



在深度学习和推荐系统领域,基于Transformer的端到端典型案例中最具代表性的是行为序列建模推荐系统(Sequential Recommendation),尤其是阿里巴巴提出的BST模型。该模型直接将用户历史行为序列作为输入,通过Transformer编码器进行端到端训练,预测用户对目标物品(如电影、商品)的偏好和评分。
下面我们将以BST模型在MovieLens数据集上预测用户对电影评分为例,进行端到端的详细分析,涵盖:任务定义、输入构造、模型架构、训练流程、损失函数、推理机制及优势特点。
一、任务定义:评分预测(Rating Prediction)
- 目标:给定用户的历史行为序列和目标电影,预测用户对该电影的评分(1·5分)。
- 本质:回归任务(也可转为分类任务)。
- 关键挑战:捕捉用户兴趣的动态演化(如从“动作片”转向“科幻片”)。
这是一个典型的上下文感知的序列推荐问题,而非仅基于协同过滤的静态推荐。
二、输入特征设计(多模态融合)
BST 模型的输入是 结构化+序列化 的混合特征,全部送入Transformer进行联合建模:
1、用户行为序列(核心)
对每个用户,按时间排序其历史交互记录,截取最近L个行为(如L=50):
- movie_id_seq:[movie_123,movie_456,…,movie_789]
- rating_seq:[4.0,5.0,…,3.0](可选,增强信号)
- timestamp_seq:用于生成位置编码(或直接用行为顺序作为位置)
2.目标物品(Target Item)
- target_movie_id
- target_genres(如[“Romance”,“Comedy”])
3.用户静态画像(User Profile)
- user_id
- sex(“M”/“F”)
- age_group(如“group_25”)
- occupation(如“occupatiohn_4”)
4.电影元信息(Movie Features)
每部电影(包括序列中和目标)都关联其类型(genres),例如:
- movie_123 —> [“Action”,“Sci_Fi”]
所有类别型特征(如user_id、movie_id、genre)都将被嵌入(Embedding)为向量。
三、架构模型:端到端Transformer编码器
整个模型是一个纯前馈、无循环的端到端神经网络,结构如下:
[Input Features]
↓
[Feature Embedding Layer] → 拼接所有嵌入向量
↓
[Sequence Construction] → 构造行为序列的 token 表示(含位置编码)
↓
[Transformer Encoder] → 多层自注意力 + FFN
↓
[Pooling / Target Attention] → 聚合序列表示
↓
[MLP Head] → 预测评分
↓
[Output: predicted_rating]
1.特征嵌入(Embedding)
user_id → eu∈Rd
movie_id → em∈Rd
genre → 多标签嵌入(如平均多个 genre 向量)
rating → 可学习的连续值嵌入(或线性投影)
对序列中的每个行为i,构造其token表示:

注意:这里将rating和genre融合进token表示,而非作为外部特征,这里对原始BST的改进。
2.Transformer编码器
将序列化 X输入标准Transformer编码(通常2~4层):
- 每层包含:
- Multi-Head Self-Attention
- LayerNorm + Residual
- Position-wise Feed-forward Network
输出:上下文感知的序列表示H=[h1, h2, …, hL]
3.序列聚合(Pooling)
常用方法:
- 全局平均池化(Mean Pooling)
- 最后时刻表示(hL)
- Target-aware Attention:用目标电影嵌入作为query,对H做加权聚合
例如:
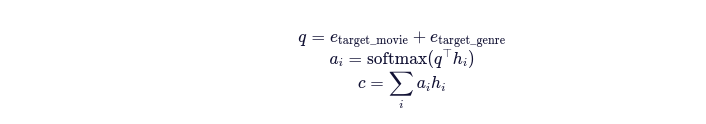
4.预测头(Prediction Head)
将以下向量拼接后输入MLP:
- 用户画像嵌入 eu
- 目标画像嵌入 etarget
- 序列上下文向量 c
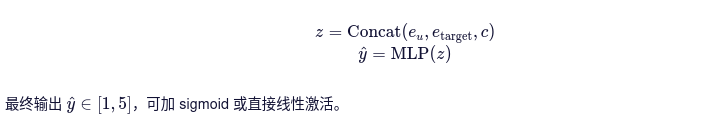
四、训练流程(端到端监督学习)
1.数据准备
- 从MovieLens-1M 加载 users、movies、ratings;
- 按user_id分组,按timestamp排序;
- 对每个用户,滑动窗口构造样本:
(history_seq, target_movie, true_rating)
2.损失函数
使用均方误差(MSE):

3.优化器
- AdamW(带权重衰减)
- 学习率调度(如warmup + cosine decay)
4.训练细节
- Batch size:256~1024
- 序列长度L:50(不足补零,mask padding)
- Embedding维度d:64~128
- 使用tf.data 或torch.utils.data.DataLoader高效加载
五、推理与部署
-
离线训练:在全量用户行为日志上训练模型
-
在线推理:
- 实时获取用户最近L个行为;
- 构造输入特征;
- 模型输出对候选电影的预测评分;
- 排序后返回top-K推荐。
可扩展为 召回+排序 两阶段:先用简单模型召回1000步电影,再用BST精排。
六、为什么是“端到端”?
- 输入:原始行为日志(movie_id, rating, timestamp)+用户/电影元数据;
- 输出:预测评分;
- 中间过程:所有特征嵌入、序列建模、注意力计算、预测全部由一个神经网络完成;
- 无需手工特征工程:如统计用户平均评分、热门度等传统特征不再需要。
模型自动学习:哪些历史行为重要?类型如何影响兴趣?性别是否相关?----全部由数据驱动。
七、优势与创新点
| 特征 | 说明 |
|---|---|
| 序列建模能力强 | 自注意力捕捉长期依赖,优于RNN/LSTM |
| 多特征融合 | 用户画像、电影类型、评分、位置统一建模 |
| 并行训练 | 比RNN快得多,适合大规模数据 |
| 可解释性 | 通过注意力权重分析用户关注哪些历史行为 |
| 灵活性高 | 易扩展至点击率预测(CTR)、购买预测等任务 |
八、实际效果(MovieLens-1M上)
-
指标:RMSE(越低越好)
- 协同过滤(SVD):≈0.90
- GRU4Rec: ≈0.87
- BST(Transformer):≈0.83
-
表明Transformer能更精确捕捉用户兴趣额演化。

















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









