




2025年十大开源大模型RAG框架
AI福手搓RAG框架,认真持续丰富完善文档中。本地部署RAG框架已超过 十个,有需要远程协作的粉丝,可以私信本人: AI福
检索增强生成(RAG)已成为增强大型语言模型能力的一项强大技术。
RAG框架结合了基于检索系统的优点与生成模型的优势,能够提供更准确、更具上下文感知能力以及更及时的响应。随着对复杂AI解决方案的需求增长,许多开源的RAG框架在GitHub上涌现,每个框架都提供了独特的功能和能力。
RAG框架的作用是什么?
检索增强生成(RAG)是一种人工智能框架,通过整合外部知识源来增强大型语言模型(LLM)的能力。
RAG通过从知识库中检索相关信息并利用这些信息来增强LLM的输入,从而使得模型能够生成更准确、更及时且更符合上下文的相关响应。
这种方法有助于克服诸如知识截止日期等限制,并减少LLM输出中幻觉的风险。
我为何不能直接使用LangChain?
虽然LangChain是构建LLM应用程序的强大工具,但它并不是RAG的直接替代品。相反,LangChain可以用于实现RAG系统。以下是您可能需要RAG而不仅仅是LangChain的原因:
- 1、 外部知识:RAG允许您将领域特定或最新的信息整合到LLM的训练数据中,这些信息可能不在LLM的训练数据中。
- 2、 提高准确性:通过基于检索到的信息生成响应,RAG可以显著减少错误和幻觉。
- 3、 定制化:RAG使您能够根据特定的数据集或知识库调整响应,这对于许多商业应用至关重要。
- 4、 透明度:RAG使追溯生成响应所用信息的来源变得更加容易,从而提高了审计性。
简而言之,虽然LangChain提供了构建LLM应用程序所需的工具和抽象,但RAG是一种特定的技术,可以通过LangChain实现,以提高LLM输出的质量和可靠性。
GitHub上最佳的10种RAG框架,现在就可以使用
在这篇文章中,我们将探讨目前在GitHub上可用的10种顶级RAG框架。这些框架代表了RAG技术的最前沿,对于希望实施或改进其AI驱动应用程序的开发人员、研究人员和组织来说,非常值得研究。
Open-webui
保姆教程:Ollama+OpenWebUI+llama3本地部署
GitHub Stars: 69.7k stars

https://github.com/open-webui/open-webui
Llamaindex
保姆教程:Llamaindex+Ollama 构建RAG私有化知识库
https://docs.llamaindex.ai/en/stable/index.html官网

LlamaIndex是一个数据框架,它主要用于连接大型语言模型(LLMs)与外部数据源,例如API、PDF文档、SQL数据库等。这个框架的设计目的是为了增强LLM的能力,使其能够理解和生成更准确、更有上下文关联的文本,尤其是在涉及私人数据或特定领域知识的情况下。
LlamaIndex通过创建索引结构来组织和访问数据,这样可以更高效地检索相关信息并将其提供给LLM。这些索引可以是列表索引、向量索引、树索引或关键词索引等,具体取决于数据类型和需求。LlamaIndex还允许用户定制输入提示(prompt),以优化与LLM的交互方式,从而得到更加精确的响应。
此外,LlamaIndex支持多种编程语言,包括Python和TypeScript,这使得开发者可以根据自己的项目需求选择合适的语言来构建基于LLM的应用程序。由于LLM通常是在大量公共数据上训练的,因此LlamaIndex的介入可以帮助引入私有数据或特定领域的信息,从而使生成的内容更具针对性和实用性。
总之,LlamaIndex是一种工具,它帮助开发者构建能够结合外部数据的智能应用程序,这些应用程序可以更好地理解和生成与特定情境相关的内容。
MaxKB
保姆教程:MaxKb+Ollama 构建RAG私有化知识库

MaxKB 是一款基于 LLM 大语言模型的知识库问答系统。MaxKB = Max Knowledge Base,旨在成为企业的最强大脑。
开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化,智能问答交互体验好;
无缝嵌入:支持零编码快速嵌入到第三方业务系统;
多模型支持:支持对接主流的大模型,包括 Ollama 本地私有大模型(如 Llama 2、Llama 3、qwen)、通义千问、OpenAI、Azure OpenAI、Kimi、智谱 AI、讯飞星火和百度千帆大模型等。
Haystack by deepset-ai
GitHub Stars: 19k stars

Haystack 是一个强大且灵活的框架,用于构建端到端的问答和搜索系统。它提供了一种模块化架构,允许开发人员轻松地为包括文档检索、问答和摘要在内的各种 NLP 任务创建管道。Haystack 的主要特性包括:
-
支持多种文档存储(如 Elasticsearch、FAISS、SQL 等)
-
与流行语言模型(如 BERT、RoBERTa、DPR 等)集成
-
可扩展架构,用于处理大量文档
-
构建自定义 NLP 管道的易于使用的 API
由于 Haystack 的多功能性和详尽的文档,无论是初学者还是经验丰富的开发人员,如果想要实现基于 Agent 的检索(RAG)系统,它都是一个极佳的选择。
git地址:https://github.com/deepset-ai/haystack
RAGFlow by infiniflow
GitHub Stars: 11.6k
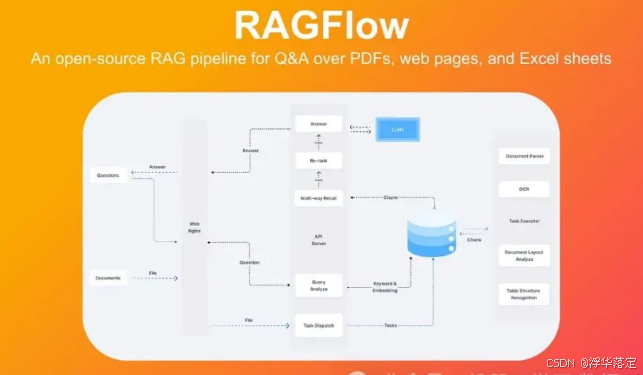
RAGFlow 是最近加入到 RAG 框架领域的一个新成员,但它由于专注于简洁性和效率,迅速获得了关注。该框架旨在通过提供一套预构建的组件和工作流,简化基于 RAG 应用程序的开发流程。RAGFlow 的显著特性包括:
-
直观的工作流设计界面
-
针对常见用例的预配置 RAG 管道
-
与流行的向量数据库集成
-
支持自定义嵌入模型
RAGFlow 用户友好的方法使其成为希望快速原型化和部署 RAG 应用程序而无需深入研究底层复杂性的开发人员的有吸引力的选择。
git地址:https://github.com/infiniflow/ragflow
txtai by neuml
GitHub Stars: 7.5k

txtai 是一个多功能的AI驱动的数据平台,超越了传统的RAG框架。它提供了一系列构建语义搜索、语言模型工作流以及文档处理流水线的全面工具。txtai 的关键能力包括:
-
用于高效相似性搜索的嵌入式数据库
-
集成语言模型和其他AI服务的API
-
可扩展架构,支持自定义工作流
-
多语言和多种数据类型的支持
txtai 的一站式方案使其成为希望在一个框架内实施各种AI功能的组织的绝佳选择。
git地址:https://github.com/neuml/txtai
STORM by stanford-oval
GitHub Stars: 5k Stars

STORM(斯坦福开源RAG模型)是由斯坦福大学开发的一个面向研究的RAG框架。尽管与一些其他框架相比,它的GitHub星数可能较少,但其深厚的学术背景和对前沿技术的专注,使其成为对RAG技术最新进展感兴趣的科研人员和开发者的宝贵资源。STORM值得关注的方面包括:
-
实现新颖的RAG算法和技术
-
专注于提高检索机制的准确性和效率
-
与最先进的语言模型集成
-
详尽的文档和研究论文
对于那些希望探索RAG技术最前沿的人来说,STORM提供了一个坚实的基础,并且得到了学术严谨性的支持。
git地址:https://github.com/stanford-oval/storm
LLM-App by pathwaycom
GitHub Stars: 3.4K

LLM-App 是一组用于构建动态 RAG 应用程序的模板和工具集。它通过专注于实时数据同步和容器化部署而脱颖而出。LLM-App 的关键特性包括:
-
可快速部署的预构建 Docker 容器
-
支持动态数据源和实时更新
-
与流行的 LLM 和向量数据库集成
-
适用于各种 RAG 场景的可定制模板
LLM-App 对操作方面和实时能力的重视使其成为希望部署生产就绪 RAG 系统的组织的有吸引力的选择。
git地址:https://github.com/pathwaycom/llm-app
Cognita by truefoundry
GitHub Stars: 3k stars
Cognita 是 RAG 框架领域的一个新进入者,专注于提供一个统一的平台来构建和部署 AI 应用程序。虽然它的星标数量不如一些其他框架多,但是其全面的方法和对 MLOps 原则的强调使其值得一试。Cognita 的一些值得注意的特点包括:
-
全流程的 RAG 应用开发平台
-
与流行机器学习框架和工具的集成
-
内置的监控和可观测性功能
-
对模型版本管理和实验跟踪的支持
Cognita 对 AI 应用开发的整体性方法,使其成为希望简化整个机器学习生命周期的组织的有力选择。
git地址:https://github.com/truefoundry/cognita
R2R by SciPhi-AI

GitHub Stars: 2.5k stars
R2R(检索到检索)是一种专注于通过迭代细化来改进检索过程的专门的RAG框架。尽管它可能拥有的星标较少,但其在检索方法上的创新使其成为值得关注的框架。R2R的关键特点包括:
-
实现新型检索算法
-
支持多步骤检索流程
-
与各种嵌入模型和向量存储集成
-
用于分析和可视化检索性能的工具
对于希望突破检索技术界限的开发者和研究人员来说,R2R提供了一套独特而强大的工具。
Neurite by satellitecomponent
GitHub Stars: 909 stars

Neurite 是一个新兴的RAG框架,旨在简化构建AI驱动应用程序的过程。尽管其用户群体相对于其他一些框架较小,但它专注于开发人员体验和快速原型设计,使其值得探索。Neurite 的一些显著特点包括:
-
构建RAG管道的直观API
-
支持多种数据源和嵌入模型
-
内置缓存和优化机制
-
可扩展架构以支持自定义组件
Neurite 对简洁性和灵活性的强调使其成为希望快速在其应用程序中实现RAG功能的开发者的有吸引力的选择。
git地址:https://github.com/satellitecomponent/Neurite
FlashRAG by RUC-NLPIR
GitHub Stars: 905 Stars
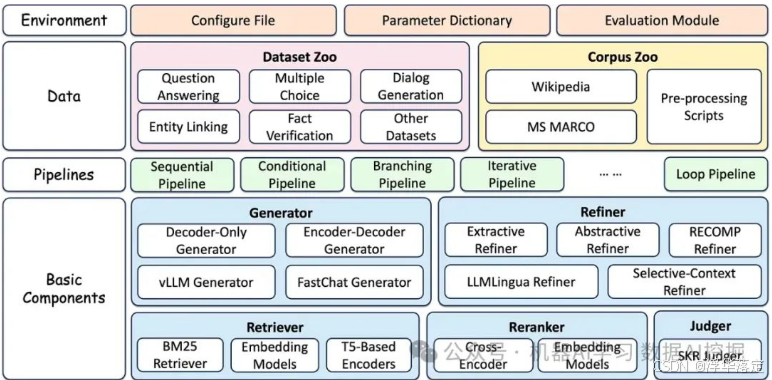
FlashRAG 是由中国人民大学自然语言处理与信息检索实验室开发的一款轻量级且高效的检索增强型生成(RAG)框架。尽管它的星标数量可能较少,但其对性能和效率的关注使其成为一个值得关注的竞争者。FlashRAG 的关键方面包括:
优化的检索算法以提高速度
支持分布式处理和扩展
与流行的语言模型和向量存储集成
用于基准测试和性能分析的工具对于需要高速度和高效性的应用,FlashRAG 提供了一套专门的工具和优化措施。
git地址:https://github.com/RUC-NLPIR/FlashRAG
Canopy by pinecone-io
GitHub Stars: 923
Canopy是由Pinecone公司开发的一种RAG框架,该公司以其向量数据库技术而闻名。Canopy利用了Pinecone在高效向量搜索方面的专业知识,提供了一种强大且可扩展的RAG解决方案。Canopy的显著特性包括:
与Pinecone向量数据库的紧密集成
支持流处理和实时更新
先进的查询处理和重新排序功能管理知识库和版本控制的工具Canopy专注于可扩展性和与Pinecone生态系统的集成,使得它成为那些已经在使用或考虑使用Pinecone进行向量搜索需求的组织的理想选择。
git地址:https://github.com/pinecone-io/canopy
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
AnythingLLM
保姆教程: AnythingLLM+Ollama,基于RAG方案构专属私有知识库
官网https://anythingllm.com/
AnythingLLM是一个AI聊天系统,它允许用户构建自己的私人ChatGPT。与依赖云服务的AI工具不同,AnythingLLM支持本地开源和商用闭源的大语言模型(LLM),用户可以根据自己的需求和预算选择合适的模型。
AnythingLLM的核心功能
文档智能聊天:只需导入文档,AnythingLLM就能自动进行上下文分析和内容整理,用户可以通过对话的方式快速提取关键信息。
自定义AI代理:用户可以为每个工作区创建不同的AI代理,实现高度的定制化。例如,可以创建一个专门处理Python代码的AI代理,另一个则专门用于处理PDF文档。
多模式支持:无论是免费的开源模型还是付费的商用模型,AnythingLLM都能兼容,为用户提供极大的灵活性。
广泛的文档支持:从PDF、TXT到Word、Excel,几乎所有常见的文档格式都支持。
嵌入式聊天小部件:用户可以将AnythingLLM嵌入到自己的网站中,为网站用户提供自动化的智能客服服务。
团队协作支持:通过Docker容器,多个用户可以同时使用AnythingLLM,非常适合团队开发或公司内部使用。
丰富的API接口:开发者可以轻松集成AnythingLLM到现有的应用中,实现更多定制化功能。



















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











