







学习目标:
1、梯度下降:实现梯度下降
2、线性回归中的梯度下降
知识整理:
【1】
梯度下降(Gradient Descent, GD):不是一个机器学习算法,而是一种基于搜索的最优化方法。梯度下降(Gradient Descent, GD)优化算法,其作用是用来对原始模型的损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。
从损失值出发,去更新参数,且要大幅降低计算次数
梯度下降通过导数告诉我们此时此刻某参数应该朝什么方向,以怎样的速度运动,能安全高效降低损失值,朝最小损失值靠拢
梯度:多元函数的导数(derivative)就是梯度(gradient),分别对每个变量进行微分,然后用逗号分割开,梯度是用括号包括起来,说明梯度其实一个向量,我们说损失函数L的梯度为: ,导数为0(梯度为0向量)的点,就是优化问题的解
python中有两种常见求导的方法,一种是使用Scipy库中的derivative方法,另一种就Sympy库中的diff方法
# 使用Scipy库中的derivative方法
# 在一个点上找到函数的第n个导数
# 即给定一个函数,请使用间距为dx的中心差分公式来计算x0处的第n个导数
# import scipy
# scipy.misc.derivative(func, x0 ,dx=1.0, n=1, args(), order=3)[source]
# 参数:
# func:需要求导的函数,只写参数名即可,不要写括号,否则会报错
# x0:要求导的那个点,float类型
# dx(可选):间距,应该是一个很小的数,float类型
# n(可选):n阶导数。默认值为1,int类型
# args(可选):参数元组
# order(可选):使用的点数必须是奇数,int类型
from scipy.misc import derivative
def f(x):
return x**3 + x**2
print(derivative(f, 1.0, dx=1e-6)) # 4.99999999992
# 使用Sympy库中的diff方法
# sympy是符号化运算库,能够实现表达式的求导。所谓符号化,是将数学公式以直观符号的形式输出
from sympy import *
# 符号化变量
x = Symbol('x')
func = 1/(1+x**2)
print("x:", type(x))
print(func)
print(diff(func, x))
print(diff(func, x).subs(x, 3))
print(diff(func, x).subs(x, 3).evalf()) 实现:构造损失函数:![]() ,然后创建在-1到6的范围内构建140个点,并且求出对应的损失函数值,这样就可以画出损失函数的图形
,然后创建在-1到6的范围内构建140个点,并且求出对应的损失函数值,这样就可以画出损失函数的图形
import numpy as np
import matplotlib.pyplot as plt
from scipy.misc import derivative
def lossFunction(x):
return (x-2.5)**2-1
# 在-1到6的范围内构建140个点
plot_x = np.linspace(-1,6,141)
# plot_y 是对应的损失函数值
plot_y = lossFunction(plot_x)
plt.plot(plot_x,plot_y)
plt.show() 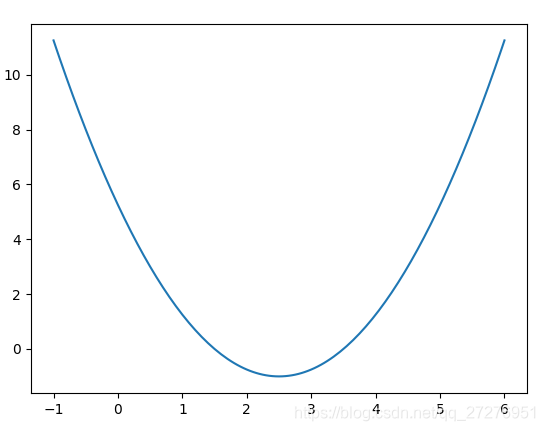
使用scipy库中的derivative方法定义求导方法
"""
算法:计算损失函数J在当前点的对应导数
输入:当前数据点theta
输出:点在损失函数上的导数
"""
def dLF(theta):
return derivative(lossFunction, theta, dx=1e-6) 梯度下降:作为初始值,
作为学习率(即每次下降的步长)
点沿着梯度的反方向移动
距离,即
,然后循环这一步骤
结束循环:设定一个非常小的数作为阈值,如果说损失函数的差值减小到比阈值还小,我们就可以结束循环了
theta = 0.0
theta_history=[theta]
eta = 0.1
epsilon = 1e-6
while True:
# 每一轮循环后,要求当前这个点的梯度是多少
gradient = dLF(theta)
last_theta = theta
# 移动点,沿梯度的反方向移动步长eta
theta = theta - eta * gradient
# 判断theta是否达到最小值
# 因为梯度在不断下降,因此新theta的损失函数在不断减小
# 看差值是否达到了要求
if(abs(lossFunction(theta) - lossFunction(last_theta)) < epsilon):
break
print(theta)
print(lossFunction(theta)) 创建一个用于存放所有点位置的列表,然后将其在图上绘制出来
def gradient_descent(initial_theta, eta, epsilon=1e-6):
theta = initial_theta
theta_history.append(theta)
while True:
# 每一轮循环后,要求当前这个点的梯度是多少
gradient = dLF(theta)
last_theta = theta
# 移动点,沿梯度的反方向移动步长eta
theta = theta - eta * gradient
theta_history.append(theta)
# 判断theta是否达到损失函数最小值的位置
if(abs(lossFunction(theta) - lossFunction(last_theta)) < epsilon):
break
def plot_theta_history():
plt.plot(plot_x,plot_y)
plt.plot(np.array(theta_history), lossFunction(np.array(theta_history)), color='red', marker='o')
plt.show()
theta = 0.0
theta_history=[theta]
eta = 0.1
gradient_descent(theta,eta)
plot_theta_history() 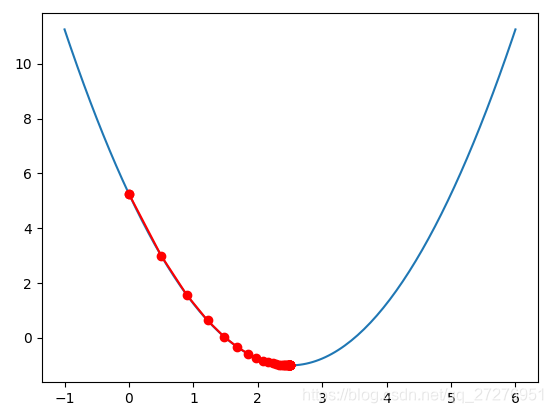
调整学习率:我们发现,在刚开始时移动比较大,这是因为学习率是一定的,再乘上梯度本身数值大(比较陡),后来梯度数值小(平缓)所以移动的比较小
上面的学习率为0.1,使用0.01进行观察:
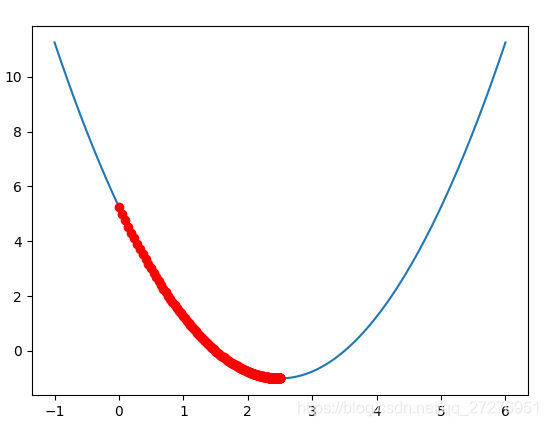
可见学习率变低了,每一步都很小,因此需要花费更多的步数。如果我们将学习率调大,会发生什么?
eta=0.9
theta_history = []
gradient_descent(0., eta)
plot_theta_history()
print("梯度下降查找次数:",len(theta_history))
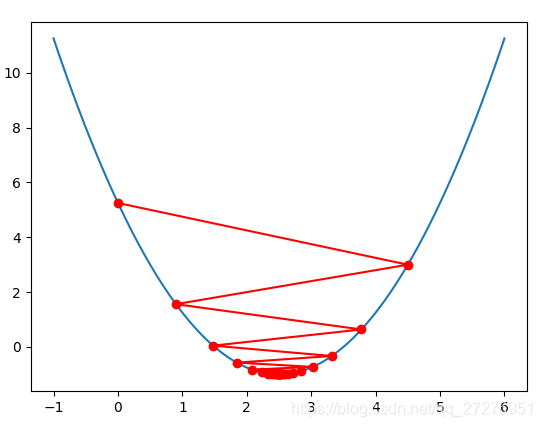
可见在一定范围内将学习率调大,还是会逐渐收敛的。但是我们要注意,如果学习率调的过大, 一步迈到“损失函数值增加”的点上去了,在错误的道路上越走越远(如下图所示),就会导致不收敛,会报OverflowError的异常
为了避免这种情况,加入限定条件改进代码:
# 在计算损失函数值时捕获一场
def lossFunction(x):
try:
return (x-2.5)**2-1
except:
return float('inf')
# 设定条件,结束死循环
def gradient_descent(initial_theta, eta, n_iters, epsilon=1e-6):
theta = initial_theta
theta_history.append(theta)
i_iters = 0
while i_iters < n_iters:
gradient = dLF(theta)
last_theta = theta
theta = theta - eta * gradient
theta_history.append(theta)
if(abs(lossFunction(theta) - lossFunction(last_theta)) < epsilon):
break
i_iters += 1【2】
真实的数据集往往有多个特征,涉及到多元线性回归。多元回归中,▽J是代价函数对每一个的导数组成的向量
多元回归中的▽J
代价函数图像也可能不再是一元回归中的抛物线,以二元回归为例,假设代价函数z = x^2 + 2 * y^2,则其代价函数和梯度下降如图所示。
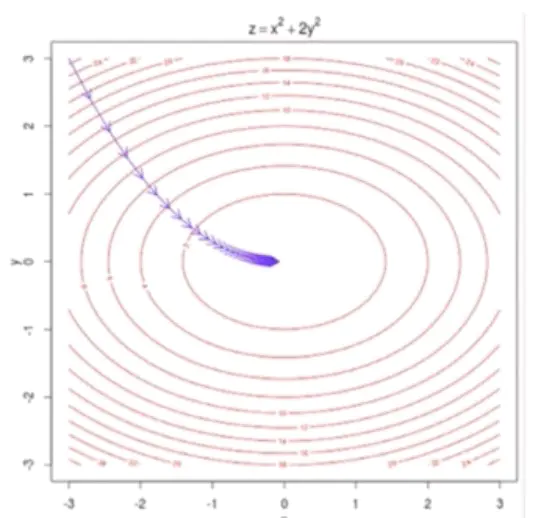
多元回归的目标还是使得代价函数最小,每个预测值都是由
相乘得到的
可以理解为回归方程的常数项,X是特征,下标从1开始,但为了方便,通常都会在特征中加一个值为1的
项,
=
,值不变的情况下方便矩阵相乘
推出相应的代价函数
相应的,可以得到代价函数对每个θ值的导数▽J。
当没有1/m时的推导过程。

加上1/m时的结果
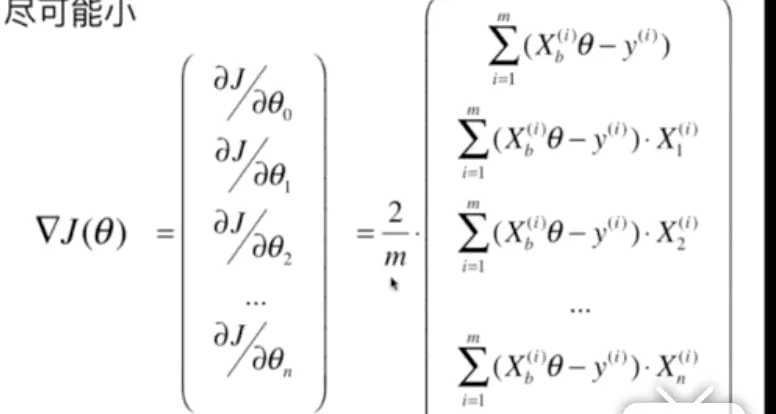
有时也会取1/2m,但和1/m差别不大
线性回归的向量化:
之前的代码通过for循环的方式,对各个属性求代价,线性回归可以将属性X和系数θ向量化,以矩阵乘法的方式进行求解。
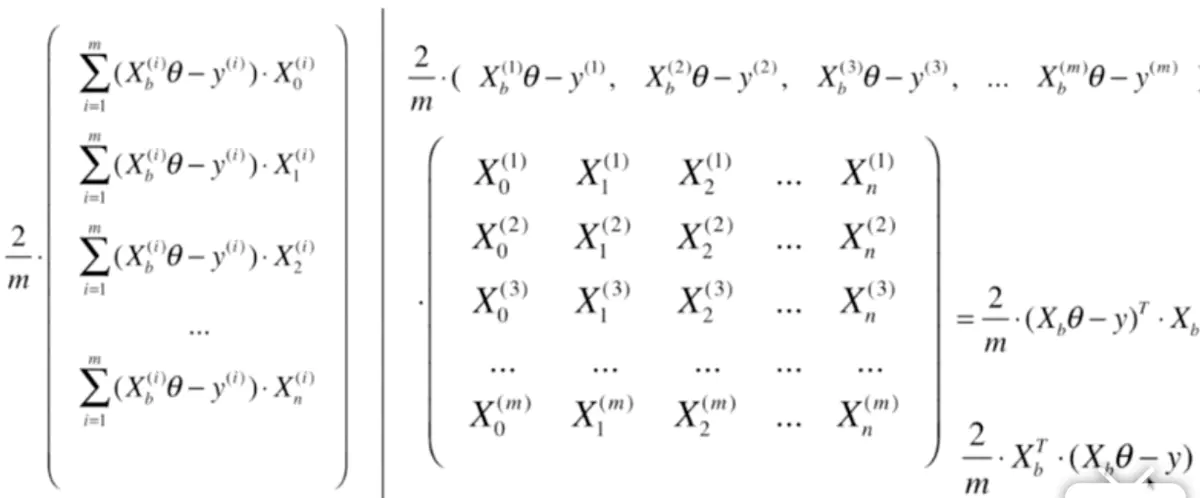
左侧给出代价函数的导数值,先不与每个样本对应的属性Xi,j做乘积将其转化为右侧顶部的向量
接下来分析X,对于每个样本,都含有n个特征,m个样本就可以组成m * n大小的矩阵X。对于系数θ可以是一个n * 1的矩阵,根据线性代数,m * n的矩阵和n * 1的矩阵相乘,会得到一个m * 1的矩阵,也就是回归方程得到的结果。
再和训练数据集的y做减法,两个m * 1的矩阵相减还是一个m*1的矩阵。
之后再完成与Xi,j做乘积的操作。这一步本质上还是与X矩阵相乘m * 1和m * n的矩阵没法直接相乘,但只需要转置一下,m * 1编程1 * m就可以了,当然这和图片当中把X转置变成n * m的矩阵再乘m * 1的矩阵是一个道理,都能得到n * 1的矩阵,再乘2/m,这个就是每个属性对应的▽J。代码实现:
def dJ(theta, X_b, y):
return X_b.T.dot(X_b.dot(theta) - y) * 2/ len(X_b)
这种方式也成为批量梯度下降
随机梯度下降:
批量梯度下降每次循环中对数据集的每个样本都进行计算得到最终的▽J,这样做很准确但时间消耗比较大。随机梯度下降采用每次对样本数据集中随机的一个样本进行计算的方式,这样做运算成本降低,但下降曲线不会像批量梯度下降一样是一条平滑的通向极小值点的曲线。可能会像下面这张图一样。
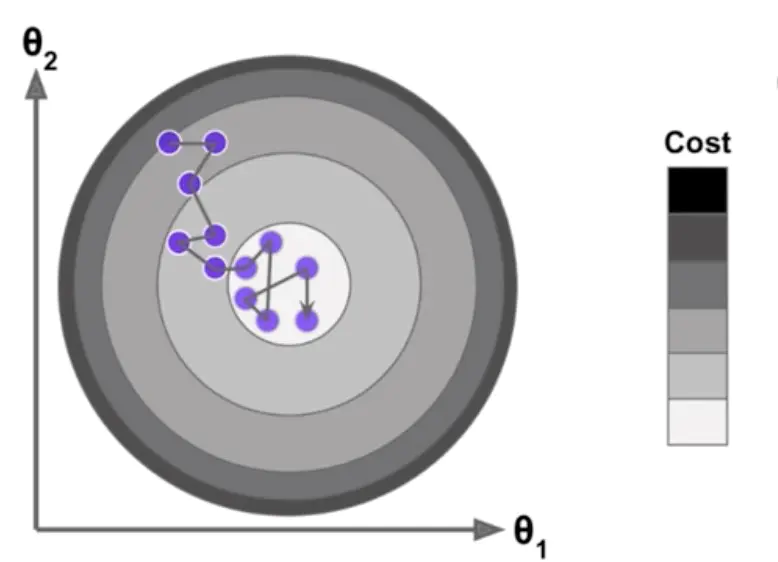
因为是随机选取数据集中的点,因此不能保证每次都会向代价函数减少最快的方向(放映到图上就是沿圆的半径),甚至有可能是向代价函数增大的方向,但一般情况下,这种方式也可以找到极小值点。
每次θ递减的幅度也是η * ▽J,但这里的η和批量梯度下降不太一样。η的常见的计算公式给出
学习率:
i_iters是当前的循环次数,b是一个因子,作用是缓冲最开始循环时η递减过快的情况。如没有b的话,第一次循环η=1/1=1,第二次循环η=1/2=0.5降幅50%,对于训练模型而言太快了,加上这么一个因子会减弱η的递减幅度。
模拟随机梯度下降:
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as dataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def fit_sgd(X_train, y_train, n_iter=5, t0=5, t1=50):
'''
随机梯度下降法
:param X_train:样本特征集
:param y_train:样本结果集
:param n_iter:这里的n_iter指的是遍历次数应该是整个样本个数n_iter倍
:param t0:学习率参数t0
:param t1:学习率参数t1
:return:
'''
'''代价函数的导数'''
def dJ_sgd(theta, X_i, y_i):
return X_i * (X_i.dot(theta) - y_i) * 2
'''代价函数(其实用不上)'''
def J(theta, X_i, y_i):
return (X_i.dot(theta) - y_i)**2
'''随机梯度下降'''
def sgd(theta_init, X_train, y_train, n_iter, t0, t1):
'''计算学习率'''
def learn_rate(cur_iter):
return t0 / (t1 + cur_iter)
theta = theta_init
m = len(X_train)
for i in range(n_iter):
'''打乱原本X_train、y_train的顺序'''
rand_index = np.random.permutation(m)
X_train_rand = X_train[rand_index]
y_train_rand = y_train[rand_index]
for j in range(m):
'''随机梯度下降'''
gradient = dJ_sgd(theta, X_train_rand[j], y_train_rand[j])
theta -= learn_rate(i * j) * gradient
return theta
X_train = np.hstack([np.ones((len(X_train), 1)), X_train])
theta_init = np.random.randn(X_train.shape[1])
theta = sgd(theta_init, X_train, y_train, n_iter, t0, t1)
return theta
X_train = np.hstack([np.ones((len(X_train), 1)), X_train])
theta_init = np.random.randn(X_train.shape[1])
theta = sgd(theta_init, X_train, y_train, n_iter, t0, t1)
return theta
随机梯度下降没有用到求代价函数值,达到循环次数后即完成下降。需要注意的是,批量梯度下降中,n_iters是循环的次数限制,而在随机梯度下降中,n_iters是样本集被循环的次数,这样做也是为了提升模型的准确度。如果有m大小的样本集,n_iters值为n,则一共需要循环m * n次,每次随机抽取一个样本进行梯度下降。
模拟一组数据
'''自建数据集'''
m = 100000
X_train = np.random.normal(size=m)
X_train = X_train.reshape(-1, 1)
y_train = 4.*X_train + 3. #+ np.random.normal(0, 3, size=m)
noise = np.random.normal(0, 3, size=m)
noise = noise.reshape(-1, 1)
y_train = y_train + noise
theta = fit_sgd(X_train, y_train, n_iter=2)
print(theta)
建一个100000个样本的数据集,曲线在y=4x + 3的基础上对每个元素增加一定的噪音干扰。通过之前定义的函数得到的θ输出
[3.01165213 4.03164546]
是常数项,基本上是3,
是x的系数近似4,因此,下降结果相对准确。
在sklearn中也封装了随机梯度下降的工具类,在linear_model包下的SGDRegressor中

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









