







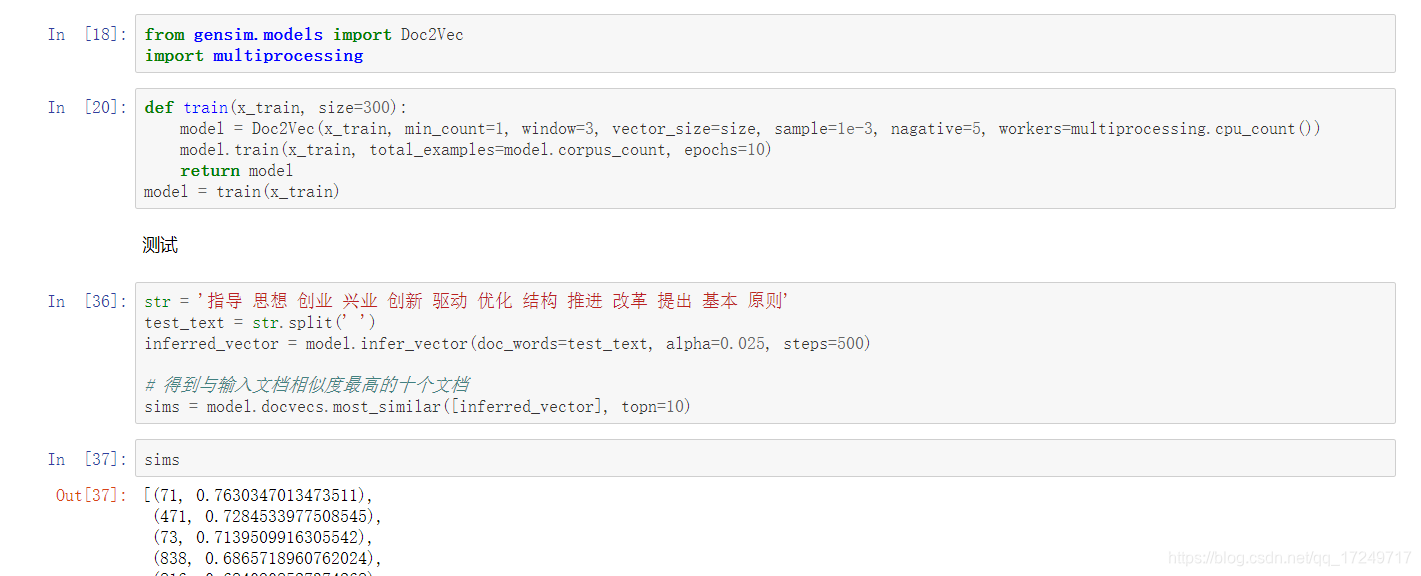
 这篇博客介绍了如何将文本数据转化为list of list结构,然后应用gensim库的Doc2Vec模型进行训练。通过分词、去除停用词等预处理步骤,将文本转换为适合训练的格式。在训练过程中,可以选择DM或DBOW模型,根据dm参数来决定模型类型。
这篇博客介绍了如何将文本数据转化为list of list结构,然后应用gensim库的Doc2Vec模型进行训练。通过分词、去除停用词等预处理步骤,将文本转换为适合训练的格式。在训练过程中,可以选择DM或DBOW模型,根据dm参数来决定模型类型。
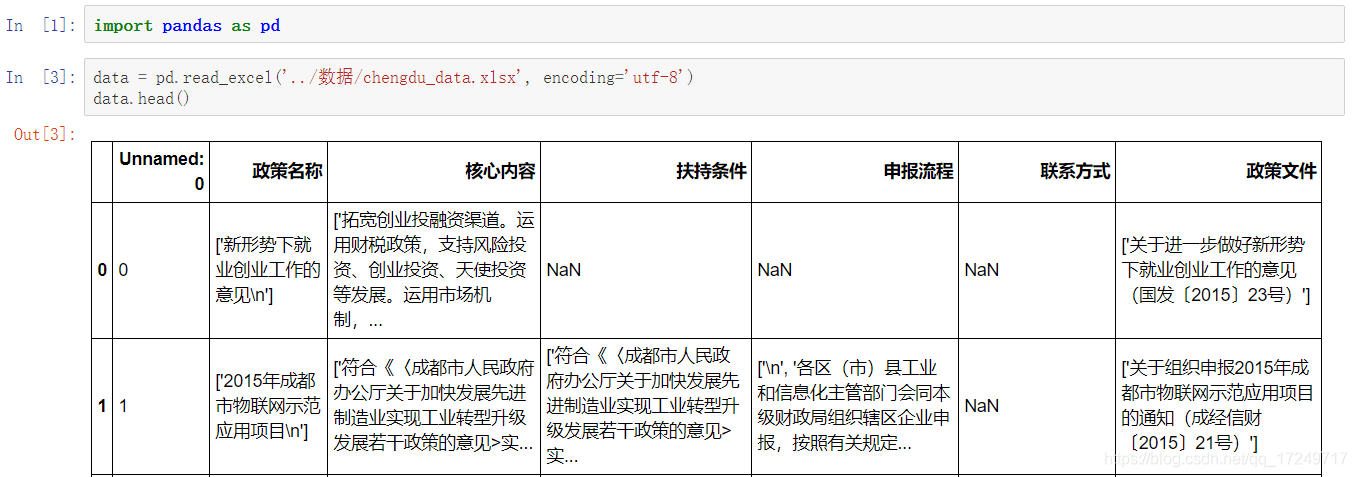
将文本数据表示成list of list的形式:
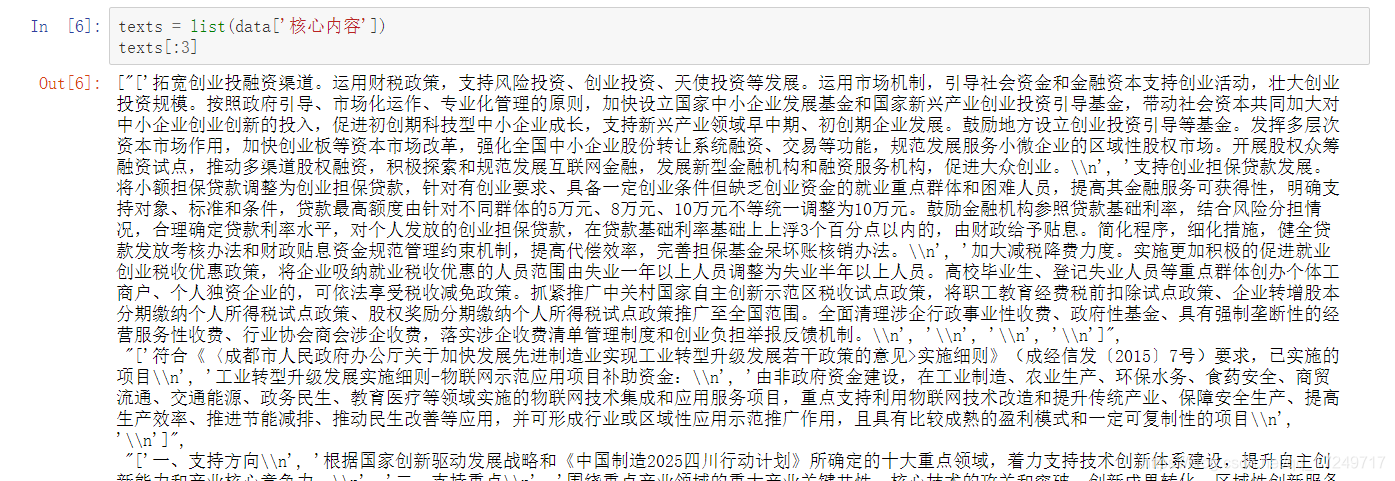
对每一条文本进行分词操作,可能的话,去除停用词,加上自定义词等:
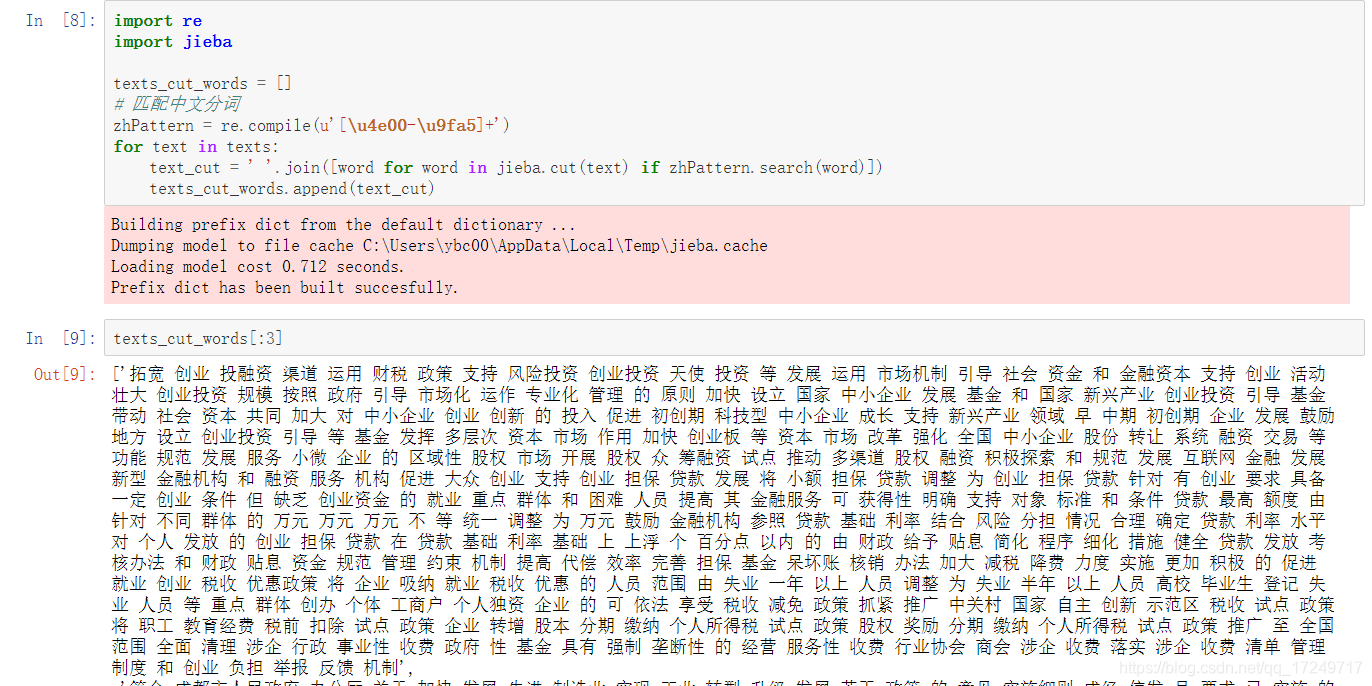
将分词后的文本转换为gensim所需要的形式:
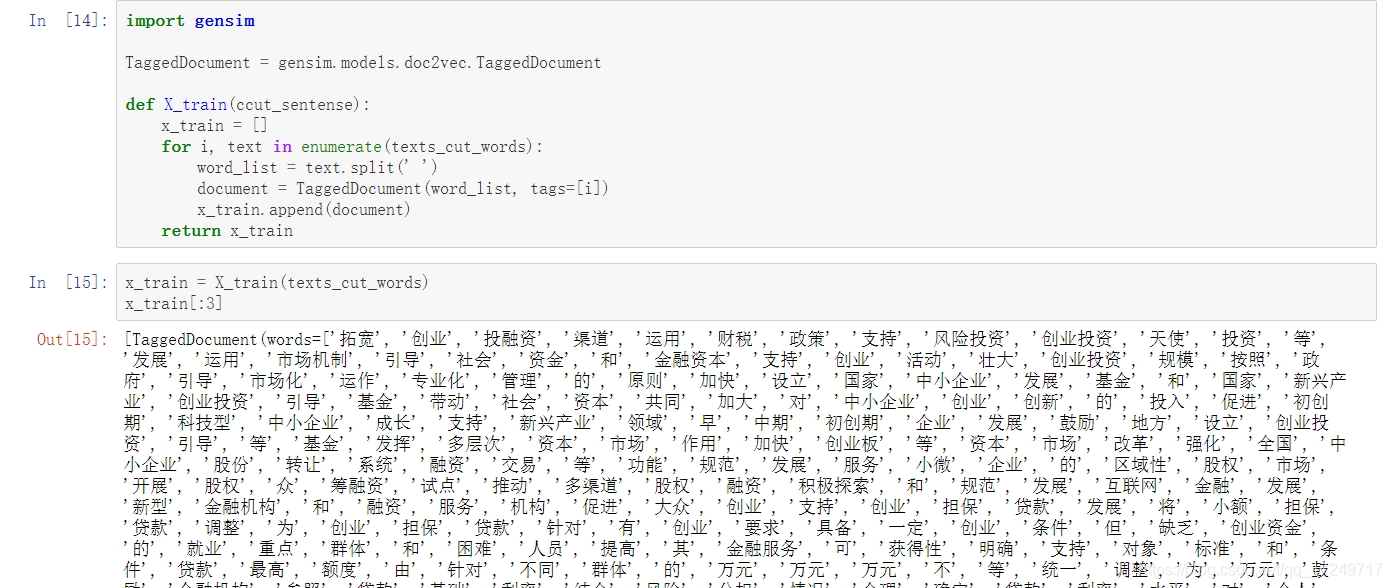
训练Doc2Vec,其中参数dm=1表示DM模型,dm=0表示DBOW模型。(此处没有写,dm参数放在Doc2Vec()函数中)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















06-25
 475
475
475
将文本数据表示成list of list的形式:
对每一条文本进行分词操作,可能的话,去除停用词,加上自定义词等:
将分词后的文本转换为gensim所需要的形式:
训练Doc2Vec,其中参数dm=1表示DM模型,dm=0表示DBOW模型。(此处没有写,dm参数放在Doc2Vec()函数中)
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









