




LeNet-5是一个典型的用于字符识别的CNN结构,出于好奇和对经典的敬畏,就去了解了一下LeNet-5
有兴趣可以看看这篇经典的论文:Gradient-Based Learning Applied to Document Recognition
我这里不是对LeNet5的严谨解析哈,只是我个人的学习笔记,有任何问题请多多指教~欢迎多些交流哈~。文中也用到了其他博客的图片,嫌麻烦没标注出处,如果有侵权请联系删除~
LeNet-5模型
参考:https://blog.youkuaiyun.com/strint/article/details/44163869
https://blog.youkuaiyun.com/zhangjunhit/article/details/53536915
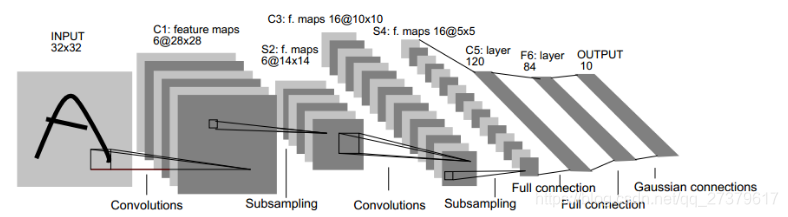
上图是一个完整的LeNet-5的模型,模型一共7层(不包括输入层),模型的Layer相对比较简单,包括2个卷积层、2 个下采样层、1个全连接层和1个输出层。其中,卷积层标记为Cx,下采样层标记为Sx,全连接层标记为Fx,x指的是所在的层的索引。
LeNet-5中所有的卷积核大小都为5*5,采样窗口大小为2*2,步长都为1。输入层的输入图像尺寸统一归一化为32*32.
1、Input → C1
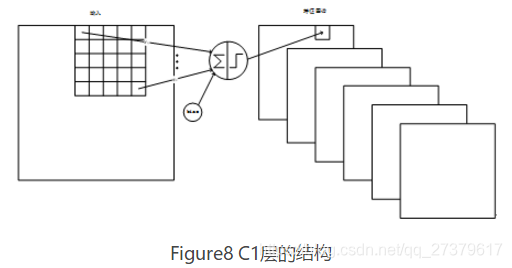
输入:32*32的图片
卷积核大小:5*5
卷积核个数:6
可训练参数个数:(5*5*+1)* 6 = 156
连接个数:(5 * 5 +1)* 28 * 28 * 6 = 122,304
输出:6个大小为28*28的feature map
补充说明:卷积层每个像素的输出 = Sigmoid( Sum(卷积) + 偏移量),其中卷积核和偏移量都是可训练的。
2、C1→ S2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









