







文章目录
第八章 Spring AI实现RAG
8.1 概述
8.1.1 向量化
-
向量数据库(Vector Database)是一种以数学向量的形式存储数据集合的数据库,通过一个数字列表来表示维度空间中的一个位置。在这里,向量数据库的功能是可以基于相似性搜索进行识别,而不是精准匹配。比如说在使用一个商城系统的向量数据库进行查询的时候,用户输入“北京”,其可能返回的结果会是 “中国、北京、华北、首都、奥运会” 等信息;输入“沈阳”,其返回结果可能会是“东北、辽宁、雪花、重工业”等信息。当然,返回的信息取决于向量数据库中存在的数据。用户可以通过参数的设置来限定返回的情况,进而适配不同的需求。
-
嵌入模型(Embedding Model)和向量数据库(Vector Database/Vector Store)是一对亲密无间的合作伙伴,也是 AI 技术栈中紧密关联的两大核心组件,两者的协同作用构成了现代语义搜索、推荐系统和 RAG(Retrieval Augmented Generation,检索增强生成)等应用的技术基础。
8.1.2 RAG
1 RAG的基本概念
RAG,全称 Retrieval-Augmented Generation ,中文叫做检索增强生成。RAG是一种结合了检索系统和生成模型的新型技术框架,其主要目的有:
- 利用外部知识库
- 帮助大模型生成更加准确、有依据、最新的回答
通过使用RAG,解决了传统LLM存在的两个主要问题:
- 知识局限性:LLM的知识被固定在训练数据中,无法知道最新消息。
- 幻觉现象:LLM有时候会编造出并不存在的答案。
通过检索外部知识,RAG让模型突破了知识局限性,也让LLM(大语言模型)的幻觉现象得到解决。
2 RAG的使用场景
RAG技术可以用于多种应用场景,根据不同的知识库与提示词,适配不同的需求。下面是一些常见的典型使用场景
- 企业内部知识问答
- 需求:员工需要查询公司规章制度、流程文档、技术手册。
- RAG方案:
- 把企业文档库作为检索源。
- 用户提问时,检索相关文档段落。再由模型总结回答
- 金融/法律领域应用
- 需求:解答合规、财税、法律问题,要求答案严谨。
- RAG方案:
- 检索法条、案例、内部政策文档。
- 基于检索到的条款生成规范回答
- 电商/客服智能助理
- 需求:自动回答用户关于商品、物流、售后等问题
- RAG方案
- 检索商品知识库、FAQ文档
- 给出准确、即时的答复
- 医疗健康领域
- 需求:为患者或医生提供疾病知识、药物信息、医院信息、诊疗方案
- RAG方案
- 检索医疗文献、医院文档、指南资料
- 给出专业、可靠的医学服务
3 RAG工作流程概述
第一,用户输入问题
用户在输入窗口输入自己的问题,这一数据被接收,并作为后续处理的查询入口
例如:用户提问
“我的智能手表出现蓝牙连接问题,怎么办?”
第二,问题向量化
根据用户初始输入的问题,调用Embedding模型,将问题转换为高维向量,以便于后续的想来那个相似度检索。
文本:"我的智能手表出现蓝牙连接问题,怎么办?"
→ 向量:[0.123, 0.582, ..., 0.001]
第三,向量数据库检索
系统会连接到一个向量数据库(如FAISS、Milvus、Pinecone、Weaviate)。然后用刚才生成的问题向量,检索知识库中与之最相似的文档片段。
当检索的时候,常见的检索参数包括:
- Tok-K :检索最相关的K条记录
- 相似度阈值:控制检索到内容的相关性
最后输出的结果往往是K条知识片段
1. "蓝牙连接问题通常可以通过重启设备和重新配对解决。"
2. "如果手表固件版本较旧,请更新到最新版本以兼容蓝牙。"
3. "某些环境下,如电磁干扰,也会导致连接失败。"
第四,构建上下文
这一阶段需要组织提示词(Prompt),让LLM更好地理解背景信息。
这一部分包括:
-
系统提示词(System Prompt)
提前告诉LLM需要遵循的行为规范,比如
你是一个专业的智能手表客服助理。请基于提供的背景资料,准确回答用户的问题。如果资料中没有明确答案,请如实告诉用户而不是编造。系统提示词可以有效地设定模型角色、控制回答风格、防止幻觉
-
构造最终输入(Final Prompt)
一般会结合以上内容,按照如下格式进行组织
【背景资料】 1. 蓝牙连接问题通常可以通过重启设备和重新配对解决。 2. 如果手表固件版本较旧,请更新到最新版本以兼容蓝牙。 3. 某些环境下,如电磁干扰,也会导致连接失败。 【用户问题】 我的智能手表出现蓝牙连接问题,怎么办? 【回答要求】 请结合以上资料,用简洁明了的方式回答用户的问题。如果答案无法直接从资料中找到,请礼貌告知用户。
第五,调用LLM
将构造好的Prompt提交给LLM(比如Deepseek、Qwen、GPT-4o、Claude等)
- 模型读取检索到的内容和问题
- 组织自然、连贯、准确的回答
生成结果示例:
“您好! 根据我们的资料,您可以尝试重启智能手表并重新进行蓝牙配对。如果问题仍未解决,请检查手表固件是否为最新版本。如处于高电磁干扰环境,也可能影响连接质量,建议更换使用环境。”
第六,返回最终回答给用户
最终系统将生成的回答返回前端,展示给用户。
总结:
在RAG工作时,其运行流程大致为:
- 用户输入问题
- 问题向量化
- 向量数据库检索
- 构建上下文(含系统提示词)
- 携带检索内容,调用大模型进行回答
- 返回最终答案给用户
8.2 Spring AI 实现基本 RAG 流程
8.2.1 创建配置类
@Configuration
public class RagConfig {
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("你将作为一名Java开发语言的专家,对于用户的使用需求作出解答")
.build();
}
@Bean
VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(embeddingModel)
.build();
// 生成一个说明的文档
List<Document> documents = List.of(
new Document("产品说明:名称:Java开发语言\n" +
"产品描述:Java是一种面向对象开发语言。\n" +
"特性:\n" +
"1. 封装\n" +
"2. 继承\n" +
"3. 多态\n"));
simpleVectorStore.add(documents);
return simpleVectorStore;
}
}
- 通过这个配置类,完成以下内容:
1、配置 ChatClient 作为 Bean,其中设置系统默认角色为Java开发语言专家, 负责处理用户查询并生成回答向量存储配置。
2、初始化 SimpleVectorStore,加载Java开发语言说明文档,将文档转换为向量形式存储。
8.2.2 编写Controller
@Autowired
private ChatClient dashScopeChatClient;
@Autowired
private VectorStore vectorStore;
@GetMapping(value = "/chat", produces = "text/plain; charset=UTF-8")
public String generation(String userInput) {
// 发起聊天请求并处理响应
return dashScopeChatClient.prompt()
.user(userInput)
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.content();
}
- 通过添加 QuestionAnswerAdvisor 并提供对应的向量存储,可以将之前放入的文档作为参考资料,并生成增强回答。
8.2.3 测试
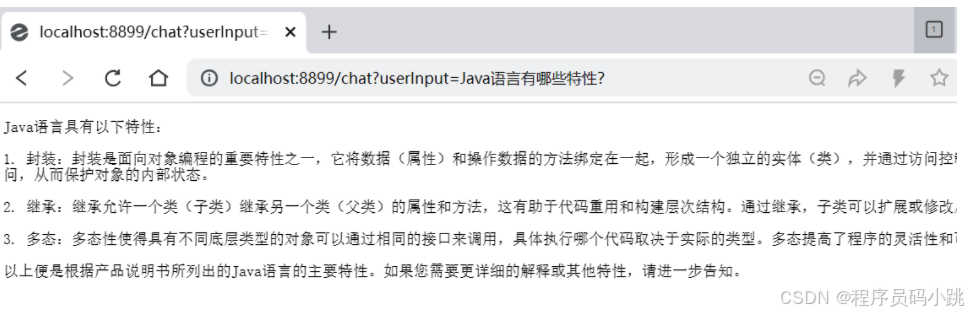



















 3940
3940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











