







尽管梯度下降(gradient descent)很少直接用于深度学习,但它是随机梯度下降算法的基础,也是很多问题的来源,如由于学习率过大,优化问题可能会发散,这种现象早已在梯度下降中出现。本文通过原理和示例对一维梯度下降和多元梯度下降进行详细讲解,以帮助大家理解和使用。
一维梯度下降
理论

从公式推导变化中,可以看出,目标函数确定之后,便是一直迭代展开,如果导数不为0则继续展开,直到满足停止条件。也可以帮助理解为什么要防止梯度为0的现象出现。
此外,也可以看到初始值和步长也影响最后的结果,在深度学习中就是我们设置的初始权重和学习率。
示例
下面我们来展示如何实现梯度下降。为了简单起见,我们选用目标函数f(x)=x**2。 尽管我们知道x=0时,目标函数取得最小值。但我们仍然使用这个简单的函数来观察
x的变化。
import torch
import numpy as np
def f(x): # 目标函数
return x ** 2
def f_grad(x): # 目标函数的梯度(导数)
return 2 * x
def gd(eta, f_grad):
x = 20.0
results = [x]
for i in range(20):
x -= eta * f_grad(x)
results.append(float(x))
print(f'epoch 20, x: {
x:f}')
return results
results = gd(0.2, f_grad)
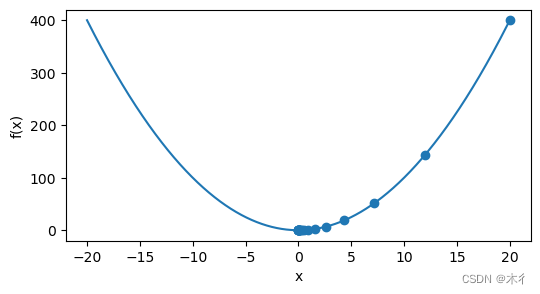
在示例中,我们使用x=20作为初始值,设置步长为0.2,。使用梯度下降法迭代x=20次。得到结果为:
epoch 20, x: 0.000731
可以看到,结果0.000731很接近真实结果0。
对于x的优化过程进行可视化,如下图所示。
import matplotlib.pyplot as plt
def show_trace(results, f):
n = max(abs(min(results)), abs(max(results)))
f_line = torch.arange(-n, n, 0.01)
# 设置图形大小
plt.figure(figsize=(6, 3))
# 绘制 f_line 的函数图像
plt.plot(f_line.numpy(), [f(x) for x in f_line.numpy()], '-')
# 绘制 results 的散点图
plt.scatter(results, [f(x) for x in results], marker='o')
# 设置 x 轴和 y 轴的标签
plt.xlabel('x')
plt.ylabel('f(x)')
# 显示图形
plt.show()
show_trace(results, f)
学习率
学习率的大小对结果的影响也很大,如果设置过小,很慢才能到达最优解,如果设置过大,可能会跳过最优解。
设置过小示例
当设置为0.02时。
def f(x):  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











