




到了这一步,我们学习了基础的爬虫请求库urllib和requests,尤其是后者,强大且易用,极其适合新手使用。那么今天我们就找一个相对简单的案例,来看一下如何在实战中应用爬虫技能。
相信很多朋友都对股票感兴趣,甚至有些朋友想要通过量化研究来获得超额收益。然而,想要进行量化研究,我们首先得先有数据。暂且不说各种财务数据、行业数据、新闻公告等相对复杂的,我们至少得有个股票列表和历史行情数据吧?
如今市场上能为散户提供数据的,有一些公开的接口,不过为了得到比较好的体验,基本上还是得花一些钱,比如强大的tushare接口,提供了极为丰富的数据。但是不同的数据以及不同的请求频次对应着不同的门槛,每年成本从数百到数千不等。还有一些如baostock、IG507、Ashare等,但都有一定的使用限制(主要是指请求量级和频次)。
如果我们想要快速对历史全量的行情数据进行建模分析,使用这些接口是极为不便的。毕竟以这些接口的请求速度,我们实际花费在数据请求上的时间会远远超过我们进行建模、计算的时间。
因此,把历史数据抓取并保存到数据库中,就势在必行了。当然,如果已经是这些接口的高级版/付费版用户,通过这些接口请求格式化数据并存储到数据库会更加简单。但是肯定还是有很多用户想要先用免费数据体验一下,今天,老Q就带大家看看怎么搞到免费的A股历史行情数据。
抓取A股股票列表
一、找到合适的网站
首先,我们的数据肯定是来自公开的互联网。因此我们先用搜索引擎搜一下“A股股票列表”。可以看到,很多网站都提供这个数据。
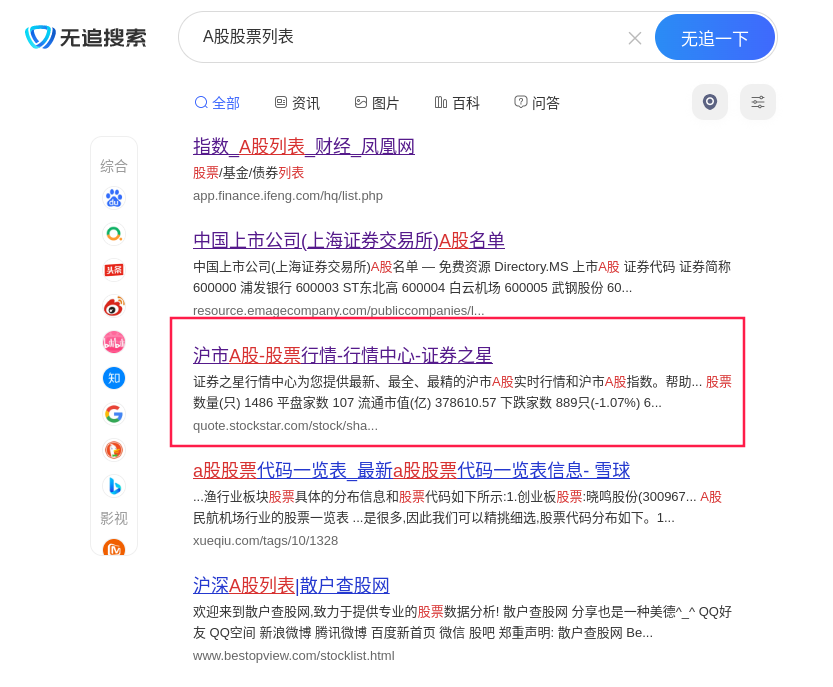
老Q随便翻了下:
- 第一个是凤凰网财经栏目的数据,页面过于简单,没什么挑战,我们先跳过去。
- 第二个是个野鸡网站,不确定是否靠谱,跳过。
- 第三个是证券之星,看起来数据比较全面,也适合我们演练爬虫。
二、分析网页
那咱们就看看这个证券之星的页面怎么抓取,我们在浏览器中点击进入这个链接:https://quote.stockstar.com/stock/sha.shtml。
右键并点击检查(或者按F12),进入开发者工具,选择网络选项卡并刷新页面。可以看到,网站提供了沪市A股、深市A股、B股等股票的列表数据,在这个页面中,除了股票代码和名称,还有着流通市值、总市值、流通股本和总股本数据。我们还看到,在右侧的网络选项卡中,有非常多的请求结果,我们想要抓取的数据到底在哪里呢?
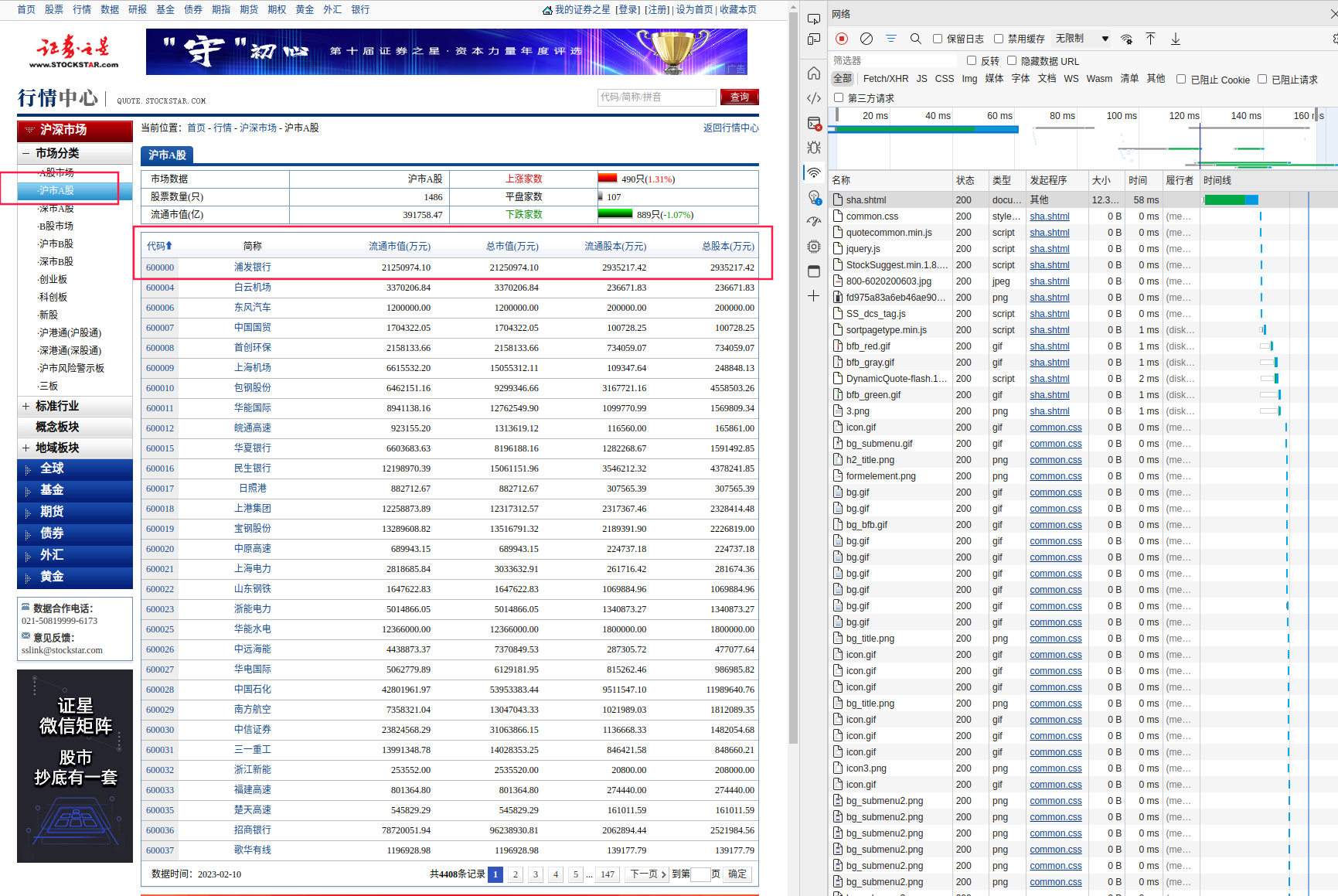
有两种方式来找到我们需要的数据:
- 第一种是关注响应结果为
document、script、xhr等类型的请求,我们需要的大部分数据都会藏在这些请求中; - 第二种就是直接搜索,比如我们看到页面中有浦发银行四个字,那么我们就在右侧网络选项卡中搜索这四个字,看看它到底藏在哪里。
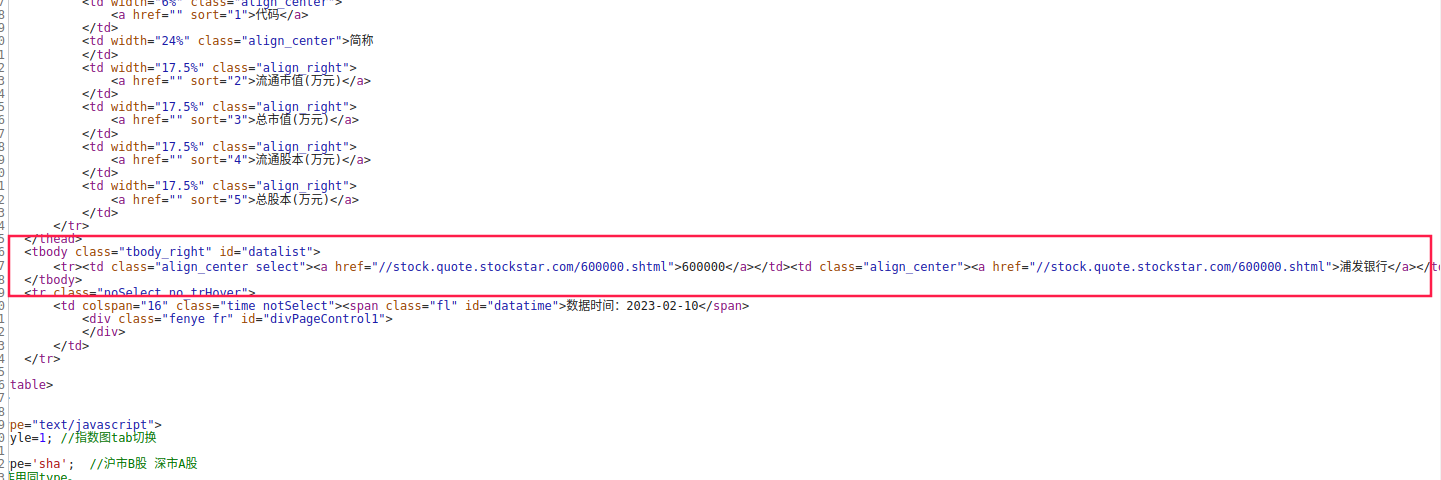
我们通过Ctrl + F快捷键进入搜索框,输入浦发银行,按Enter键进行搜索。可以看到,有两个请求结果中出现了这个关键词。
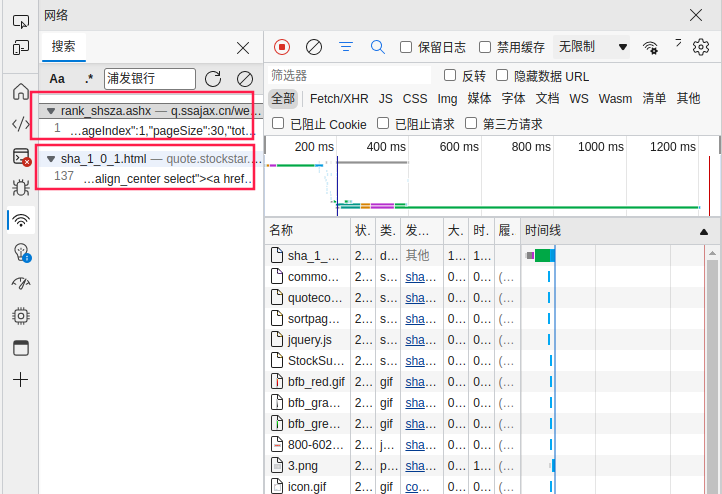
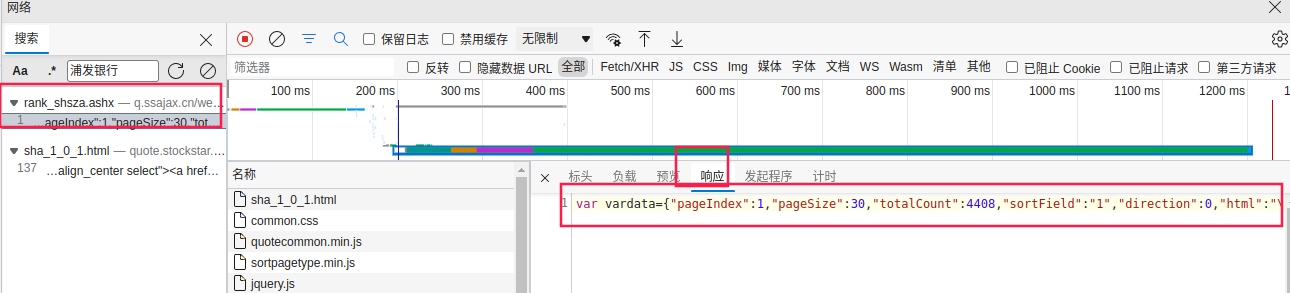
我们先双击第一个,点击右侧的“响应”选项卡,可以看到,数据以JSON的格式存储在vardata变量中,JSON格式的数据是非常好处理的,是很多接口响应格式的首选。这也节省了一些功夫,对于新手朋友来说门槛也更低了些。
我们再看看第二个。可以看到,数据出现在一个tbody元素中。这种是比较常见的形式,后边我们在讲解BeautifulSoup、pyquery、XPATH的时候会掌握如何解析此类情况。
三、构建网络请求
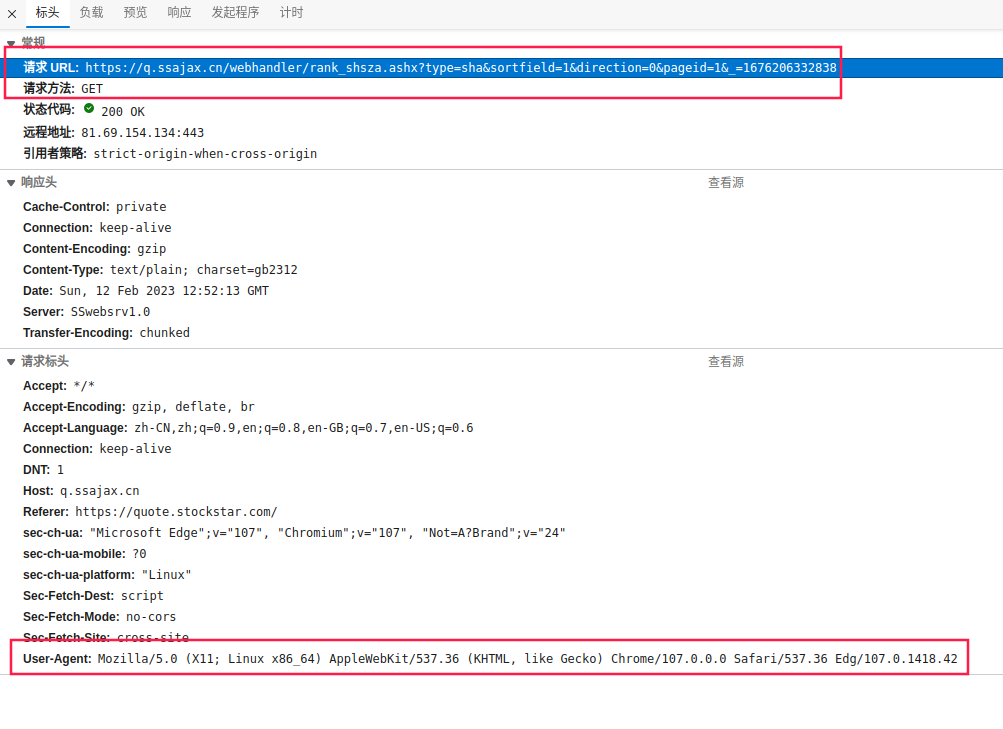
回到第一个搜索结果,点击标头选项卡,我们看下请求相关的信息,来确定如何用爬虫来模拟它。可以看到,请求的方法为GET,请求头中没有Cookie信息,响应体的编码为gb2312。请求的URL中,我们看到了type=sha、sortfield=1、direction=0、pageid=1和_=1676206332838这几个请求参数。
- 首先
type=sha是比较好理解的,应该就是只上证A股,同理,深证A股应该是type=sza。 sortfield=1是指排序字段,经过测试,取1时以股票代码排序,取2时以流通市值排序……其实这个不重要,反正我们全都要抓,不管是什么排序,都要抓到最后一页,我们就取默认值1就好。- 经过测试,
direction=0是指升序还是降序,当取0时,升序排列,取1时降序排列。这个也无所谓,我们取0就好。 pageid=1,很明显这个就是页码,看起来这个页面每页30条,我们需要一直往后翻页来获取全部数据。- 最后一个
_是随机数,如果这个参数是必须的,那我们还必须想办法破解下这个随机数的生成规则。
我们来去掉随机参数测试一下。
import requests
url = 'https://q.ssajax.cn/webhandler/rank_shsza.ashx?type=sha&sortfield=1&direction=0&pageid=1'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42'
}
req = requests.get(url, headers=headers)
req.encoding = 'gb2312'
print(req.text)
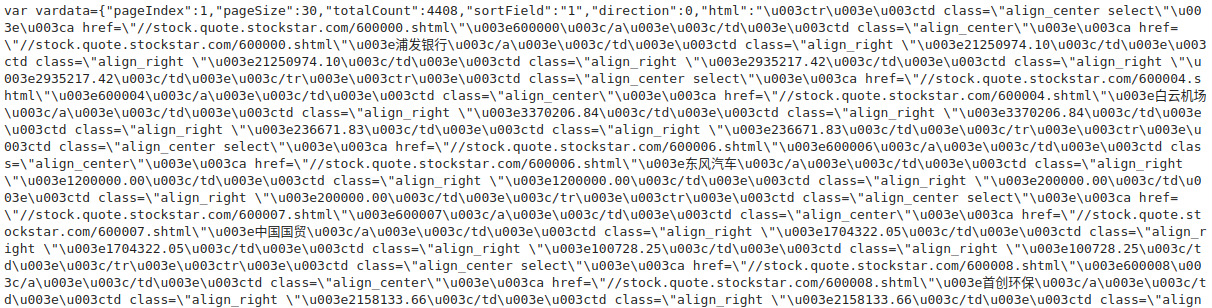
输出如下。看起来这个随机参数并没有用来反爬虫,运气还不错。
那么我们再看一下网站的爬虫协议。我们以请求的域名加上/robots.txt来访问协议文件,即https://q.ssajax.cn/robots.txt。可以看到,协议内容如下。看起来并没有封禁我们要使用的/webhandler/目录,也没有对抓取频次做什么限制。不过因为我们抓取的量很小,一秒钟一个页面也用不了几分钟,所以为了保险起见,我们可以把频率控制在一秒一页试一下,避免被封禁IP。
User-agent: *
Disallow:/ad/
Disallow:/css/
Disallow:/images/
Disallow:/inc/
Disallow:/js/
Disallow:/stockinfo/
Disallow:/stockinfo_capital/
Disallow:/stockinfo_corp/
Disallow:/stockinfo_dividend/
Disallow:/stockinfo_finance/
Disallow:/stockinfo_html/
Disallow:/stockinfo_info/
Disallow:/stockinfo_share/
Disallow:/stockinfo_test/
综合以上内容,我们的抓取代码如下:
import requests
import time
def get_one_response(url, headers):
"""抓取单一页面并返回响应结果
"""
req = requests.get(url, headers=headers)
req.encoding = 'gb2312'
return req.text
def get_all_response(page_cnt):
"""抓取全部页面
"""
# URL链接模板
url_init = 'https://q.ssajax.cn/webhandler/rank_shsza.ashx?type=sha&sortfield=1&direction=0&pageid={0}'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42'
}
# 全部待抓取URL链接
urls = [url_init.format(i) for i in range(1, page_cnt+1)]
# 实施抓取
res_list = []
for url in urls:
res_list.append(get_one_response(url, headers))
time.sleep(1)
return res_list
if __name__ == '__main__':
page_cnt = 147
res_list = get_all_response(page_cnt)
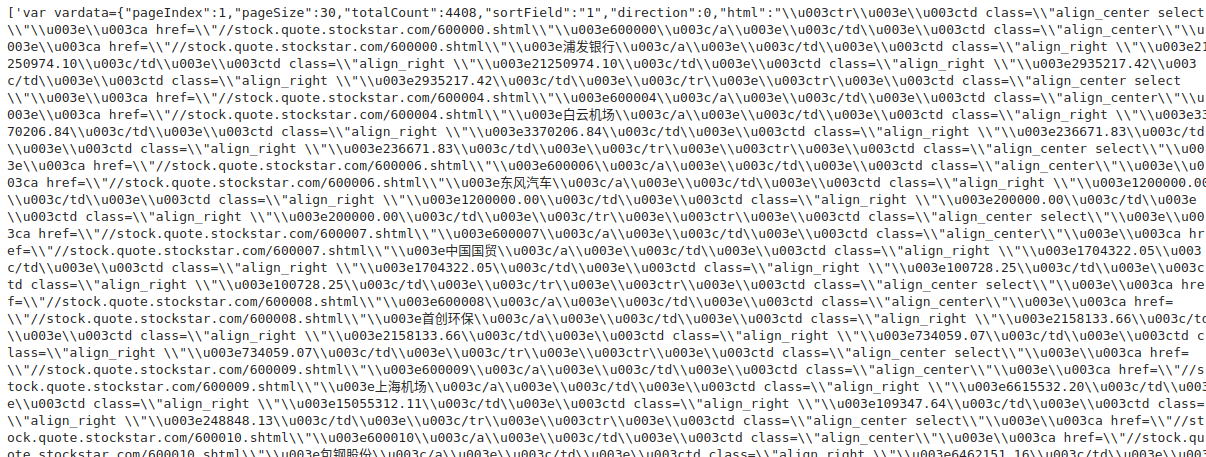
我们看下res_list的内容,它就是我们要抓取的全部原始文本。
看下列表长度:
print(len(res_list))
输出为147,符合我们的预期。
四、解析响应结果
得到了原始文本后,我们就要对其进行解析并转化为我们需要的格式。
我们注意到在每个页面的返回结果的开头多了var vardata=这几个字符,结尾多了;这个字符,这会导致我们直接以JSON格式解析该内容时会报错。所以我们要把这些没用的字符扔掉。扔掉以后,我们就可以直接用json库来对其进行加载了。
import json
tmp = res_list[0].strip('var vardata=').strip(';')
json.loads(tmp)
输出如下。可以看到我们需要的所有信息都在html下。
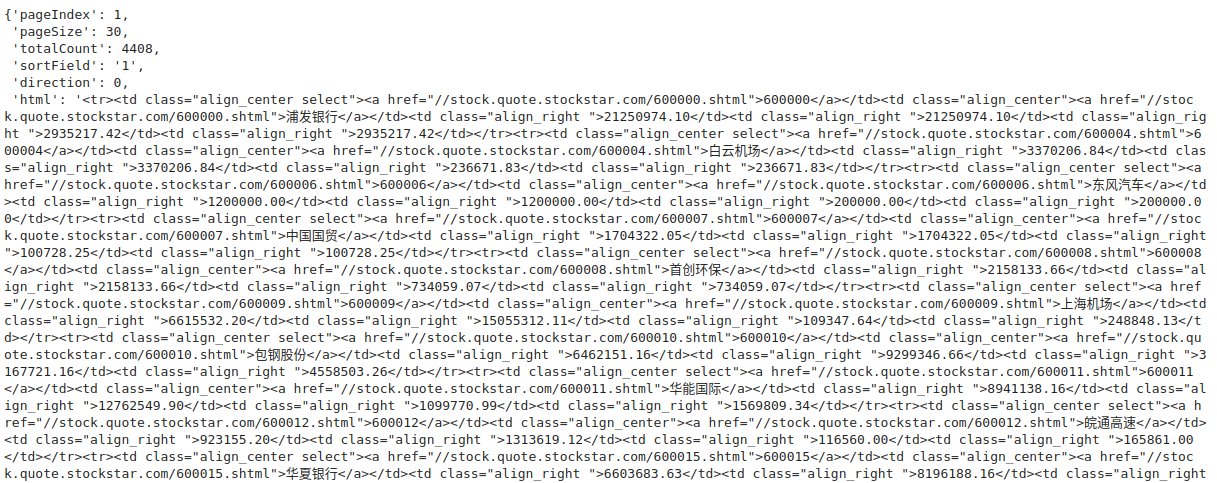
我们看到我们需要的信息都保存在一个个的网页元素中,我们应该怎么将它们提取出来呢?因为我们还没有学习BeautifulSoup等工具,所以这里我准备使用更加通用的正则表达式来带大家获得想要的结果。
我们使用正则表达式可以非常方便地处理重复的字符串模式,比如所有的股票代码,都以这样的形式重复出现:<td ...><a href ...>600000</a></td>。在股票代码之后,股票名称以类似的形式出现。那么我们可以用re库将这种固定的规律模式编写出来,并解析出所有我们想要的内容。
import json
import re
tmp = res_list[0].strip('var vardata=').strip(';')
html = json.loads(tmp)['html']
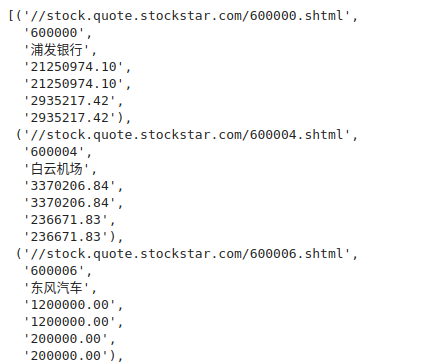
pat = re.compile('.*?<a href="(.*?)">(.*?)</a>.*?href.*?"'
'>(.*?)</a>' + '.*?">(.*?)</td>' * 4, re.S)
re.findall(pat, html)
可以看到,我们依次把股票的详情链接、股票代码、股票名称、流通市值、总市值、流通股本、总股本给解析了出来。
那么这里解析部分的完整代码如下:
import json
import re
from functools import reduce
import pandas as pd
def parse_one_page(pat, page_text):
page_text = page_text.strip('var vardata=').strip(';')
html = json.loads(page_text)['html']
data = re.findall(pat, html)
data = [['https:' + i[0]] + list(i[1:]) for i in data]
return data
def parse_all_page(page_texts):
pat = re.compile('.*?<a href="(.*?)">(.*?)</a>.*?href.*?"'
'>(.*?)</a>' + '.*?">(.*?)</td>' * 4, re.S)
data_lists = [parse_one_page(pat, page_text) for page_text in page_texts]
data_list = list(reduce(lambda x, y: x + y, data_lists))
columns = ['详情链接', '股票代码', '股票名称', '流通市值', '总市值', '流通股本', '总股本']
data = pd.DataFrame(data_list, columns=columns)
return data
运行下看看:
data = parse_all_page(res_list)
data
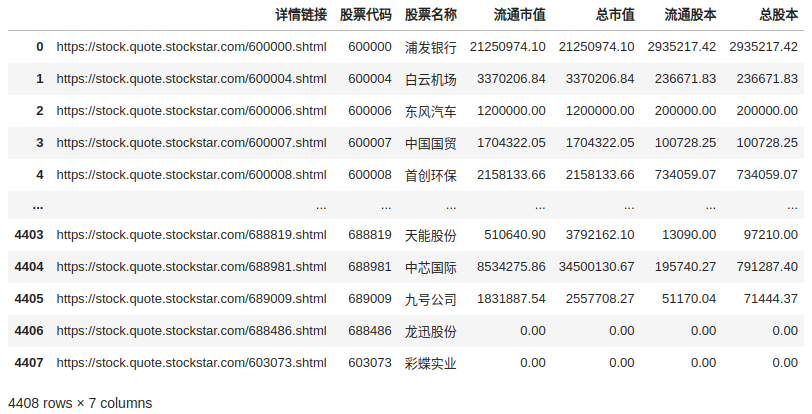
一共4408行,跟网页一致。但是仔细想想好像不太对,因为整个A股也就五千多支股票,仅仅上证目前肯定是没有真么多的。那我们来去下重好了:
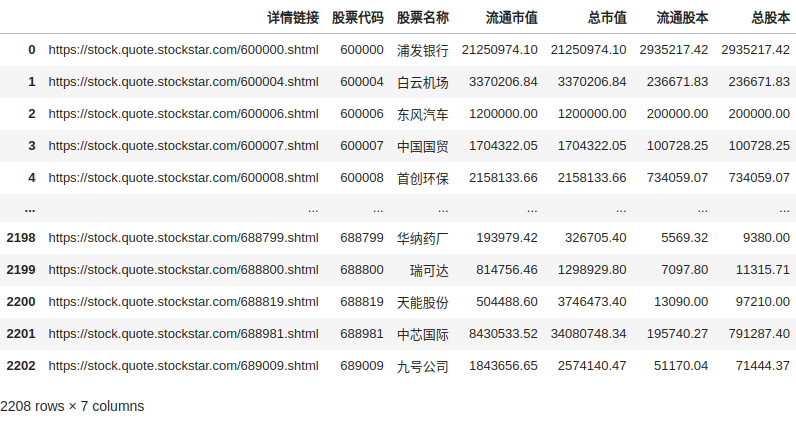
data = data.drop_duplicates(subset=['股票代码'], keep='first')
data.sort_values('股票代码', ascending=True)
2208行看起来就正常许多了。
五、保存数据
最简单的保存方式是保存在本地文件中,比如:
# 保存为CSV文件
data.to_csv('sha_list.csv', index=False)
# 保存为XLSX文件
data.to_excel('sha_list.xlsx', encoding='utf-8', index=False)
但是为了方便我们后续的使用,最好是保存到数据库中。
import pymysql
from sqlalchemy import create_engine
con_info = {
'host': 'your_mysql_ip_address',
'port': 3306,
'user': 'your_username',
'password': 'your_password',
'database': 'stock'
}
con = create_engine('mysql+pymysql://{user}:{password}@{host}:{port}/{database}'.format(**con_info))
data.to_sql('a_stock_list', con=con, index=False, if_exists='append')
可以看到,我们已经成功将数据写入了我们自己的数据库。这里的数据库是老Q在自己的NAS上搭建的MySQL服务,如果有朋友对于通过NAS搭建免费的私有云数据库感兴趣,也可以留言一下,老Q找时间可以写一个教程。
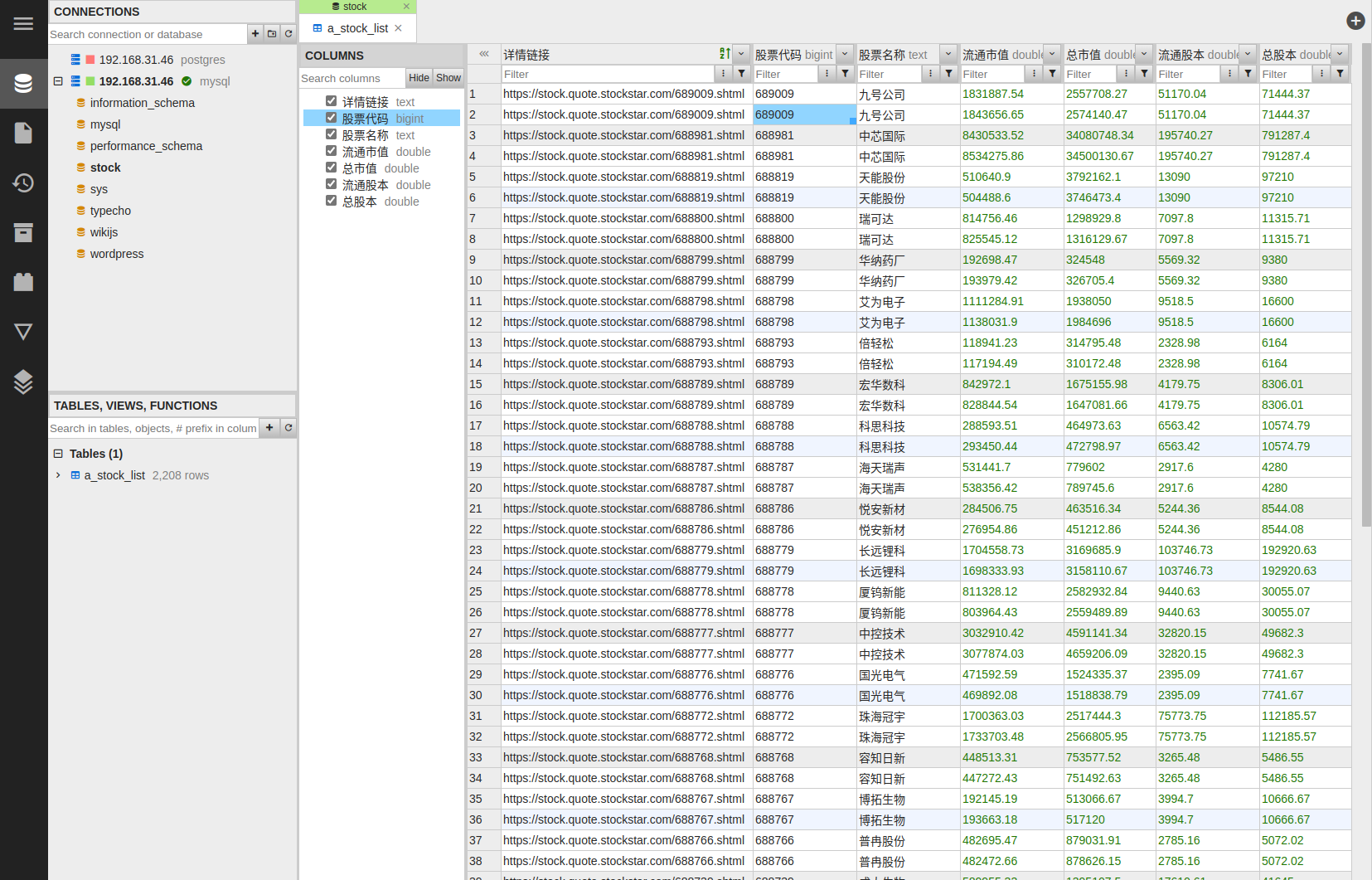
对于深证的股票列表的抓取也是类似的,这个就留给大家自己练手啦!



















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











