







学习目标:
1、简单线性回归:简单线性回归及最小二乘法的数据推导
2、实践:简单线性回归实现及向量化应用
3、多元线性回归:多元线性回归和正规方程解及实现
知识整理:
【1】
线性回归是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析,即简单线性回归。
简单线性回归:所谓简单,是指只有一个样本特征,即只有一个自变量;所谓线性,是指方程是线性的;所谓回归,是指用方程来模拟变量之间是如何关联的。也就是说,我们需要一条直线,最大程度的拟合样本特征和样本数据标记之间的关系
最小二乘法:最小二乘的思想就是要使得观测点和估计点的距离的平方和达到最小.这里的“二乘”指的是用平方来度量观测点与估计点的远近(在古汉语中“平方”称为“二乘”),“最小”指的是参数的估计值要保证各个观测点与估计点的距离的平方和达到最小。从这个上也可以看出,最小二乘也可用于拟合数据模型。对于测量值来说,让总的误差的平方最小的就是真实值。这是基于,如果误差是随机的,应该围绕真值上下波动。
即: (y为真值)
为了求出这个二次函数的最小值,对其进行求导,导数为0的时候取得最小值:
进而:
正好是算数平均数(算数平均数是最小二乘法的特例)。
这就是最小二乘法,所谓“二乘”就是平方的意思。
(高斯证明过:如果误差的分布是正态分布,那么最小二乘法得到的就是最有可能的值。)
【2】
简单线性回归实现:
# 首先构造一组数据,然后画图
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1.,2.,3.,4.,5.])
y = np.array([1.,3.,2.,3.,5,])
plt.scatter(x,y)
plt.axis([0,6,0,6])
plt.show()
# 实际上,同一组数据,选择不同的f(x),即模型
# 通过最小二乘法可以得到不一样的拟合曲线
# 不同的数据,更可以选择不同的函数
# 通过最小二乘法可以得到不一样的拟合曲线
# 用最小二乘法假设模型,再求出参数
# 首先要计算x和y的均值
x_mean = np.mean(x)
y_mean = np.mean(y)
# a的分子num、分母d
num = 0.0
d = 0.0
for x_i,y_i in zip(x,y): # zip函数打包成[(x_i,y_i)...]的形式
num = num + (x_i - x_mean) * (y_i - y_mean)
d = d + (x_i - x_mean) ** 2
a = num / d
b = y_mean - a * x_mean
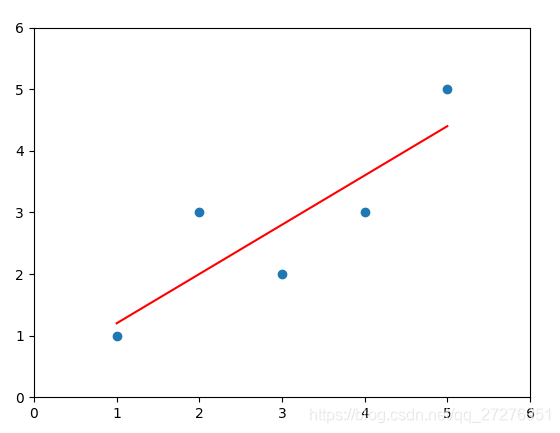
# 在求出a、b之后,可以计算出y的预测值,首先绘制模型直线:
y_hat = a * x + b
plt.scatter(x,y) # 绘制散点图
plt.plot(x,y_hat,color='r') # 绘制直线
plt.axis([0,6,0,6])
plt.show()
# 然后进行预测:
x_predict = 6
y_predict = a * x_predict + b
print(y_predict)
向量化应用:
在计算参数a时:
# a的分子num、分母d
num = 0.0
d = 0.0
for x_i,y_i in zip(x,y): # zip函数打包成[(x_i,y_i)...]的形式
num = num + (x_i - x_mean) * (y_i - y_mean)
d = d + (x_i - x_mean) ** 2
a = num / d向量w和向量v,每个向量的对应项,相乘再相加。其实这就是两个向量“点乘”
因此我们可以使用numpy中的dot运算,非常快速地进行向量化运算
向量化是非常常用的加速计算的方式,特别适合深度学习等需要训练大数据的领域
# 对于 y = wx + b, 若 w, x都是向量,那么,可以用两种方式来计算,第一是for循环:
# y = 0
# for i in range(n):
# y += w[i]*x[i]
# y += b
# 另一种方法就是用向量化的方式实现:
# y = np.dot(w,x) + b
# 二者计算速度相差几百倍,测试:
import numpy as np
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a, b)
toc = time.time()
print("c: %f" % c)
print("vectorized version:" + str(1000*(toc-tic)) + "ms")
c = 0
tic = time.time()
for i in range(1000000):
c += a[i] * b[i]
toc = time.time()
print("c: %f" % c)
print("for loop:" + str(1000*(toc-tic)) + "ms")运行结果:
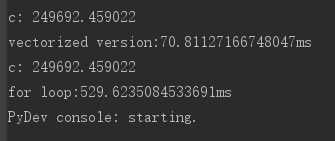
对于独立的样本,用for循环串行计算的效率远远低于向量化后,用矩阵方式并行计算的效率
因此:只要有其他可能,就不要使用显示for循环
【3】
在真实世界中,一个样本通常有很多(甚至成千上万)特征值的,这就需要引入多元线性回归
多元线性回归:在回归分析中,如果有两个或两个以上的自变量,就称为多元回归
对于下面的样本数据集对应的是一个向量,每一行是一个样本,每列对应一个特征。对应的结果可以用如下如下公式:
简单线性回归,只计算前两项,但是在多元线性回归中就要学习到n+1个参数,就能求出多元线性回归预测值:
也就是:第一个特征与参数1相乘、第二个特征与参数2相乘,累加之后再加上截距。就能得到预测值。
求解目标:已知训练数据样本,找到
,使
尽可能小。
其中是列向量列向量,而且我们注意到,可以虚构第0个特征X0,另其恒等于1,推导时结构更整齐,也更加方便:
改写成向量点乘的形式:
我们可以得出:
目标的向量化形式:已知训练数据样本 ,找到向量
,使
尽可能小。
多元线性回归的正规方程解:
该计算方法优点:不需要对数据进行归一化处理,原始数据进行计算参数,不存在量纲的问题(多选线性没必要做归一化处理)
缺点:时间复杂度较高:O(n^3),在特征比较多的时候,计算量很大
多元线性回归代码实现:
import numpy as np
from .metrics import r2_score
class LinearRegression:
def __init__(self):
"""初始化Linear Regression模型"""
self.coef_ = None # 系数(theta0~1 向量)
self.interception_ = None # 截距(theta0 数)
self._theta = None # 整体计算出的向量theta
def fit_normal(self, X_train, y_train):
"""根据训练数据X_train,y_train训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
# 正规化方程求解
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待预测的数据集X_predict,返回表示X_predict的结果向量"""
assert self.interception_ is not None and self.coef_ is not None, \
"must fit before predict"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
y_predict = X_b.dot(self._theta)
return y_predict
def score(self, X_test, y_test):
"""很倔测试机X_test和y_test确定当前模型的准确率"""
y_predict = self.predict(self, X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression()"标注:
1、np.hstack(tup):参数tup可以是元组,列表,或者numpy数组,返回结果为numpy的数组。按列顺序把数组给堆叠起来(加一个新列)。
2、np.ones():返回一个全1的n维数组,有三个参数:shape(用来指定返回数组的大小)、dtype(数组元素的类型)、order(是否以内存中的C或Fortran连续(行或列)顺序存储多维数据)。后两个参数都是可选的,一般只需设定第一个参数。(类似的还有np.zeros()返回一个全0数组)
3、numpy.linalg模块包含线性代数的函数。使用这个模块,可以计算逆矩阵、求特征值、解线性方程组以及求解行列式等。inv函数计算逆矩阵
4、T:array的方法,对矩阵进行转置。
5、dot:点乘
调用方法:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y<50.0]
y = y[y<50.0]
print(X.shape)
print(y.shape)
from myAlgorithm.model_selection import train_test_split
from myAlgorithm.LinearRegression import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, seed = 666)
reg = LinearRegression()
reg.fit_normal(X_train, y_train)
print(reg.coef_)
print(reg.interception_)
print(reg.score(X_test, y_test))

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









