




 本文介绍如何使用Python免费抓取A股历史行情数据,从寻找提供数据的网站,分析百度股市通网页,到抓取并保存数据,详细讲解了整个过程,包括关键参数的识别和使用。
本文介绍如何使用Python免费抓取A股历史行情数据,从寻找提供数据的网站,分析百度股市通网页,到抓取并保存数据,详细讲解了整个过程,包括关键参数的识别和使用。
上一节我们学习了如何抓取A股的股票列表,我们成功地将股票列表保存到了本地文件(或数据库)中。那么这一节,我们就来看下如何免费获取A股的历史行情数据。文末附全套代码。
一、寻找提供行情数据的网站
首先我们百度搜索一支股票的名字+行情,看下都哪些网站提供该数据。
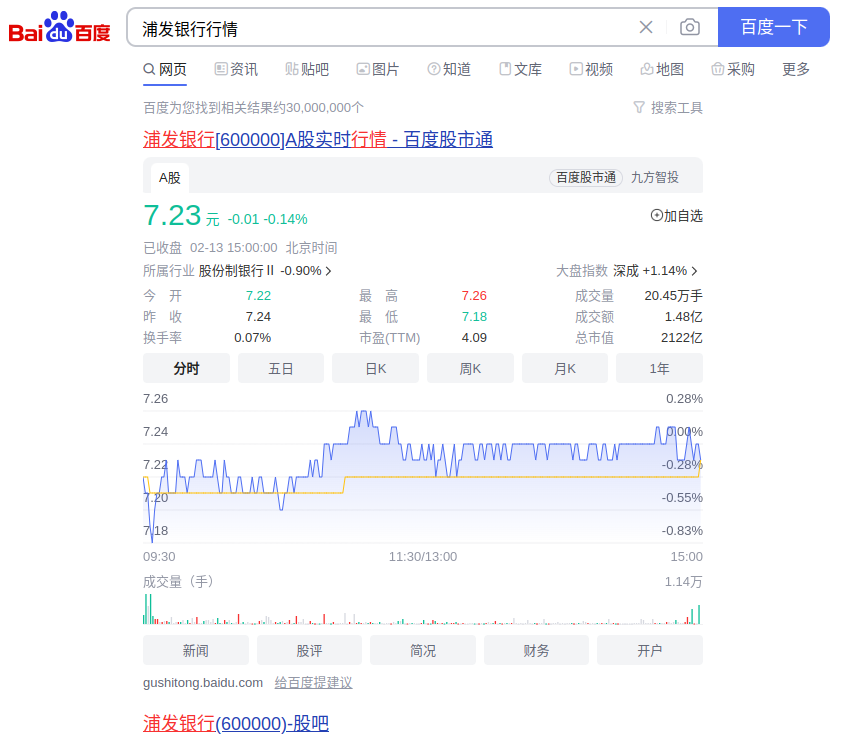
可以看到,第一个搜索结果就是百度自家的股市通提供的数据,再往后翻还能看到东方财富、新浪财经等网站。那么我们就先看下百度股市通的数据是否好抓取。
二、分析百度股市通网页
我们点击链接进入百度股市通中的“浦发银行”行情页面,进入开发者工具(F12),点击网络选项卡。
我们要抓取的是日线数据,所以我们先点击网络选项卡中的“清除”按钮,然后在左侧网页中点击“日K”。
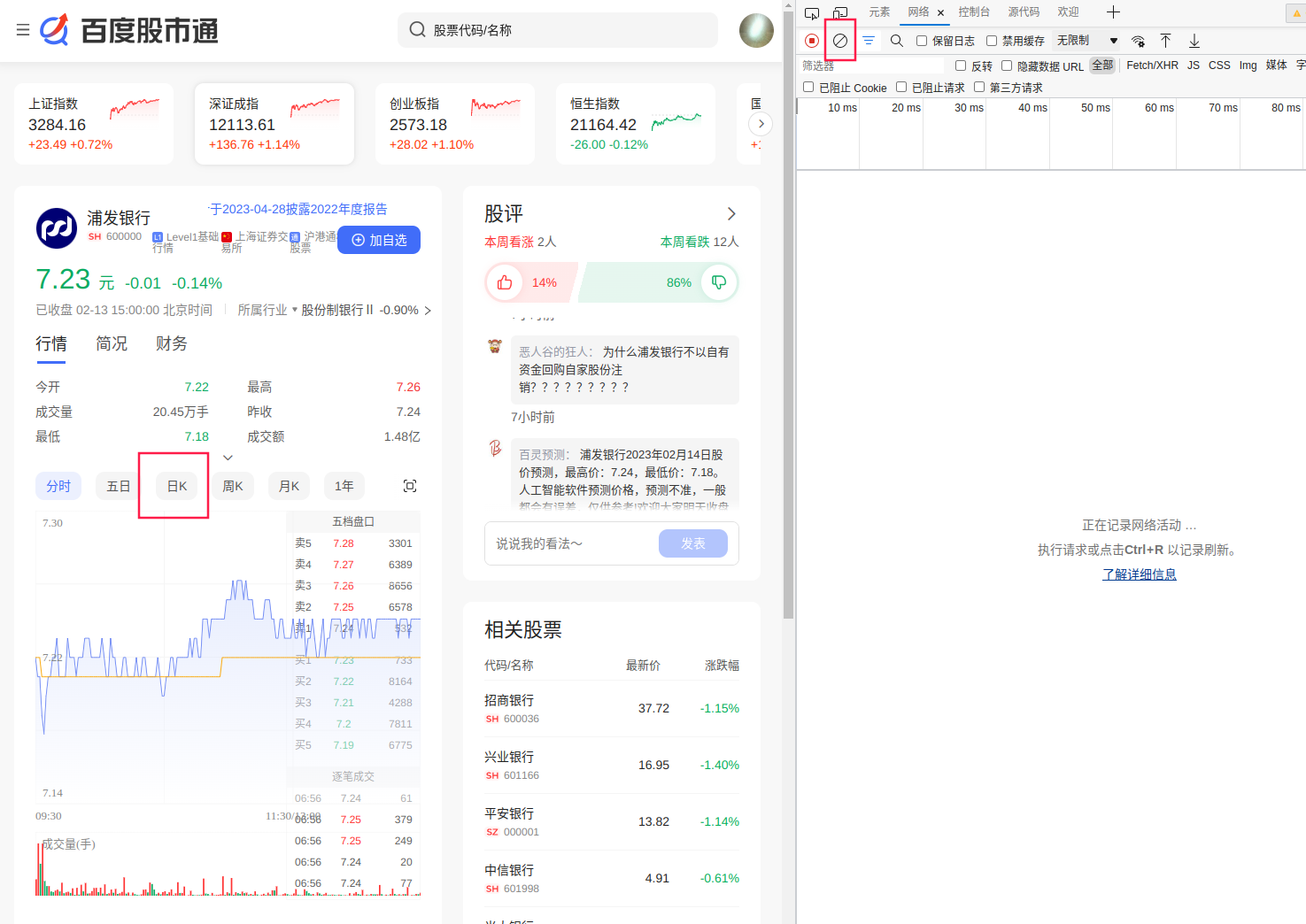
上节课我们提到过,XHR类型的请求很可能会包含我们所需的数据,需要重点关注。XHR实际上是一种异步请求,可以帮助网站实现不同资源的异步加载。像这种我们点击一下“日K”才加载出来的数据,非常适合通过这样的方式来处理。否则,对于每一次请求来说,很有可能会有大量冗余的数据请求同时触发,这对网站或者用户来说都不是很友好。
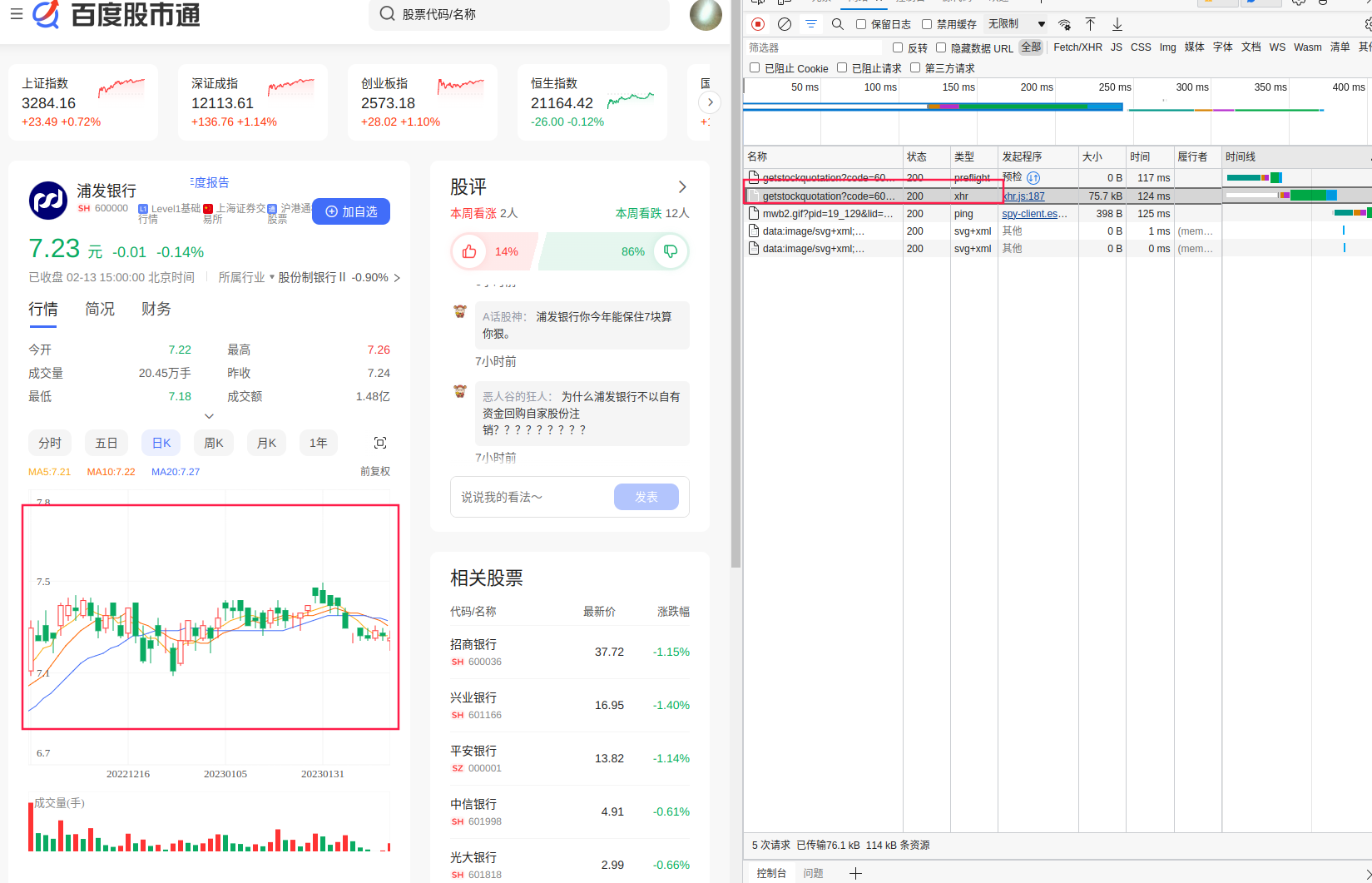
我们点击这一条请求,看一下返回的内容是什么。在预览标签里,我们把小三角层层点开,看起来这里边就是我们需要的日线行情数据,甚至百度还随着接口提供了一些均线数据(不过这些数据我们完全可以自己按需计算)。数据是JSON格式,非常规整,似乎我们直接发起请求并以JSON格式处理响应结果就好了。
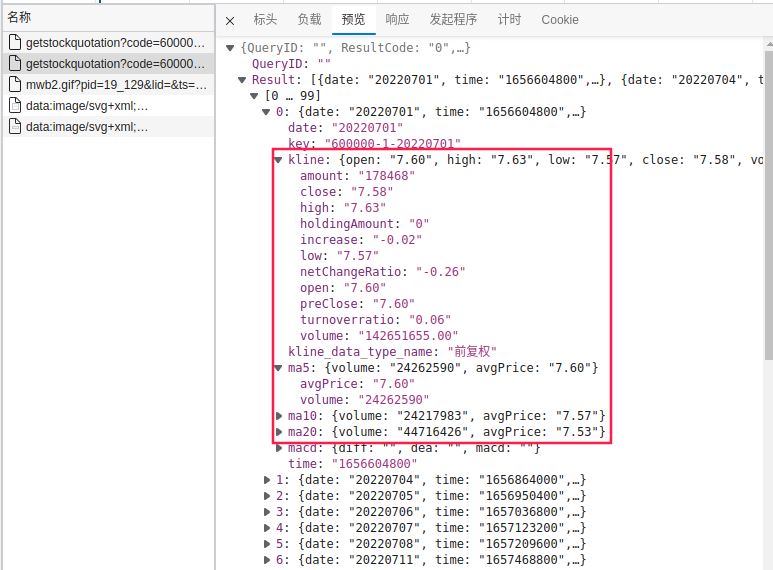
那么我们再来看看请求信息。
https://finance.pae.baidu.com/selfselect/getstockquotation?code=600000&all=1&ktype=1&isIndex=false&isBk=false&isBlock=false&isFutures=false&stockType=ab&group=quotation_kline_ab&finClientType=pc
code=600000,很明显这个参数就是用来指定股票代码的。all=1,从名字上看好像是指定全部数据还是部分数据。
剩下的一大堆参数从名字上判断不出来是做什么。看起来比较有用的参数就是上边两个,我们测试一下。
import requests
import json
url = ('https://finance.pae.baidu.com/selfselect/getstockquotation?code='
'600000&all=1&ktype=1&isIndex=false&isBk=false&isBlock=false'
'&isFutures=false&stockType=ab&group=quotation_kline_ab&finClientType=pc')
req = requests.get(url)
res = json.loads(req.text)
res
输出如下。看起来行情数据藏在Result这个KEY下。我们看下有多少条数据。
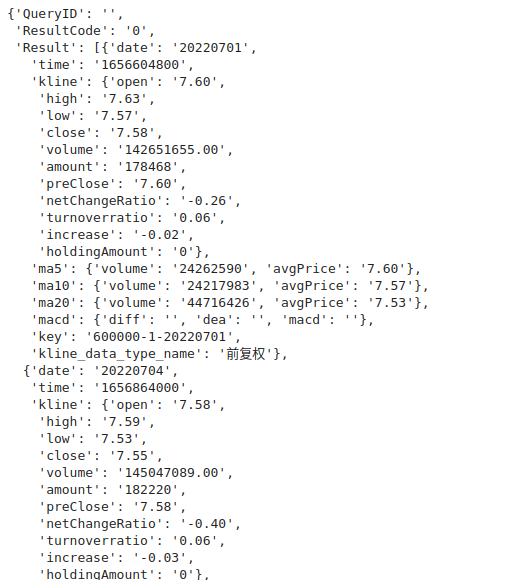
print(len(res['Result']))
输出为150条。很明显,all=1并不能帮助我们获取全部历史数据。但是链接里目前也没看到其他的参数像是用于指定时间区间的。那么我们再回到网页,看下是不是还有其他的异步加载。
很快,我们就可以发现,这个K线图的区域是可以拖动的,我们一直往左找更早的历史数据。这时,在右侧的网络选项卡中又出现了一大堆请求,其中包含了一些跟我们刚看的接口非常相似的XHR请求,里边出现的数据的确是我们需要的更久远的数据。我们再来看一下这个请求中的参数有什么不同。
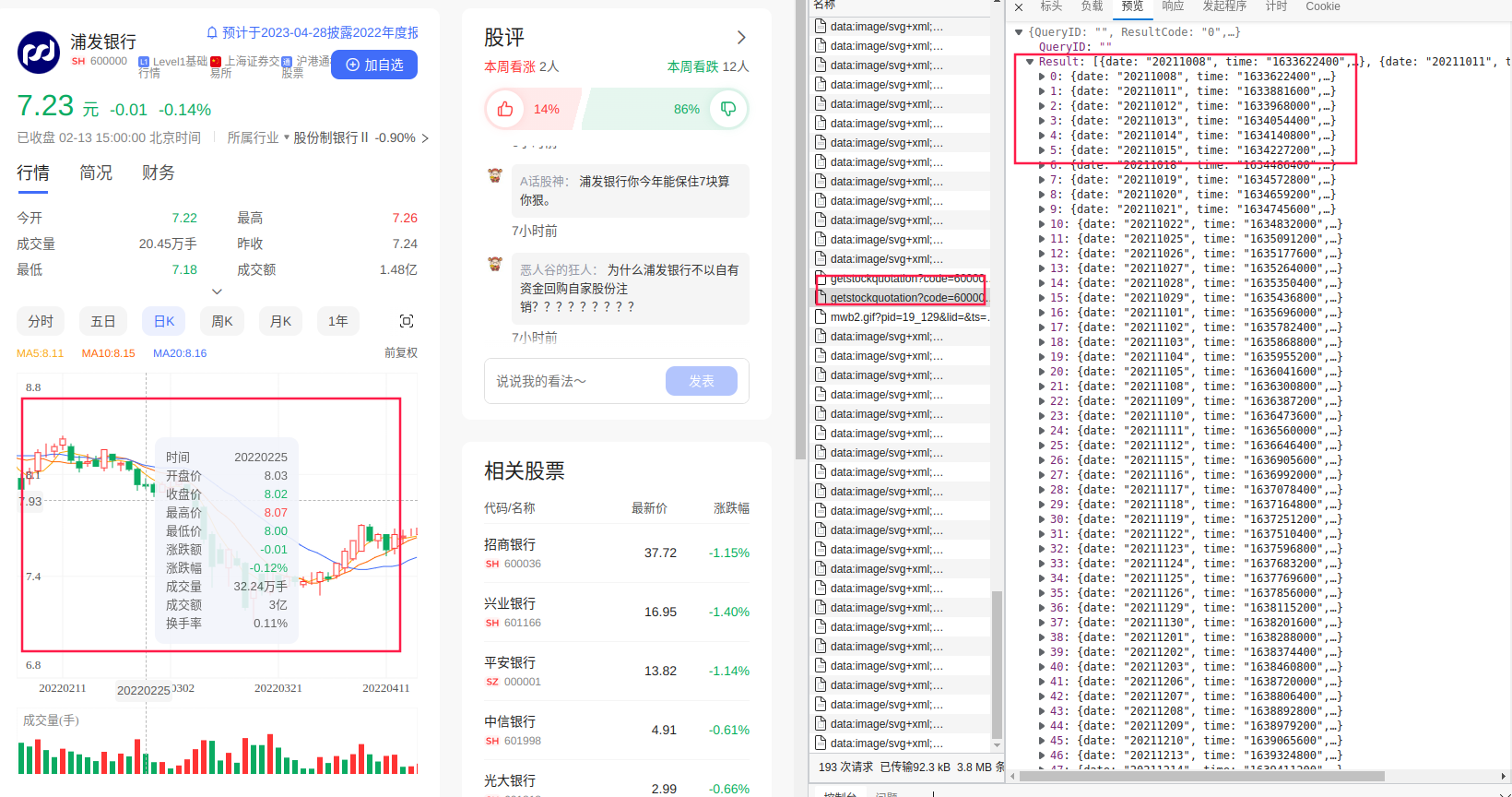
在标头选项卡中,我们找到了请求链接如下:
https://finance.pae.baidu.com/selfselect/getstockquotation?code=600000&all=0&count=90&ktype=1&isIndex=false&isBk=false&isBlock=false&isFutures=false&stockType=ab&end_time=1645113600&group=quotation_kline_ab&finClientType=pc
- 我们注意到这次
all参数的取值变成了0。 - 这次请求比上次多了个
count=90,这个90和本次请求的数据长度一致,看来它对应着本次请求最多返回多少个交易日的数据。经过测试,该值最大可以提升到250。 - 我们在后边还注意到了一个
end_time=1645113600参数,通过datetime库我们可以很方便地查到这个时间戳对应的是UTC+8时间的2022年2月18日,也就是这次请求的最后一条数据对应的日期。所以我们通过end_time和count的组合就可以控制每次抓取的时间范围了。
有了这几个参数,我们应该就可以获取我们想要的行情数据了。经过老Q测试,有很多参数是不必要的,但是像group、ktype这两个参数是必需的。
三、抓取并保存数据
上一节课我们已经演示过了如何解析JSON数据,所以这里就不细讲了,我们直接开干。看下抓取到的内容:
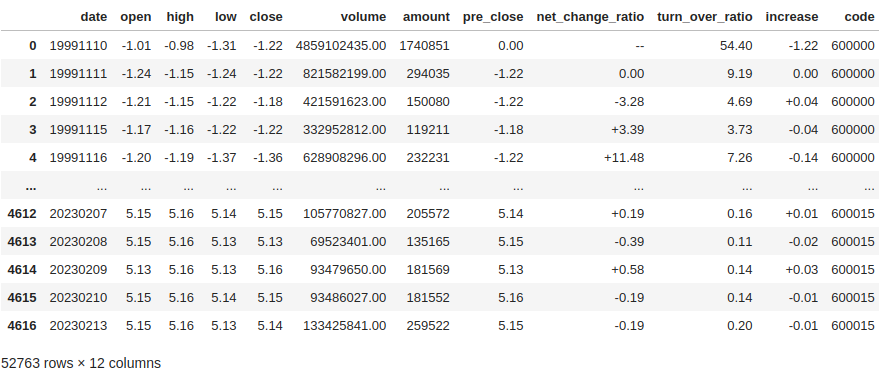
抓取股票行情的代码如下。如果大家想要将结果数据写入数据库而非本地文件,可以参考上一节课的内容。对代码有疑问的同学,可以购买专栏后跟老Q咨询,现在刚好是新课期,有比较大的优惠,机不可失,失不再来哦!
import pandas as pd
import requests
import datetime
import json
def get_quotes(code):
data_list = []
today = datetime.datetime.today().strftime('%Y-%m-%d')
ctime = str(int(datetime.datetime.strptime(today, '%Y-%m-%d').timestamp()))
next_end_time = ctime
while True:
res, length = get_quotes_once(code, next_end_time)
if length > 0:
data, next_end_time = parse_quotes(res)
data_list.extend(data)
else:
break
# time.sleep(1)
columns = ['date', 'open', 'high', 'low', 'close', 'volume', 'amount',
'pre_close', 'net_change_ratio', 'turn_over_ratio', 'increase']
df = pd.DataFrame(data_list, columns=columns)
df['code'] = code
df = df.sort_values('date').reset_index(drop=True)
return df
def get_quotes_once(code, end_time):
url = ('https://finance.pae.baidu.com/selfselect/getstockquotation?'
'code={0}&all=0&count=250&ktype=1&group=quotation_kline_ab'
'&end_time={1}').format(code, end_time)
res = json.loads(requests.get(url).text).get('Result')
return res, len(res)
def parse_quotes(res):
kline_cols = ['open', 'high', 'low', 'close', 'volume', 'amount',
'preClose', 'netChangeRatio', 'turnoverratio', 'increase']
data = [[i['date'], *[i['kline'][col] for col in kline_cols]] for i in res]
next_end_time = str(int(res[0]['time']) - 86400)
return data, next_end_time
if __name__ == '__main__':
df_list = pd.read_csv('sha_list.csv')
code_list = df_list['股票代码'].values[:10]
a = time.time()
dfs = [get_quotes(code) for code in code_list]
b = time.time()
print(b - a)
df = pd.concat(dfs, axis=0)
df.to_csv('stock_quotes.csv', index=False)



















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











