




 本文是Python爬虫入门教程,讲解了urllib库的基础用法,包括发起网络请求的方法、Request类的使用,以及身份验证、网络代理和Cookies的设置。通过实例展示了如何使用urllib进行HTTP请求,处理响应,并在遇到需要身份验证、代理或Cookies的情况时如何操作。
本文是Python爬虫入门教程,讲解了urllib库的基础用法,包括发起网络请求的方法、Request类的使用,以及身份验证、网络代理和Cookies的设置。通过实例展示了如何使用urllib进行HTTP请求,处理响应,并在遇到需要身份验证、代理或Cookies的情况时如何操作。
urllib库是Python内置的非常基础的HTTP请求库,在它的助力下,我们可以通过短短的几行代码就完成一次从网页请求到处理响应结果的过程。而且urllib库是Python的内置库,也就是说我们无需进行额外的安装。
urllib中包含四个基础模块:
request:它是urllib中最核心的模块,可以帮助我们向服务器发送HTTP请求。我们只需要将URL以及所需的参数传递给相应的方法,就可以实现这个过程。error:这是urllib中的异常处理模块,用来帮助我们捕获异常并做针对性的处理。parse:它是urllib中的一个工具模块, 可以帮助我们实现对URL的拆分、合并、解析等操作。robotparser:它主要用来帮助我们识别网站的robos.txt文件,以判断哪些页面可以爬取,哪些页面不可以爬取。实际上我们很少用到它。
在接下来的三个章节里,我们会重点学习一下这四个模块中的核心功能。
首先,我们先看一下最核心的request模块。request模块实现了发起网络请求所需的各种功能,包含了处理身份验证、使用代理和Cookies等一些能力,接下来,我们一个个地看。
一、urlopen方法
**前边提到,**request模块是urllib库的核心模块,它可以帮助我们实现一次网页请求。而在request模块中,最基础的又莫过于urlopen方法。
我们看一下urlopen方法的API:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None,
capath=None, cadefault=False, context=None)
url:它可以是一个网页链接(string格式),也可以是我们构建的一个urllib.request.Request对象。data:我们需要传递给服务器的额外数据,如果不需要的话,保持默认为None即可。我们在传递了该参数时,我们的请求方式就从GET变成了POST。timeout:超时时间,如果我们在设置的超时时间结束之前仍未得到服务器的响应,那么我们的请求就会报超时错误(一般为:urllib.error.URLError: <urlopen error timed out>)。cafile:CA证书的名称。cafile和capath只有在我们请求HTTPS链接时会被用到。capath:CA证书的路径。cadefault:该参数已废弃,可忽略。context:该参数必须是ssl.SSLContext类型,用来指定SSL设置。
我们以百度首页来测试一下它的基础用法。
import urllib
response = urllib.request.urlopen('http://www.baidu.com', timeout=2)
print(response.status, '\n' * 3)
print(response.headers, '\n' *3)
print(response.read())
**其中,**response.status的输出为200,它代表着请求成功并获得了服务器的响应。
response.headers的输出如下,它叫响应体,包含了服务器对请求的应答信息。
Bdpagetype: 1
Bdqid: 0xf35b71ca00003a8e
Content-Type: text/html; charset=utf-8
Date: Tue, 31 Jan 2023 15:06:41 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Server: BWS/1.1
Set-Cookie: BAIDUID=2658ADD22EC7B803B7F28520A6CFE0BA:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=2658ADD22EC7B803B7F28520A6CFE0BA; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1675177601; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=2658ADD22EC7B80325C31631715685AC:FG=1; max-age=31536000; expires=Wed, 31-Jan-24 15:06:41 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=36556_38112_38092_37906_37990_37796_37928_38086_26350_38098_38009_37881; path=/; domain=.baidu.com
Traceid: 1675177601237424871417535734686494505614
Vary: Accept-Encoding
X-Frame-Options: sameorigin
X-Ua-Compatible: IE=Edge,chrome=1
Connection: close
Transfer-Encoding: chunked
在响应体中,有些字段的含义是通用的:
Content-Type:指定返回的数据类型,比如上边的text/html代表着HTML文档,另外还有image/jpeg代表图片、application/x-javascript代表JavaScript脚本文件。Date:代表响应产生的时间。Server:服务器的信息,如名称、版本号等。Set-Cookie:设置Cookies。它是在告诉浏览器,下次访问时请带上这些信息并放在Cookies中,这样服务器就可以保持多次访问在同一个会话中,保证用户体验的连续性。
response.read()的输出就是我们关注的网页结果。不过乍一看,似乎我们不太认识这个输出。
这是因为,网页返回的内容包含中文,它是以UTF-8格式编码的,我们需要做一下解码。
print(content.decode('utf-8'))
看,这样中文就出来了。

二、Request类
urlopen可以帮我们实现常见的简单的请求,但是如果涉及到更复杂的请求,比如我们要在请求中携带Headers等信息,那我们就需要请出强大的Request类来进行辅助了。
我们来看一下Request的API。
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None,
unverifiable=False, method=None)
url:必传的有效网页链接地址,这里需要是一个string格式。data:bytes类型的数据。如果它是一个字典,那么我们需要使用urllib.parse.urlencode对其进行编码。headers:它是一个字典,包含了我们的请求头信息,如User-Agent、Cookies等。origin_req_host:请求方的host名称或者IP地址。unverifiable:当其为True时,表示这个请求是无法验证的,默认为False。method:用于指定请求所采用的方法,如GET、POST和PUT等。
下面我们以http://httpbin.org/post链接来体验一下Request的用法。http://httpbin.org网站是一个开源项目,用于帮助大家测试HTTP请求和响应的各种信息。
from urllib.request import Request, urlopen
from urllib.parse import urlencode
import json
# 网页链接
url = 'http://httpbin.org/post'
# 设置请求头
headers = {
'User-Agent': ('Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.61'),
'Host': 'httpbin.org'
}
# 设置要传输的内容,并编码为utf-8格式
data = {
'name': '老Q在折腾',
'homepage': 'https://www.oldq.top'
}
data = bytes(urlencode(data), encoding='utf-8')
# 创建请求对象
req = Request(url=url, data=data, headers=headers, method='POST')
# 为请求对象的请求头添加Referer
req.add_header('Referer', 'http://httpbin.org')
# 发起请求,获得响应
response = urlopen(req)
res = response.read().decode('utf-8')
print(json.loads(res))
输出如下:
{'args': {},
'data': '',
'files': {},
'form': {'homepage': 'https://www.oldq.top', 'name': '老Q在折腾'},
'headers': {'Accept-Encoding': 'identity',
'Content-Length': '78',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'httpbin.org',
'Referer': 'http://httpbin.org',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.61',
'X-Amzn-Trace-Id': 'Root=1-63d93673-1b9d19952c515ea97cb38f57'},
'json': None,
'origin': '114.249.124.19',
'url': 'http://httpbin.org/post'}
可以看到,我们传入的信息在form、headers等处体现了出来,说明我们成功地将这些信息传输到了服务器。
三、其他重要功能
1. 身份验证
有些网站在打开时会进行鉴权,我们必须输入用户名和密码才可以查看页面。这时,我们可以使用HTTPBasicAuthHandler类来实现。具体用法如下:
from ulrlib.request import HTTPBasicAuthHandler, build_opener, HTTPPasswordMgrWithDefaultRealm
# 设置用户名、密码、URL信息
username = 'your_username'
password = 'your_password'
url = 'http://your_url'
# 创建密码库
passwd = HTTPPasswordMgrWithDefaultRealm()
passwd.add_password(None, url, username, password)
# 创建一个鉴权处理对象,以刚才创建的密码信息作为参数传入
auth_handler = HTTPBasicAuthHandler(passwd)
# 使用刚才创建的Handler对象,创建自定义opener对象
opener = build_opener(auth_handler)
# 发送请求
response = opener.open(url)
# 读取响应体
res = response.read().decode('utf-8')
print(res)
2. 网络代理
在爬取网站内容时,为了避免被封禁IP,我们难免要经常使用代理,通过伪装我们的IP地址来躲避网站的反爬策略。
在urllib中使用代理的方法如下(注意将代理地址替换为你的实际代理服务地址)。
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://192.168.31.46:8011',
# 'https': 'http://192.168.31.46:8012'
})
opener = build_opener(proxy_handler)
response = opener.open('http://www.baidu.com')
res = response.read().decode('utf-8')
print(res)
成功返回结果。

3. 使用Cookies
我们经常需要通过Cookies来保持会话,使得我们多次访问网站获取的内容具有连续性。假如我们在浏览器上登陆了某个网站,并且想要在保持登陆状态的情况下对该网站的多个网页进行抓取,那么我们就可以尝试使用Cookies。
一般来说,我们可以从浏览器中将请求头中的Cookie信息复制并粘贴进headers中。如下图,我们可以右键点击网页,选择检查,进入开发者模式。然后在网络选项卡中找到我们要抓取的网页,单击并在标头中找到Cookie信息。
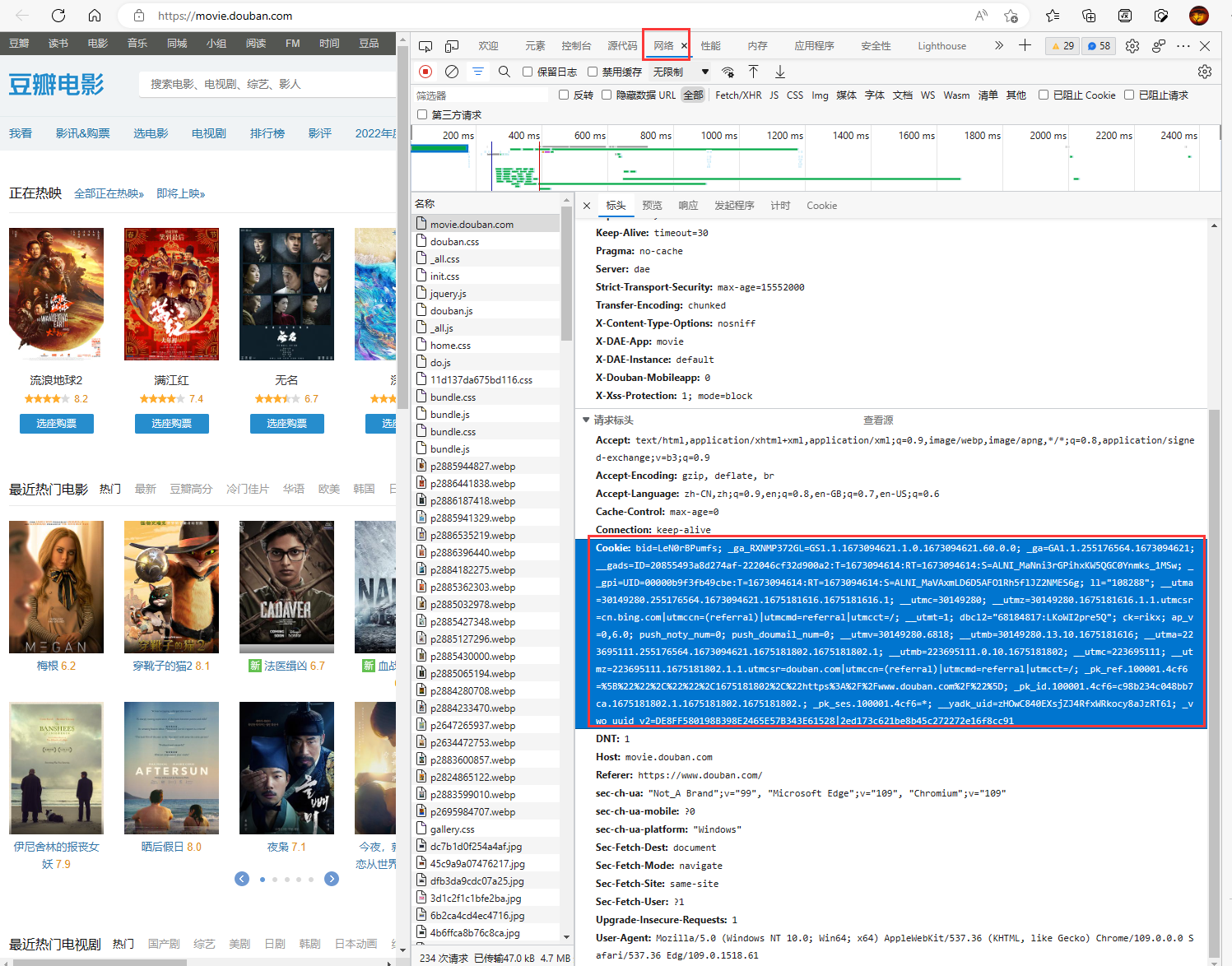
比如我们可以在使用时这样配置我们的headers:
from urllib.request import Request, urlopen
from urllib.parse import urlencode
url = 'http://website_host'
headers = {
'User-Agent': ('Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.61'),
'Cookies': 'your_cookie_copied_from_browser'
}
req = Request(url=url, headers=headers, method='GET')
response = urlopen(req)
res = response.read().decode('utf-8')
print(res)
当然,我们还可以通过在初次使用爬虫脚本登陆时,保存下来当时的Cookies信息到本地,然后在后续的爬取过程中加载该Cookies信息。
保存Cookies到本地:
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar("cookie.txt") #设定保存文件
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler) # 通过handler来构建opener
response = opener.open("http://www.baidu.com")
cookiejar.save(ignore_expires=True,ignore_discard=True)
使用本地Cookies:
import http.cookiejar
import urllib.request
cookie = http.cookiejar.MozillaCookieJar()
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf8'))
好了,关于request模块的介绍我们也不做更多展开了,后续如果我们在实战过程中用到了其他高级功能,那就在使用的过程中再做阐述。



















 2342
2342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











