







 本文介绍jieba分词器的基本用法,包括不同模式下的分词方法如cut和cut_for_search,以及如何利用tf-idf提取关键词。此外还提到了在服务器环境下对大量文本进行处理的方法。
本文介绍jieba分词器的基本用法,包括不同模式下的分词方法如cut和cut_for_search,以及如何利用tf-idf提取关键词。此外还提到了在服务器环境下对大量文本进行处理的方法。
1、函数及用法
jieba.cut 方法接受三个输入参数:
- 需要分词的字符串
- cut_all 参数用来控制是否采用全模式
- HMM 参数用来控制是否使用 HMM 模型
jieba.cut_for_search 方法接受两个参数
- 需要分词的字符串
- 是否使用 HMM 模型。
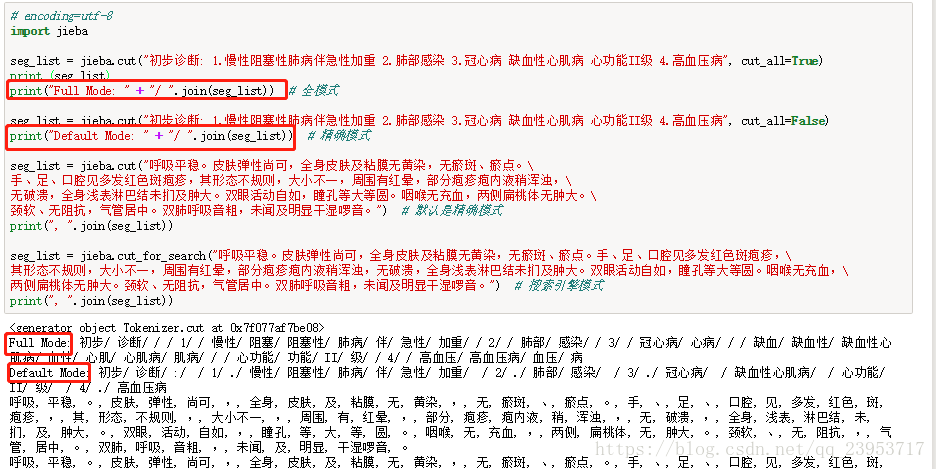
jieba.lcut以及jieba.lcut_for_search直接返回 list:




利用tf-idf来提取关键词和文本的tags:


另外,对于大量文本处理,在服务器,可以用命令行:

1、函数及用法
jieba.cut 方法接受三个输入参数:
jieba.cut_for_search 方法接受两个参数
另外,对于大量文本处理,在服务器,可以用命令行:
 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























