







 本文介绍了如何配置Carla Server,包括无界面启动和Docker启动,并详细阐述了Carla Client的连接与控制。此外,文章详细讲解了Driving Benchmark的概念,解析了CoRL2017实验基准,包括四种导航任务,并展示了如何定制实验配置和定义智能体,为使用强化学习训练自动驾驶提供了基础。
本文介绍了如何配置Carla Server,包括无界面启动和Docker启动,并详细阐述了Carla Client的连接与控制。此外,文章详细讲解了Driving Benchmark的概念,解析了CoRL2017实验基准,包括四种导航任务,并展示了如何定制实验配置和定义智能体,为使用强化学习训练自动驾驶提供了基础。
1.Carla Server
Carla目前的稳定版为0.8.2,https://github.com/carla-simulator/carla/releases/tag/0.8.2 即可下载,linux解压后命令行执行
$ ./CarlaUE4.sh
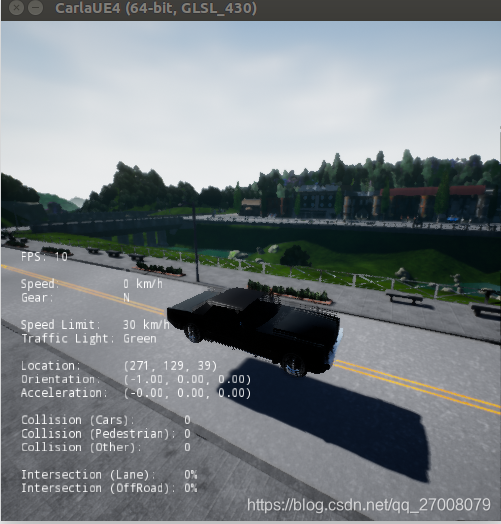
这将启动一个全屏的仿真窗口,你能使用WASD驾驶车辆
实验中往往增加各种参数进行配置
$ ./CarlaUE4.sh -carla-server -benchmark -fps=10 -windowed -ResX=300 -ResY=300
-
carla-server参数表示以服务端模式运行,等待客户端连接
-
benchmark fps=10 表示仿真中每一个step的时间间隔相同
-
windowed ResX=300 ResY=300 表示窗口化以及大小
1.1 无界面启动
配置环境变量:SDL_VIDEODRIVER=offscreen 和 SDL_HINT_CUDA_DEVICE=0
程序中可以这么写
my_env = {
**os.environ, 'SDL_VIDEODRIVER': 'offscreen', 'SDL_HINT_CUDA_DEVICE': '0', }
cmd = [path.join(environ.get('CARLA_ROOT'), 'CarlaUE4.sh'), self.map,
"-benchmark", "-carla-server", "-fps=10", "-world-port{}".format(self.port),
"-windowed -ResX={} -ResY={}".format(carla_config.server_width, carla_config.server_height),"-carla-no-hud"]
p = subprocess.Popen(cmd, env=my_env)
这个目前的缺点是默认第0块GPU,选择其他的会失效,在https://github.com/carla-simulator/carla/issues/225 有提到
如果你想能够选择gpu,可以选择下面的docker启动
1.2 docker启动
关于docker和nvidia docker的安装以及carla镜像的安装可以参考官网
在程序中
p = subprocess.Popen(['docker', 'run', '--rm', '-d', '-p',
str(self.port) + '-' + str(self.port + 2) + ':' +
str(self.port) + '-' + str(self.port + 2),
'--runtime=nvidia', '-e', 'NVIDIA_VISIBLE_DEVICES='+str(self.gpu),
"carlasim/carla:0.8.4",
'/bin/bash', 'CarlaUE4.sh', self.map, '-windowed',
'-benchmark', '-fps=10', '-world-port=' + str(self.port)], shell 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









