




0. 前言:为什么要关注损失函数?
大家好,我是优快云的技术分享博主。今天我们来聊聊YOLO V1这个目标检测领域里程碑式算法中最精妙的部分——损失函数。
如果说YOLO V1的网格划分思想是它的“骨架”,网络结构是它的“肌肉”,那么损失函数就是它的“灵魂”和“引擎”。它决定了模型如何从错误中学习,如何平衡各种任务,最终实现精准的目标检测。
很多同学理解YOLO V1的思想很容易,但一到损失函数就头疼。本文将用最直观的方式,带你彻底掌握YOLO V1损失函数的每一个细节!🚀
1. 回顾:YOLO V1的预测输出是什么?
在深入损失函数之前,我们先快速回顾YOLO V1的预测输出。YOLO V1将图像划分为7×7的网格,每个网格预测:
-
2个边界框(Bounding Box):每个框预测5个值
(x, y, w, h, confidence) -
20个类别概率(针对PASCAL VOC数据集)
所以最终输出是一个7×7×30的张量。
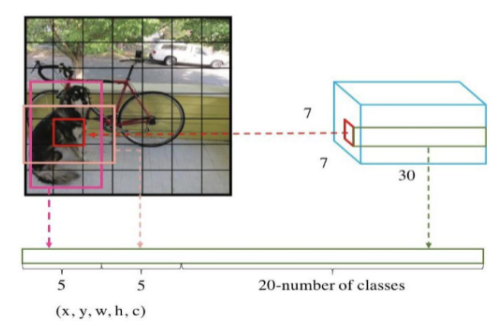
关键点:损失函数的目标就是衡量这个复杂的预测输出与真实标签之间的差距,并指导模型如何减小这个差距。
2. YOLO V1损失函数的五大组成部分 🧩
YOLO V1的损失函数不是一个简单的公式,而是由五个精心设计的部分组合而成。我们先通过一个表格总体把握,再逐一深入讲解。
|
组成部分 |
功能描述 |
权重系数 |
关键特点 |
|---|---|---|---|
|
边界框中心损失 |
预测框中心点(x,y)的准确性 |
λ_coord = 5 |
直接回归坐标偏移 |
|
边界框宽高损失 |
预测框宽度和高度的准确性 |
λ_coord = 5 |
使用平方根缓解尺度敏感 |
|
含物体置信度损失 |
有目标网格的置信度学习 |
1 |
学习预测框与真实框的IOU |
|
无物体置信度损失 |
无目标网格的置信度抑制 |
λ_noobj = 0.5 |
权重较小,避免负样本主导 |
|
分类损失 |
物体类别的识别准确性 |
1 |
仅在有目标网格计算 |
2.1 第一部分:边界框中心坐标损失(定位损失)
公式:
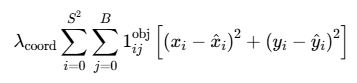
这部分负责确保预测框的中心点准确落在目标中心。
1、中心点误差项:(x_i - x̂i)² + (y_i - ŷi)²
-
(x_i, y_i):真实边界框的中心坐标
-
(x̂i, ŷi):预测边界框的中心坐标
-
使用平方误差:放大大误差的惩罚,让模型更关注误差较大的样本
2、1_ij^obj(指示函数) - 🔑这是关键!
-
取值:只能是 0 或 1
-
作用逻辑:
-
= 1:当且仅当第i个网格的第j个预测框负责检测某个物体
-
= 0:其他所有情况(网格无物体或不是主要预测框)
-
-
深入理解:YOLO的巧妙设计——每个物体只由一个“最合适”的预测框来负责,避免重复检测。
3、双重求和符号 ΣΣ
-
i = 0 → S²:遍历所有网格(S=7,共7×7=49个网格)
-
j = 0 → B:遍历每个网格的B个边界框(论文中B=2)
-
意义:对图片中的每一个边界框预测都进行误差计算
4、λ_coord(坐标权重系数)
-
值:论文中设置为 5
-
作用:给坐标损失一个较大的权重,强调定位准确性的重要性
-
为什么需要:因为如果框的位置都不对,识别出类别也没有意义。这相当于告诉模型:“宁可识别错,也要先把框放对位置!”
直观理解:这就像是教模型"瞄准",让预测框的中心点尽可能对准目标的中心点。🎯
2.2 第二部分:边界框宽高损失
这是YOLO V1损失函数中最巧妙的设计之一!公式如下:
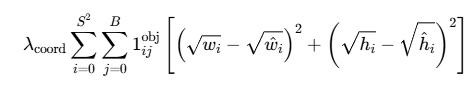
它专门惩罚预测框在宽度和高度上的误差。
这个公式的核心思想是:通过一个巧妙的数学变换(取平方根),让模型对不同大小的目标给予“公平”的关注,从而有效提升小物体的检测精度。
1、核心精髓:为什么要有平方根?(√w - √ŵ)²
这是整个公式的灵魂所在,旨在解决目标检测中的尺度敏感性问题。
举个例子🌰,让你秒懂:
假设需要检测两个物体:一辆大卡车(真实宽高 200x100)和一个小鼠标(真实宽高 20x10)。
情况一:都不使用平方根(直接比较宽高)
-
预测卡车为 210x110,误差是 (10² + 10²) = 200
-
预测鼠标为 30x20,误差是 (10² + 10²) = 200
-
模型从损失函数角度看,两个误差一样大,它会“认为”对卡车和鼠标的预测“一样好”或“一样坏”。但这明显不合理!因为鼠标的预测框已经偏离很远了。
情况二:使用平方根(YOLO V1的做法)
-
卡车:√200 ≈ 14.14, √210 ≈ 14.49 -> (14.49-14.14)² ≈ 0.12
√100=10, √110 ≈ 10.49 -> (10.49-10)² ≈ 0.24
总误差 ≈ 0.12 + 0.24 = 0.36
-
鼠标:√20 ≈ 4.47, √30 ≈ 5.48 -> (5.48-4.47)² ≈ 1.02
√10 ≈ 3.16, √20=4.47 -> (4.47-3.16)² ≈ 1.72
总误差 ≈ 1.02 + 1.72 = 2.74
看!奇迹发生了! 在使用了平方根之后,同样是10个像素的偏差,对于小鼠标的惩罚(2.74)远大于对大卡车的惩罚(0.36)。
2、双重求和 ΣΣ 与指示函数 1_ij^obj
这部分与中心点损失公式中的逻辑完全一致:
-
Σ_i=0→S²:遍历所有网格(7×7=49个)
-
Σ_j=0→B:遍历每个网格的B个预测框(B=2)
-
1_ij^obj:“责任指示器”,只有负责预测真实物体的那个“最好”的边界框才需要计算此项损失。
3、λ_coord(坐标权重系数)
-
值:设置为 5
-
作用:给所有定位损失(包括中心点损失和这里的宽高损失)一个较大的权重。
总结:YOLO V1 宽高损失公式通过引入平方根的目的:
-
平衡了损失尺度:让模型不再“歧视”小目标,对所有尺寸的目标给予相对公平的重视。
-
优化了梯度:使得小目标定位不准时,会产生更大的梯度,从而“推动”模型更努力地去学习如何精准定位小目标。
-
解决了实际问题:显著提升了模型对于小尺寸物体的检测能力。
2.3 第三和第四部分:置信度损失(有目标 vs 无目标)
置信度损失是YOLO V1面临的最大挑战,因为它要解决严重的样本不平衡问题:
-
一张图片中只有少数网格包含目标(正样本)
-
大部分网格不包含目标(负样本)
2.3.1 有目标网格的置信度损失
公式:
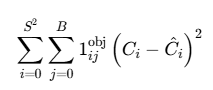
它专门用于计算那些“包含物体”的预测框的置信度误差。这个公式是模型学会“判断框内是否有物体”以及“框得有多准”的核心机制。
1、预测值与目标值的平方差:(C_i - Ĉ_i)²
-
C_i(预测值):这是模型为第i个预测框直接输出的置信度分数。它是一个介于0到1之间的数值,代表模型主观上认为“这个框里包含一个物体”的把握有多大。 -
Ĉ_i(目标值/真实值):这是我们希望模型去学习的“标准答案”。在YOLO v1中,Ĉ_i被定义为这个预测框与真实物体边界框的【交并比(IoU)】。IoU是一个客观的、衡量两个矩形框重叠程度的几何指标,值也在0到1之间。 -
(C_i - Ĉ_i)²:这是均方误差(MSE)。它衡量的是模型预测的置信度与真实的IoU值之间的差距。差距越大,惩罚(损失值)就越大,且因为是平方项,对大误差的惩罚会更加严厉。
2、指示函数:𝕀_ij^obj
-
这是一个指示函数(又称示性函数),其取值只能是 0 或 1。
-
𝕀_ij^obj = 1的条件:当且仅当以下两个条件同时满足:-
第
i个网格单元包含一个待检测物体的中心点。 -
第
j个预测边界框是当前网格的所有预测框中,与这个物体的真实边界框重叠度最高(即IoU最大)的那个,我们称其为“负责”预测该物体的框。
-
-
𝕀_ij^obj = 0的条件:不满足上述条件的所有情况(例如,网格里没有物体,或者这个框不负责预测该物体)。 -
作用:这是一个过滤器。它确保损失函数只对那些真正负责检测物体的、最合适的预测框进行惩罚,而忽略其他大量的、不包含物体的预测框,从而解决了目标检测中正负样本极不平衡的问题。
3、双重求和符号:∑_i=0^S² ∑_j=0^B
-
∑_i=0^S²:这表示对图像中所有的网格单元进行遍历和求和。S²代表网格的总数(在YOLO v1中,S=7,因此是7x7=49个网格)。 -
∑_j=0^B:这表示对单个网格单元内的所有边界框预测进行遍历和求和。B是每个网格预测的边界框数量(在YOLO v1中,B=2)。 -
组合意义:这两个求和符号 together 意味着公式将会对图像中的每一个预测边界框(共
7x7x2=98个)都进行一次计算。
2.3.2 无目标网格的置信度损失
公式:
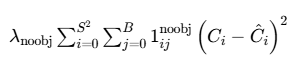
针对“不包含物体的预测框”的置信度损失。这个公式与上一个公式(负责物体的框)配对工作,共同解决目标检测中一个巨大的挑战:样本极度不平衡。
1、预测值与目标值的平方差:(C_i - Ĉ_i)²
-
C_i(预测值):同样是模型预测出的置信度,范围在0到1之间。 -
Ĉ_i(目标值/真实值):对于这些被标记为“不包含物体”的预测框,其目标值 Ĉ_i被强制设为0。 -
意义:因此,这一项简化为
(C_i - 0)² = (C_i)²。它的目的是惩罚那些在不包含物体的区域却预测出高置信度的行为。模型预测的置信度C_i越高,受到的惩罚就越大。
2、指示函数:𝕀_ij^noobj
-
这是与
𝕀_ij^obj相反的指示函数。 -
𝕀_ij^noobj = 1的条件:当且仅当第i个网格的的第j个预测框不负责检测任何真实物体。这包含了两种情况:-
该网格内根本没有真实物体。
-
该网格内有真实物体,但这个特定的预测框不是与真实物体IoU最大的那个(即它不是“主要负责人”)。
-
-
作用:这个函数是一个过滤器,专门筛选出那些应该被归类为“背景”或“负样本” 的预测框。
3、双重求和符号:∑_i=0^S² ∑_j=0^B
这部分与上一个公式完全相同:遍历图像中的每一个预测边界框(共 7x7x2=98 个)
4、权重系数:λ_noobj
-
值:在论文中设置为 0.5。
-
目的:这是整个公式的关键设计,用于进行损失加权。因为在一张图片中,不包含物体的网格(负样本)数量远远多于包含物体的网格(正样本)。如果不降低负样本损失的权重,负样本产生的梯度会在总梯度中占据绝对主导地位,从而“淹没”正样本的梯度,导致模型无法学习如何正确检测物体。
这个计算“边框内无对象”的置信度偏差公式,其意义可总结为:
-
功能:指导模型降低对背景区域的置信度预测,减少误检(False Positives)。
-
方法:强制让负样本的预测置信度向0靠近,并使用权重
λ_noobj = 0.5来平衡正负样本的数量差异。 -
结果:它与上一个公式配合,确保模型既能自信地检测出物体,又能明智地忽略背景,从而输出高质量的、可信的检测结果。
2.4 第五部分:分类损失
公式:
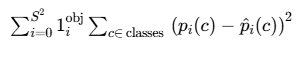
这个公式专门负责教导模型正确地识别出物体属于哪个类别。
1、平方误差项:(p_i(c) - p̂_i(c))²
-
p_i(c)(预测值):模型预测的、第i个网格中的物体属于类别c的条件概率。注意,YOLO v1为每个网格预测一组类别概率,与预测的边界框数量B无关。 -
p̂_i(c)(目标值/真实值):真实的类别标签,通常用one-hot编码表示。如果网格中的真实物体是类别c,则p̂_i(c) = 1,对于所有其他类别,p̂_i(c) = 0。 -
(预测值 - 真实值)²:这是标准的均方误差。它惩罚模型预测的概率分布与真实的one-hot标签之间的任何偏差。
2、内层求和:∑_c∈classes
-
含义:遍历所有可能的物体类别。在PASCAL VOC数据集上,有20个类别(如“人”、“车”、“猫”、“狗”等)。
-
目的:对单个网格的预测,计算它在所有类别上的预测误差。
3、指示函数:𝕀_i^obj
-
这是关键的“开关”:它是一个指示函数,值只能是0或1。
-
𝕀_i^obj = 1的条件:当且仅当第i个网格单元包含一个待检测物体的中心点。 -
作用:这个函数决定了只在包含物体的网格上计算分类损失。如果一个网格是背景(不包含任何物体),则
𝕀_i^obj = 0,整个公式在这一项的值就是0,该网格不对分类损失产生任何贡献。
4、外层求和:∑_i=0^S²
-
含义:遍历整个图像的所有网格单元。
S²是网格总数(7x7=49个)。 -
目的:确保对图像中的每一个位置都进行考量。
3. 完整损失函数公式 📊
将以上五部分组合起来,就得到了YOLO V1的完整损失函数:
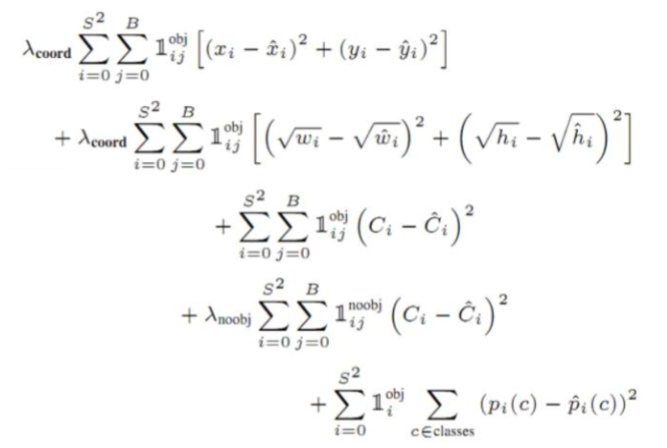
这个复杂的公式实际上体现了YOLO V1作者对目标检测任务的深刻理解:需要平衡不同任务的重要性,解决样本不平衡问题。
4. 损失函数的设计哲学 💡
4.1 多任务学习的平衡艺术
YOLO V1的损失函数本质上是多任务学习的典范:
-
定位任务(坐标回归)
-
检测任务(置信度预测)
-
分类任务(类别识别)
通过精心设计的权重系数(λ_coord = 5, λ_noobj = 0.5),实现了不同任务间的平衡。
4.2 解决样本不平衡的智慧
目标检测中最大的挑战就是正负样本极度不平衡。YOLO V1通过两种策略应对:
-
λ_noobj = 0.5:降低负样本的损失权重
-
只对IOU最大的负样本计算损失:进一步缓解样本不平衡
5. 损失函数的实现细节(伪代码)👨💻
def yolo_v1_loss(predictions, targets):
"""
predictions: 网络输出,形状为 [batch, 7, 7, 30]
targets: 真实标签,形状与predictions相同
"""
# 1. 提取各组成部分
pred_boxes = predictions[..., 0:10] # 2个边界框,每个5个参数
pred_classes = predictions[..., 10:30] # 20个类别概率
# 2. 计算中心坐标损失
xy_loss = 5 * mask_obj * MSE(pred_xy, true_xy)
# 3. 计算宽高损失(带平方根)
wh_loss = 5 * mask_obj * MSE(√pred_wh, √true_wh)
# 4. 计算有目标置信度损失
obj_confidence_loss = mask_obj * MSE(pred_conf, 1)
# 5. 计算无目标置信度损失
noobj_confidence_loss = 0.5 * mask_noobj * MSE(pred_conf, 0)
# 6. 计算分类损失
class_loss = mask_obj * MSE(pred_class, true_class)
# 7. 汇总损失
total_loss = xy_loss + wh_loss + obj_confidence_loss + noobj_confidence_loss + class_loss
return total_loss
6. 总结 🎯
YOLO V1的损失函数设计体现了简约而不简单的工程智慧:
✅ 主要优点:
-
端到端训练:单一损失函数指导整个模型的训练
-
任务平衡:通过权重系数有效平衡定位、置信度、分类任务
-
实际问题导向:平方根设计、正负样本权重都是针对实际问题的巧妙解决方案
⚠️ 局限性:
-
均方误差的局限性:对定位任务可能不是最优选择(后续版本改进)
-
网格划分的约束:每个网格只能预测固定数量的目标
-
小目标检测困难:虽然平方根缓解了问题,但未根本解决
🌟 对后续版本的影响:
YOLO V1的损失函数为后续版本奠定了坚实基础。YOLO V2/V3在此基础上引入了:
-
锚框(Anchor Boxes)
-
交并比(IOU)直接参与损失计算
-
多尺度预测等改进
7. 结束语
YOLO V1的损失函数就像一位严格的教练,同时指导模型学习"在哪里"(定位)、"有没有"(置信度)、"是什么"(分类)这三个核心技能。虽然看似复杂,但每个部分都有其明确的设计意图和实际价值。
希望这篇详细的解析能帮助你真正理解YOLO V1的"灵魂"。如果你有任何问题或想法,欢迎在评论区留言讨论!😊



















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











