integer.class));
}
@Override
public Tuple2<String, Integer> map(Tuple3<String, String, Integer> value) throws Exception {
// 3、获取历史值
Integer maxValue = maxVideoOrderState.value();
Integer currentValue = value.f2;
// 4、判断
if(maxValue == null || currentValue>maxValue){
// 4.1、更新状态,当前最大的值存储到state
maxVideoOrderState.update(currentValue);
return Tuple2.of(value.f0,currentValue);
}else {
// 4.2保持原值
return Tuple2.of(value.f0,maxValue);
}
}
@Override
public void close() throws Exception {
super.close();
}
});
maxVideoOrderDS.print("最大订单:");
env.execute("watermark job");
}
}
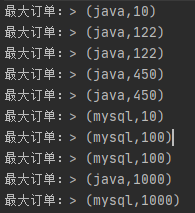
2.3、测试结果
(1)测试数据
java,2022-11-11 23:12:07,10
java,2022-11-11 23:12:11,122
java,2022-11-11 23:12:08,20
java,2022-11-11 23:12:13,450
java,2022-11-11 23:12:23,121
mysql,2022-11-11 23:12:09,10
mysql,2022-11-11 23:12:02,100
mysql,2022-11-11 23:14:30,50
java,2022-11-11 23:12:03,1000
mysql,2022-11-11 23:12:04,1000
(2)运行结果
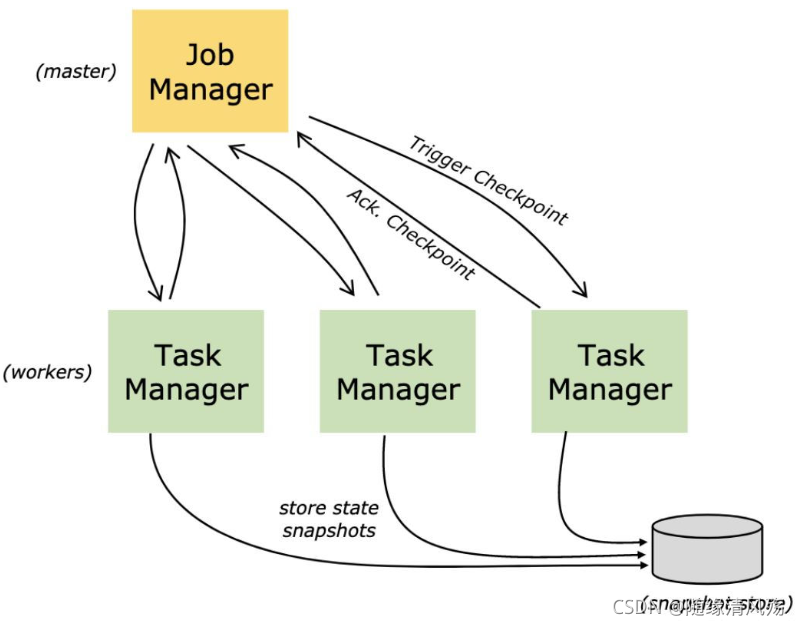
3、检查点
- 作用:把State数据定时持久化,防止丢失,从而为意外失败作业提供重启恢复机制
3.1、检查点概述
3.1.1、基本概念
- Checkpoint:在某一时刻,将所有task的状态做一个快照(snapshot),然后存储到State Backend。
全局快照:持久化保存所有的task / operator的State
- Savepoint:手工调用checkpoint,主要用于flink集群升级等。
3.1.2、恢复机制
①Source:需要外部数据源充值读取位置,当发生故障时候重置偏移量到故障之前的位置;
②内部:依赖Checkpoints机制,在发生故障的时候可以恢复各个环节的数据;
③Sink:当故障恢复时,数据不会重复写入外部系统,常见的就是幂等和事务写入(和checkpoint配合)。
3.2、检查点故障恢复
- 故障恢复:Flink将会使用最近的检查点来一直恢复应用程序的状态,并重新启动处理流程
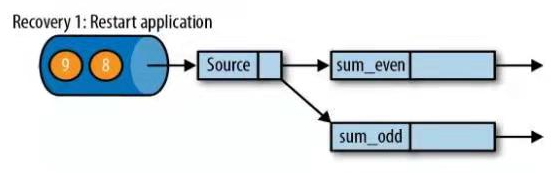
- 故障恢复流程如下
① 重启应用,当前状态都为null
②从checkpoint中读取状态,将状态重置,即先恢复状态
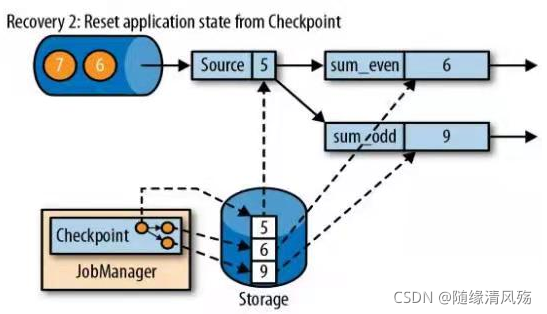
- 从检查点重新启动应用程序后,其内部状态与检查点完成时状态完全相同
③ 重置Source偏移量,开始消费并处理检查点到发生故障之间的所有数据
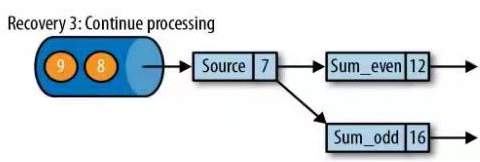
- 所有输入流就会被重置到检查点完成时的位置
3.3、检查点算法思路
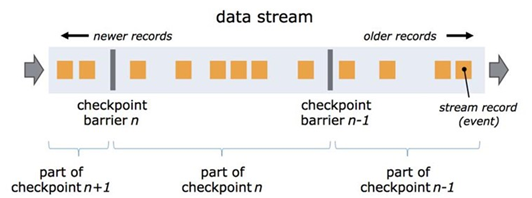
3.3.1、检查点分界线(Barrier)
- 分界线:用来把一条流上数据按照不同的检查点分开,barrier被插入到数据流中,作为数据流的一部分和数据一起向下流动。
一个barrier把数据流分割成两部分:一部分进入到当前快照,另一部分进入下一个快照
(1)Barrier基础
① 每一个barrier都带有快照ID,并且barrier之前的数据都进入了此快照。
② Barrier不会干扰数据流处理,所以非常轻量。
③ 多个不同快照的多个barrier会在流中同时出现,即多个快照可能同时创建。
(2)Barrier多并行度(对齐),flink怎么保证Exactly Once
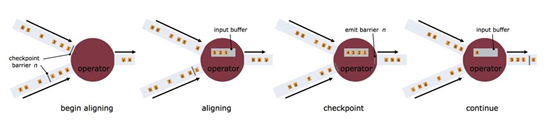
释疑:接收超过一个输入流的operator需要基于barrier对齐(align)输入
- operator 只要一接收到某个输入流的barrier n,它就不能继续处理此数据流后续的数据,直到operator接收到其余流的barrier n。否则会将属于snapshot n 的数据和snapshot n+1的搞混
- barrier n 所属的数据流先不处理,从这些数据流中接收到数据被放入接收缓存里(input buffer)
- 当从最后一个流中提取到barrier n 时,operator 会发射出所有等待向后发送的数据,然后发射snapshot n 所属的barrier
- 经过以上步骤,operator 恢复所有输入流数据的处理,优先处理输入缓存中的数据
(3)CheckPoint原理(MS)
通过往Source注入Barrier,Barrier作为checkpoint的标志
(4)分布式环境下的CK原理
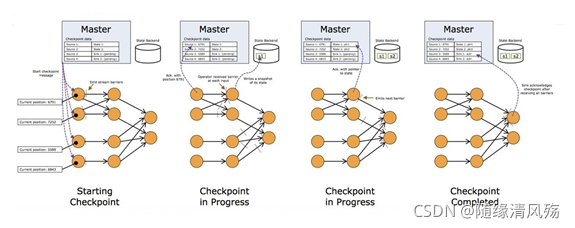
在分布式情况下:
- operator在收到所有输入数据流中的barrier之后,在发射barrier到其输出流之前对其状态进行快照。此时,在barrier之前的数据对状态的更新已经完成,不会再依赖barrier之前数据。
- 然后它会向其所有输出流插入一个标识 snapshot n 的barrier。当sink operator (DAG流的终点)从其输入流接收到所有barrier n时,它向checkpoint coordinator 确认 snapshot n 已完成当,所有sink 都确认了这个快照,代表快照在分布式的情况被标识为整体完成。
由于快照可能非常大,所以后端存储系统可配置。默认是存储到JobManager的内存中,但是对于生产系统,需要配置成一个可靠的分布式存储系统(例如HDFS)。状态存储完成后,operator会确认其checkpoint完成,发射出barrier到后续输出流。
快照现在包含了:
- 对于并行输入数据源:快照创建时数据流中的位置偏移
- 对于operator:存储在快照中的状态指针
3.3.2、检查点实现算法
-
核心机制:全局异步化
-
基本思想:基于Chandy-Lamport算法的分布式快照,即每个人单独保存快照,最后将单独的快照P成群像。
优点:将检查点的保存和数据处理分离开,不暂停整个应用。
3.4、保存点
3.4.1、Savepoint原理
savepoint可以理解为是一种特殊的checkpoint,savepoint就是指向checkpoint的一个指针,只是需要手动触发,而且不会过期,不会被覆盖,除非手动删除。
3.4.2、savepoint组成
(1) 数据目录:稳定存储上的目录,里面的二进制文件是streaming job状态的快照;
(2)元数据文件:指向数据目录中属于当前Savepoint的数据文件的指针(绝对路径)
3.4.3、Savepoint基本命令
(1)触发Savepoint
- 直接触发Savepoint(想象你要为数据库做个备份)
bin/flink savepoint :jobId [:targetDirectory]
- 直接触发Savepoint(Flink on yarn):
bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
(2)从Savepoint恢复job
$ bin/flink run -s :savepointPath [:runArgs]
(3)删除Savepoint
$ bin/flink savepoint -d :savepointPath
3.4.4、Checkpoint&Savepoint区别
(1)触发机制
- Checkpoint:Flink自动创建的"recovery log"用于故障自动恢复,由Flink创建,不需要用户交互;
- Savepoint:用户创建,拥有和删除。
(2)文件保存
- Checkpoint:用户cancel作业时就删除,除非启动了保留机制(External Checkpoint);
- Savepoint:保存点在作业终止后仍然存在,除非用户自己删除。
(3)应用场景
- Checkpoint:应用内部restarting使用
- Savepoint:Flink版本更新,业务迁移,集群迁移
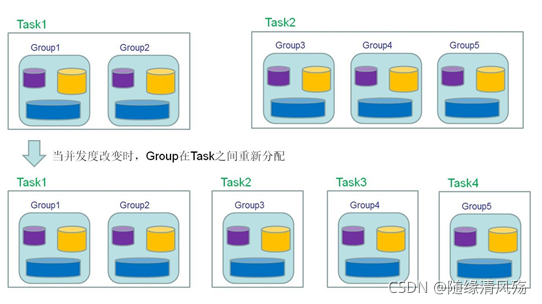
3.5、状态重新分配
2.5.1、Operator State Redistribute
-
场景:当Operator改变并发度的时候(Rescale),会触发状态的Redistribute。
-
实战案例:某Operator的并行度由3改为2
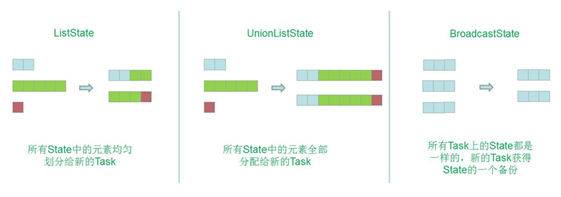
- 不同数据结构的动态扩展方式不一样:
(1)ListState:当并发改变,会将并发上的List取出合成为一个新的List,然后根据元素的个数通过轮询方式均匀分配到新的task;
(2)UnionListState:当改变并发的时候,会将原来的List拼接起来,每个Task给全量的状态,用户自己划分;
(3)BroadcastState:大表和小表做Join时,小表可以直接广播给大表的分区,在每个并发上的数据都是完全一致的。做的更新也相同,当改变并发的时候,把这些数据COPY到新的Task即可。
2.5.2、Keyed State Redistribute
- Keyed State Redistribute是基于Key Group来做分配的:
1、将key分为group
2、每个key分配到唯一的group
3、将group分配给task实例
4、Keyed State最终分配到哪个Task:group ID和taskID是从0开始算的
3.6、状态一致性
3.6.1、状态一致性的概念&分类
(1)状态一致性概念
状态一致性:就是计算结果要保证准确,一条数据不应该丢失,也不应该重算
本质要求:在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该是正确的
(2)状态一致性分类
①AT-MOST-ONCE(最多一次)
- 任务故障处理方式:什么都不干,即不恢复丢失的状态,也不重播丢失的数据。
②AT-LEAST-ONCE(至少一次)
- 大多数真实场景:所有事件都得到了处理,一些时间还可能被处理多次。
③EXACTLY-ONCE(准确一次)
- 处理机制:没有事件丢失,即针对每一个数据,内部状态仅仅更新一次
3.6.2、端到端的状态一致性
(1)一致性检查点
- 原理:所有任务的状态,在某个时间点的一份拷贝。这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
(2)保证机制
①内部保证:checkpoint
②Source端:可重设数据的读取位置
③Sink端:从故障恢复时,数据不会重复写入外部系统,即幂等/事务写入
3.6.3、幂等写入&事务写入
(1) 幂等操作
一个操作,可以重复执行很多次,但只导致一次结果更改,即后面再重复执行就不起作用了。
(2)事务写入
-
事务:应用程序中一系列严密的操作,所有操作必须要成功完成,否则在每个操作中所做的所有更改都会被撤销。
-
实现思想:构建的事务对应着checkpoint,等checkpoint真正完成时,才把所有对应的结果写入到Sink系统中。
-
实现方式:预写日志,两阶段提交
①预写日志
- 实现方式:DataStream API的模板类:GenericWriteAheadSink
- 原理:
- 第一步:把结果数据当成状态保存;
- 第二步:在收到checkpoint完成的通知事,一次性写入Sink系统
- 优点:数据提前在状态后端中做了缓存,无论什么sink系统,都用这种方式一批写入
批写入缺点
:1、写入一半,另外一半没写入,导致重复写入,没有严格实现精确一次语义
:2、前面全是流处理,写入Sink的时候变成批处理了
②两阶段提交
- 实现方式:TwoPhaseCommitSinkFunction接口
- 原理:
- 第一步:每个Checkponit,sink任务启动一个事务,并接下来所有接受的数据添加到事务里面
- 第二步:预提交,将这些数据写入外部系统,但不提交他们
- 第三步:当事务收到checkpoint完成的通知时,才正式提交事务,实现结果的真正写入
3.6.3、Flink+Kafka状态一致性
①内部:利用checkpoint机制,把状态存盘,发生故障时可以恢复,保证内部状态一致性;
②Source:kafka consumer作为source,将偏移量保存下来,若后续任务出现故障,回复的时候可以由连接器重置偏移量,重新消费数据;
③Sink:kafka producer作为Sink,采用两阶段提交Sink,中间消息落地到日志中。
两阶段提交步骤:
1、预提交:第一条数据来了之后,开启一个kafka的事务,正常写入kafka分区日志但标记为未提交
2、触发检查点保存:jobmanager出发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态保存状态后段,并通知jobmanager
3、保存检查点:sink连接器收到barrier,保存当前状态,存入checkpoint,通知jobmanager,并开启下一阶段事务,用于提交下个检查点数据
4、job确认检查点保存完成
5、sink收到jobmanager信心,正式提交这段时间的数据
4、检查点实战
package com.lihaiwei.text1.app;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class flink10state {
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 设置检查点
//两个检查点之间间隔时间,默认是0,单位毫秒
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//Checkpoint过程中出现错误,是否让整体任务都失败,默认值为0,表示不容忍任何Checkpoint失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);
//Checkpoint是进行失败恢复,当一个 Flink 应用程序失败终止、人为取消等时,它的 Checkpoint 就会被清除
//可以配置不同策略进行操作
// DELETE_ON_CANCELLATION: 当作业取消时,Checkpoint 状态信息会被删除,因此取消任务后,不能从 Checkpoint 位置进行恢复任务
// RETAIN_ON_CANCELLATION(多): 当作业手动取消时,将会保留作业的 Checkpoint 状态信息,要手动清除该作业的 Checkpoint 状态信息
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//Flink 默认提供 Extractly-Once 保证 State 的一致性,还提供了 Extractly-Once,At-Least-Once 两种模式,
// 设置checkpoint的模式为EXACTLY_ONCE,也是默认的,
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint的超时时间, 如果规定时间没完成则放弃,默认是10分钟
env.getCheckpointConfig().setCheckpointTimeout(50000);
//设置同一时刻有多少个checkpoint可以同时执行,默认为1就行,以避免占用太多正常数据处理资源
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//设置了重启策略, 作业在失败后能自动恢复,失败后最多重启3次,每次重启间隔10s
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000));
//java,2022-11-11 09-10-10,15
DataStream<String> ds = env.socketTextStream("192.168.6.104", 8888);
DataStream<Tuple3<String, String, Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, String, Integer>> out) throws Exception {
String[] arr = value.split(",");
out.collect(Tuple3.of(arr[0], arr[1], Integer.parseInt(arr[2])));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> maxVideoOrderDS = flatMapDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() {
@Override
public String getKey(Tuple3<String, String, Integer> value) throws Exception {
return value.f0;
}
}).map(new RichMapFunction<Tuple3<String, String, Integer>, Tuple2<String, Integer>>() {
// 1、声明局部变量
private ValueState<Integer> maxVideoOrderState = null;
@Override
public void open(Configuration parameters) throws Exception {
maxVideoOrderState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("maxValue",Integer.class));
}
@Override
public Tuple2<String, Integer> map(Tuple3<String, String, Integer> value) throws Exception {
// 2、获取历史值
Integer maxValue = maxVideoOrderState.value();
Integer currentValue = value.f2;
// 3、判断
if(maxValue == null || currentValue>maxValue){
// 3.1、更新状态,当前最大的值存储到state
maxVideoOrderState.update(currentValue);
return Tuple2.of(value.f0,currentValue);
}else {
// 3.2保持原值
return Tuple2.of(value.f0,maxValue);
}
}
@Override
public void close() throws Exception {
super.close();
}
});
maxVideoOrderDS.print("最大订单:");
env.execute("watermark job");
}
}



















 3830
3830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











