








 本文档记录了使用两个EfficientDet PyTorch实现过程中遇到的问题及解决办法,包括ModuleAttributeError的修复和NMS问题的讨论。此外,还介绍了如何将模型应用于自定义数据集,包括数据准备、训练参数调整等步骤,并分享了预测代码。尽管模型在实际应用中效果一般,但提供了进一步调试和优化的基础。
本文档记录了使用两个EfficientDet PyTorch实现过程中遇到的问题及解决办法,包括ModuleAttributeError的修复和NMS问题的讨论。此外,还介绍了如何将模型应用于自定义数据集,包括数据准备、训练参数调整等步骤,并分享了预测代码。尽管模型在实际应用中效果一般,但提供了进一步调试和优化的基础。
问题1:torch.nn.modules.module.ModuleAttributeError: 'EfficientDet' object has no attribute 'module'
model.module.is_training = True
model.module.freeze_bn()
改为:
model.is_training = True
model.freeze_bn()问题2:No boxes to NMS
在issue中看了关于这个问题的讨论,这个问题是普遍存在的,建议换一个。。。。
经过反复尝试,确实不行,但是仍然给出我修改了以后能正常跑起来但预测没有效果的更改,至少数据加载那些改成了加载自己数据集的。下面简要说下
1.数据准备
该项目里有两种数据加载方式,VOC和COCO,所以我们需要做的就是更改自己的数据为这两种数据中的一种,目录结构如下:
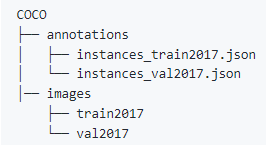
具体如下:
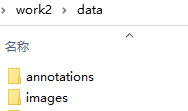
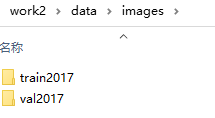
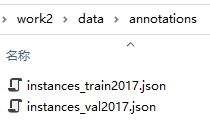
2.训练
--dataset 选择我数据的格式COCO
--dataset_root 数据根目录
--network 表示网络结构 d0, .... d7一共八种自己选
--num_class 类别数别忘了改成自己的
--device 显卡设备列表 --gpu 选择使用的gpu
--workers 线程个数,workers大于0的时候,Windows经常报错
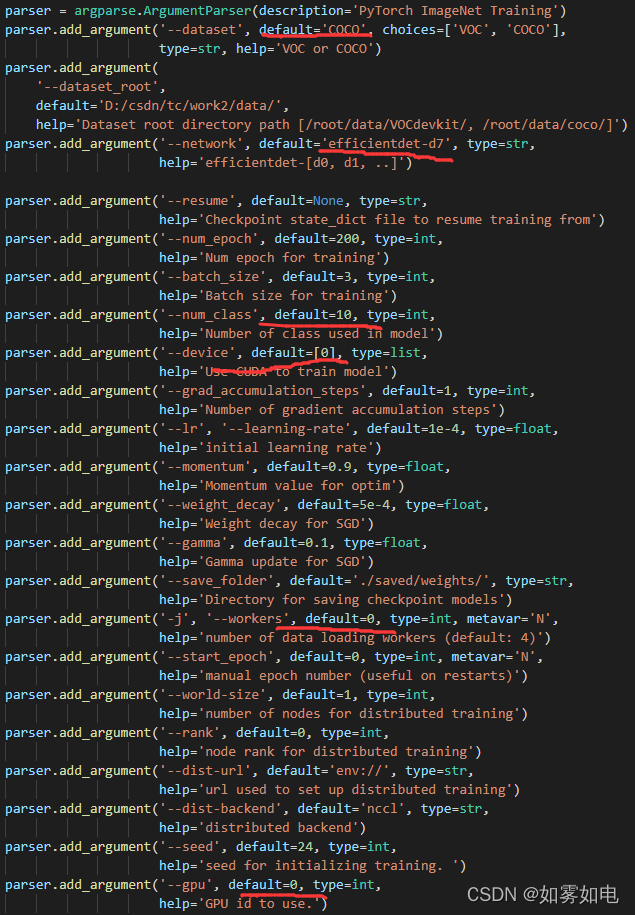
改完上面就可以跑了,我跑完测试检测不出结果,下面换一个跑跑
https://github.com/signatrix/efficientdet https://github.com/signatrix/efficientdet1.按照上面的方式将自己的数据准备得跟COCO数据集格式一样
https://github.com/signatrix/efficientdet1.按照上面的方式将自己的数据准备得跟COCO数据集格式一样
2.简单修改下训练文件
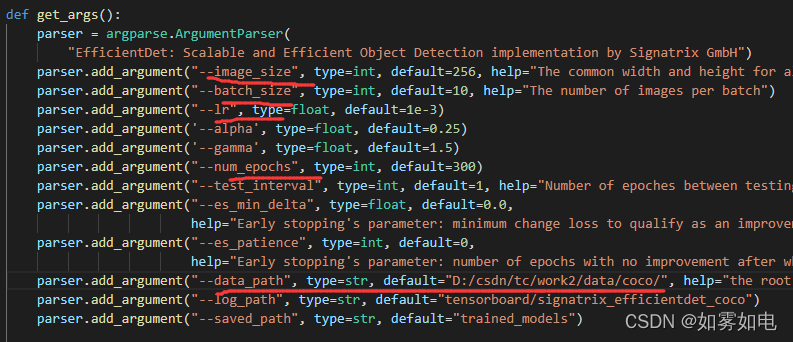
基本上就是改基础的训练参数,模型的存储位置那些都是自动保存
数据的路径给根目录就行
3.效果,实际效果一般,我自己也没好好做,还需要自己好好调试,我用阿里的竞赛做了测试,评分差不多才0.6左右,竞赛的链接里面有数据
零基础入门CV - 街景字符编码识别-天池大赛-阿里云天池零基础入门CV - 街景字符编码识别本次新人赛是Datawhale与天池联合发起的零基础入门系列赛事第二场 —— 零基础入门CV赛事之街景字符识别,赛题以计算机视觉中字符识别为背景,要求选手预测真实场景下的字符识别,这是一个典型的字符识别问题。 https://tianchi.aliyun.com/competition/entrance/531795/introduction?spm=5176.12281925.0.0.26087137F5M0lm4.预测代码我改了一下,predict.py如下(用于得到阿里那个比赛的标准输出):
https://tianchi.aliyun.com/competition/entrance/531795/introduction?spm=5176.12281925.0.0.26087137F5M0lm4.预测代码我改了一下,predict.py如下(用于得到阿里那个比赛的标准输出):
# coding: utf-8
from ast import RShift
import os
import argparse
import torch
from torchvision import transforms
from src.dataset import CocoDataset, Resizer, Normalizer
from src.config import COCO_CLASSES, colors
import cv2
import shutil
import numpy as np
import pandas as pd
import json
def get_args():
parser = argparse.ArgumentParser(
"EfficientDet: Scalable and Efficient Object Detection implementation by Signatrix GmbH")
parser.add_argument("--image_size", type=int, default=448, help="The common width and height for all images")
parser.add_argument("--data_path", type=str, default="D:/csdn/tc/work2/data/", help="the root folder of dataset")
parser.add_argument("--cls_threshold", type=float, default=0.4)
parser.add_argument("--nms_threshold", type=float, default=0.5)
parser.add_argument("--pretrained_model", type=str, default="trained_models/signatrix_efficientdet_coco.pth")
parser.add_argument("--output", type=str, default="predictions")
args = parser.parse_args()
return args
class Resizer():
"""Convert ndarrays in sample to Tensors."""
def __call__(self, image, common_size=512):
height, width, _ = image.shape
if height > width:
scale = common_size / height
resized_height = common_size
resized_width = int(width * scale)
else:
scale = common_size / width
resized_height = int(height * scale)
resized_width = common_size
image = cv2.resize(image, (resized_width, resized_height))
new_image = np.zeros((common_size, common_size, 3))
new_image[0:resized_height, 0:resized_width] = image
return torch.from_numpy(new_image), scale
class Normalizer():
def __init__(self):
self.mean = np.array([[[0.485, 0.456, 0.406]]])
self.std = np.array([[[0.229, 0.224, 0.225]]])
def __call__(self, image):
return ((image.astype(np.float32) - self.mean) / self.std)
if __name__ == "__main__":
opt = get_args()
checkpoint_file = opt.pretrained_model
model = torch.load(opt.pretrained_model).module
model.cuda()
d = {}
df = pd.DataFrame(columns=['file_name','file_code'])
image_path = "D:/csdn/tc/work2/data/mchar_test_a/"
save_path = ''
piclist = os.listdir(image_path)
piclist.sort()
index = 0
common_size = 256 # datasets.py Resizer
for pic_name in piclist:
# if index == 10:
# break
index += 1
if index % 1000 == 0:
print(f"{index}/40000")
pic_path = os.path.join(image_path, pic_name)
# print(pic_path)
img = cv2.imread(pic_path)
img1 = img
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.
img = Normalizer()(img)
img, scale = Resizer()(img, common_size=common_size)
with torch.no_grad():
scores, labels, boxes = model(img.cuda().permute(2, 0, 1).float().unsqueeze(dim=0))
boxes /= scale
ss = ''
dts = []
if boxes.shape[0] > 0:
# path = os.path.join(opt.output, pic_name)
# output_image = cv2.imread(path)
output_image = img1
for box_id in range(boxes.shape[0]):
pred_prob = float(scores[box_id])
if pred_prob < opt.cls_threshold:
break
pred_label = int(labels[box_id])
xmin, ymin, xmax, ymax = boxes[box_id, :]
dts.append({'class':COCO_CLASSES[pred_label], 'xmin':xmin.item()})
# ss += str(COCO_CLASSES[pred_label])
temp = sorted(dts, key = lambda i: i['xmin'])
for e in temp:
ss += e['class']
df = df.append([{"file_name": pic_name, "file_code": ss}], ignore_index=True)
df.to_csv("sub2.csv",index=False)说明:这个网络没时间好好调参了,下面给出我用的代码(包含数据)
链接:https://pan.baidu.com/s/1vR8vnCT2yQH7unwYREVn8Q
提取码:kz3d
--来自百度网盘超级会员V5的分享


















 4149
4149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











