 Llama3模型本地部署与使用指南
Llama3模型本地部署与使用指南





llama3本地部署
引言
llama3在4月19日刚刚发布,官方的对比结果中在开源模型中堪称世界第一,整好周六日有时间,在魔搭社区上测试一下
什么是OpenWebui
Open WebUI 是一个仿照 ChatGPT 界面,为本地大语言模型提供图形化界面的开源项目,可以非常方便的调试、调用本地模型。你能用它连接你在本地的大语言模型(包括 Ollama 和 OpenAI 兼容的 API),也支持远程服务器。Docker 部署简单,功能非常丰富,包括代码高亮、数学公式、网页浏览、预设提示词、本地 RAG 集成、对话标记、下载模型、聊天记录、语音支持等。
Github:https://github.com/open-webui/open-webui
官方文档:https://docs.openwebui.com/getting-started/
1、启动环境
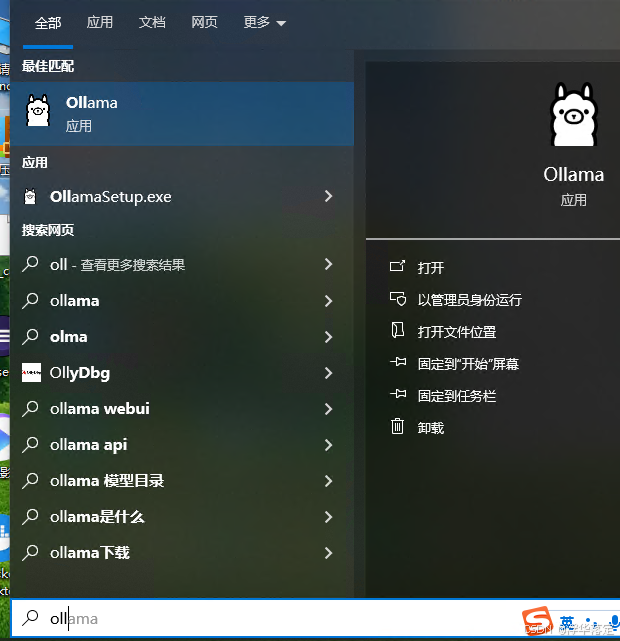
1.1 启动ollama
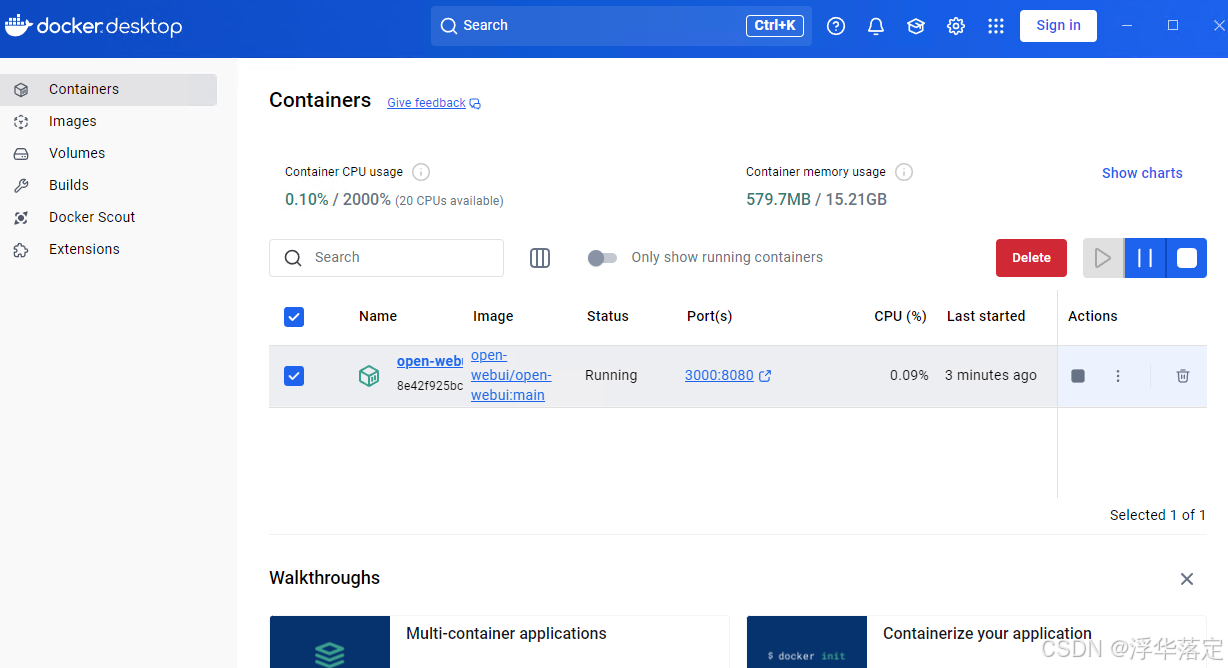
1.2 docker容器中启动open-webui/
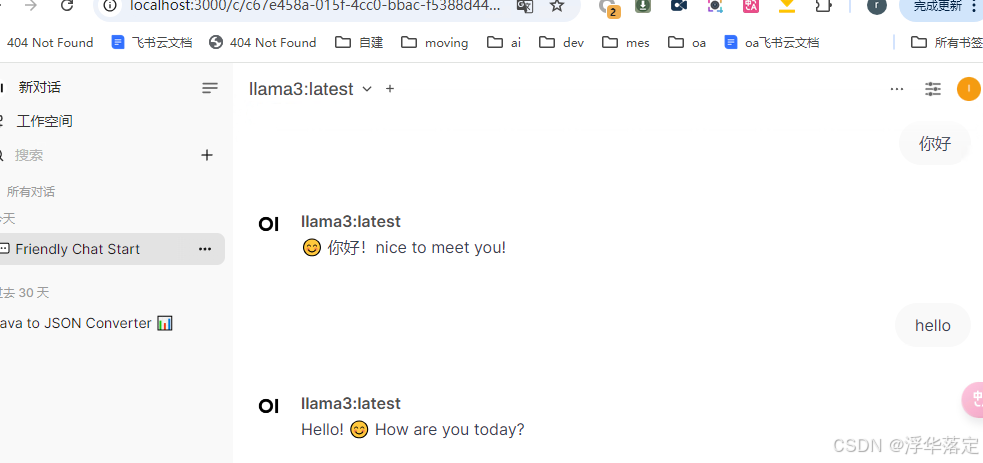
1.3 浏览器访问http://localhost:3000/
2 安装Ollama
2.1 下载Ollama
登录Ollama官网下载Ollama安装包
GitHub:https://github.com/ollama/ollama?tab=readme-ov-file

下载后双击安装

2.2 安装Ollama
Windows下安装Ollama很简单,双击运行安装文件即可,此处不赘述。
打开终端,输入ollama,出现下图所示代表安装成功

注意:
windows 的安装默认不支持修改程序安装目录,
默认安装后的目录:C:\Users\username\AppData\Local\Programs\Ollama
默认安装的模型目录:C:\Users\username\ .ollama
默认的配置文件目录:C:\Users\username\AppData\Local\Ollama
2.3 配置Ollama的模型路径
由于Ollama的模型默认会在C盘用户文件夹下的.ollama/models文件夹中,可以配置环境变量OLLAMA_MODELS,设置为指定的路径:


2.4 下载llama3模型
llama3目前主要有8B和70B两个模型,分别代表80亿和700亿个训练参数。

8B模型一般16GB内存就可以跑的很流畅,70B模型则至少需要64GB内存,有CPU就可以跑,当然有GPU更好。
这里我安装的是8B的模型。
打开终端,输入命令:ollama run llama3默认安装8B模型,也可以使用ollama run llama3:8b来指定相应的模型,安装成功会有如下提示:

提问题,发现该模型给了不太靠谱的回复。

当然也可以写代码

至此,llama3本地部署已完成。
注意1:
在没有互联网的环境下部署,可以将下载好的Ollama安装包复制到此环境安装,然后将下载好的模型复制到相应路径就可以在无互联网的环境下使用。
注意2:
由于llama3对中文的支持并不是很好,需要中文的可以使用GitHub上开源的这个llama3中文微调模型https://github.com/LlamaFamily/Llama-Chinese
3 Ollama+OpenWebUI
前面部署的llama3是在命令行里面进行交互,体验感并不好,安装OpenWebUI可以使用web界面进行交互。这里我使用docker的方式部署OpenWebUI。
3.1 安装Docker
3.1.1 下载Docker
Docker下载

安装启动, 提示如下, 需要启动微软Hyper-V选项

3.1.2 启动微软Hyper-V
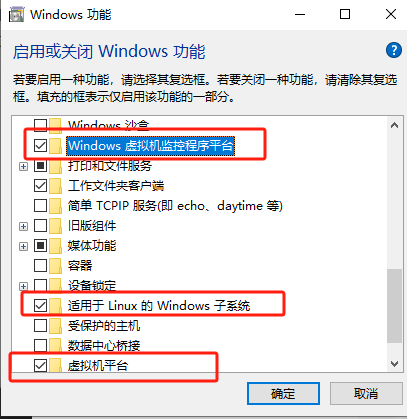
打开“控制面板->程序->启用或关闭Windows功能”


勾选Hyper-V选项

 安装 WSL
安装 WSL
官方文档:https://learn.microsoft.com/en-us/windows/wsl/install
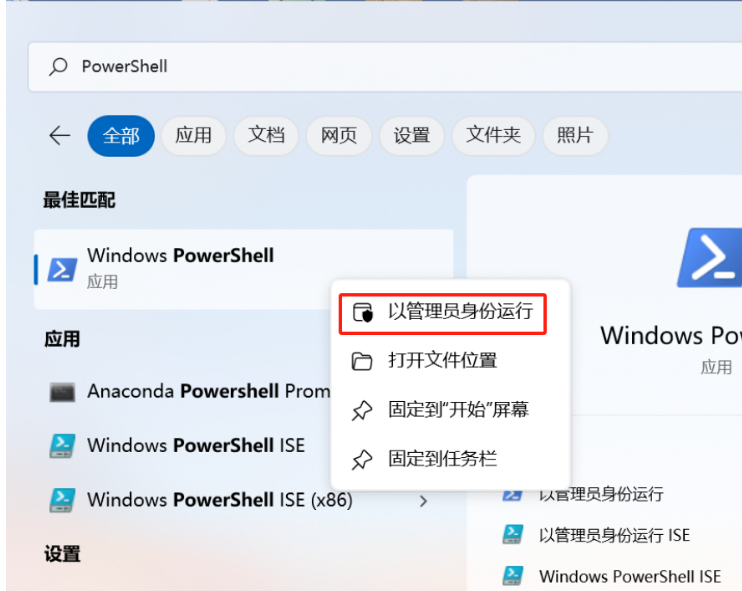
管理员运行PowerShell
设置 WSL默认版本
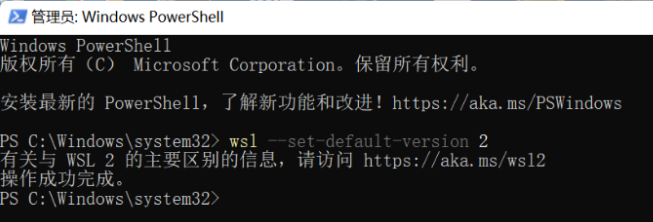
输入 wsl --set-default-version 2 ,将 Windows 系统中适用于 Linux 的 Windows 子系统(WSL)的默认版本设置为 2
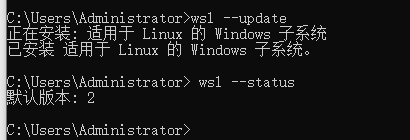
检查wsl状态 wsl --status. 若遇到如下问题, 更新
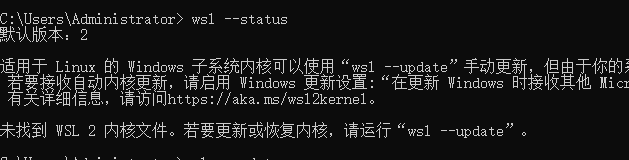
解决上图问题, 执行 wsl --update。 再次检查后正常
重启电脑后安装成功
Windows工具中可以看到Hyper-V已安装成功。

注意:
若没有Hyper-V选项,可以使用如下命令安装:
pushd "%~dp0"
dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hv.txt
for /f %%i in ('findstr /i . hv.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"
del hv.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V -All /LimitAccess /ALL
Pause
将上述命令复制到Hyper-V.bat批处理文件中,然后以管理员身份运行。

3.1.3 安装Docker
打开之后是这个样子,一般不需要使用,用命令行操作即可。


3.1.4 切换国内镜像源

{
"registry-mirrors": [
"https://82m9ar63.mirror.aliyuncs.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
],
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"features": {
"buildkit": true
}
}
3.1.5 恢复出厂设置
Docker中国区官方镜像地址
网易地址
中国科技大学地址
阿里巴巴
3.2 安装OpenWebUI

# ollama在同一台服务器
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# ollama在不同服务器
docker run -d -p 8080:8080 -e OLLAMA_BASE_URL=http://192.168.0.18 -v open-webui:/app/backend/data -v /mnt/docker-file/open-webui:/app/backend/open_webui --name open-webui --restart always ghcr.io/open-webui/open-webui:main
尝试多次无果, 此种情况弃用docker

docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# 对于Nvidia GPU支持,请将--gpus all添加到docker run命令中
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
浏览器输入http://localhost:3000/

注意:
注册时邮箱可以随便填写,例如:admin@111.com
3.3 web访问llama3
注册登录后可以看到直接可以选择之前部署好的llama3:8b模型,通过对话测试下它的能力。

写代码:

注意:
后台一定要运行着llama3,ollama run llama3:8b
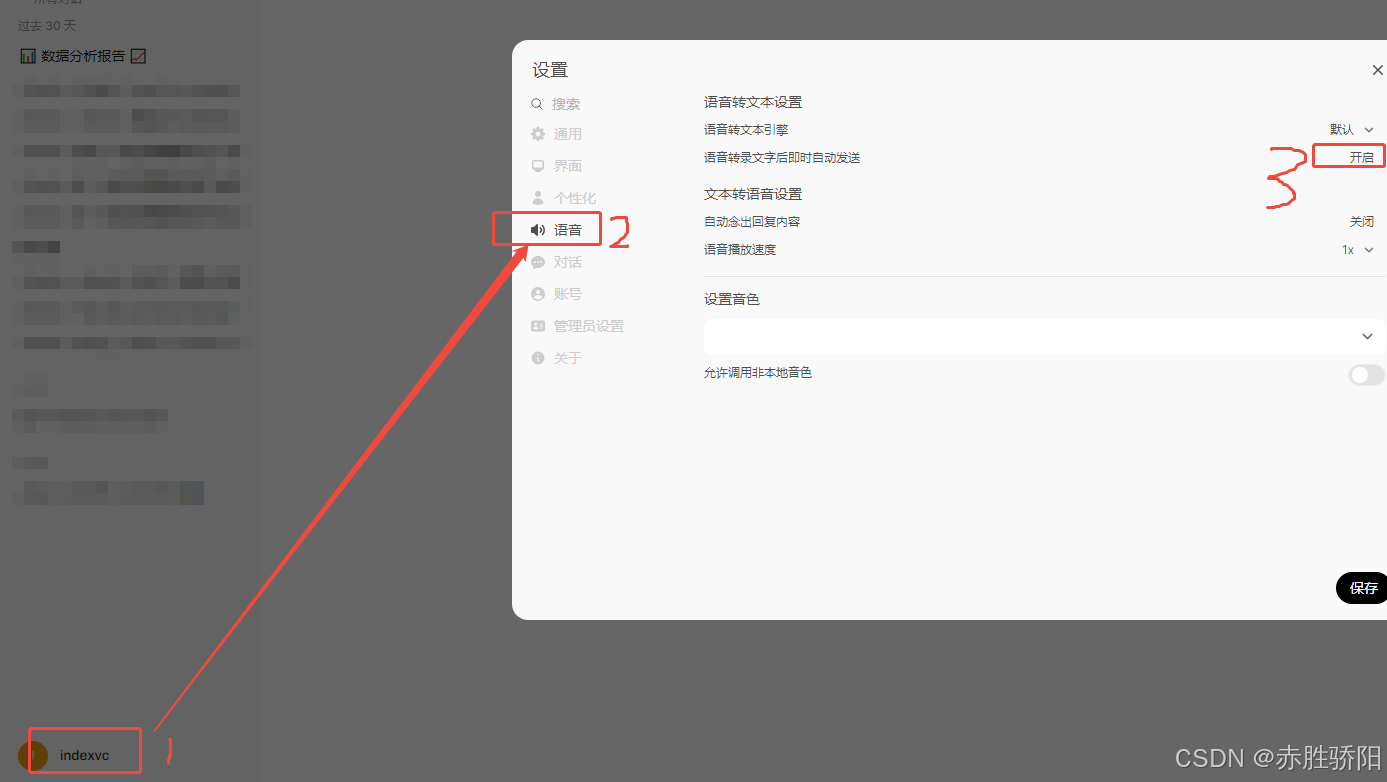
3.3.1 配置语音转文本
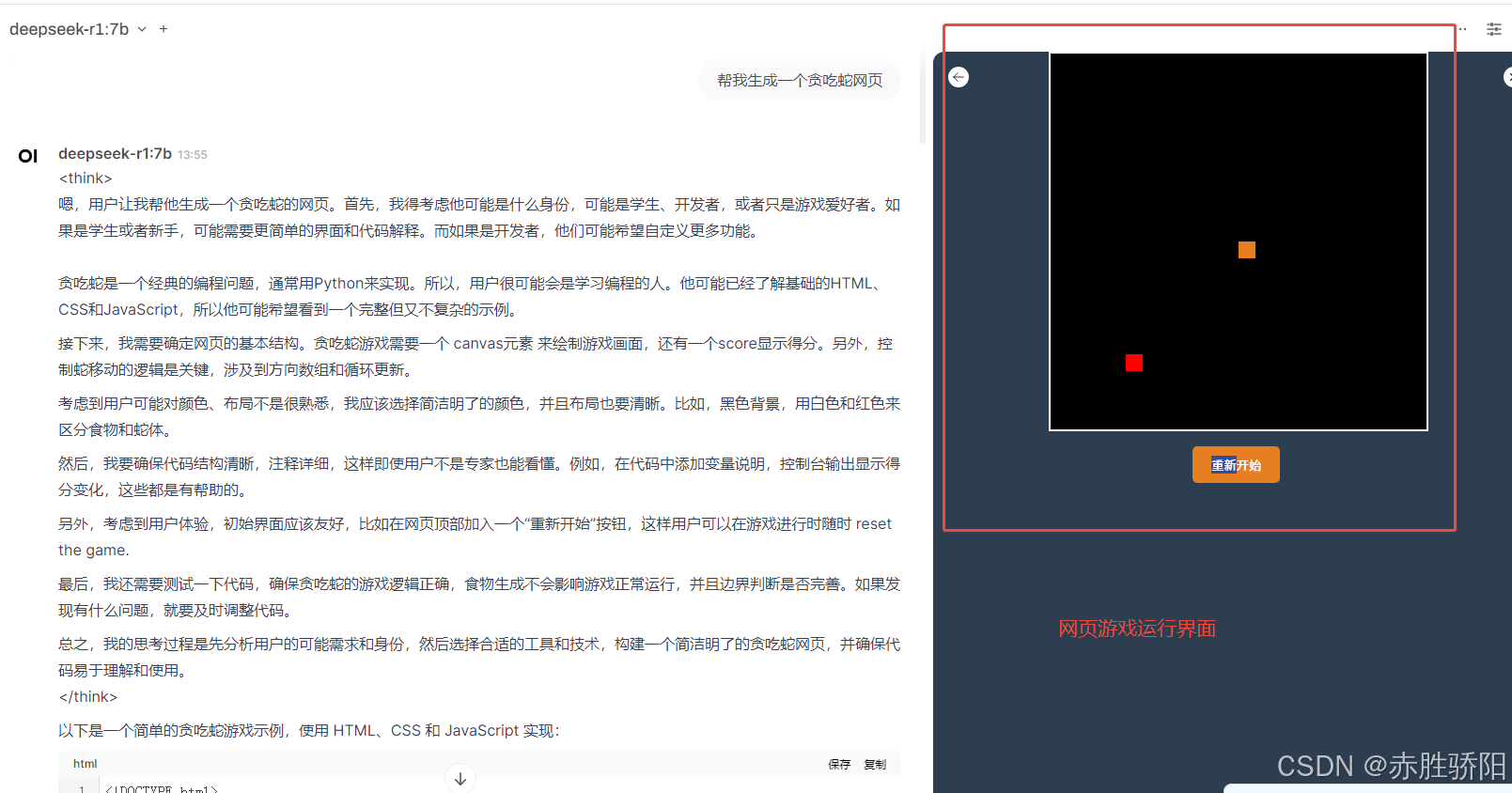
3.3.2 测试artifact
3.3.3 导入官网的工具
- 点击需要的工具
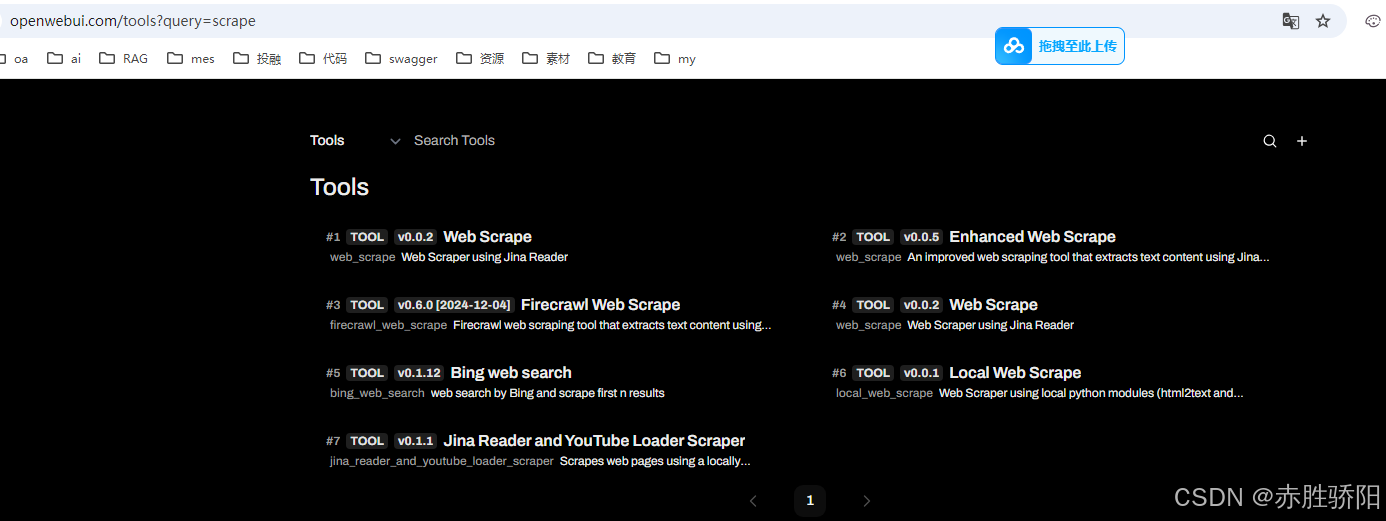
- 点击“get”
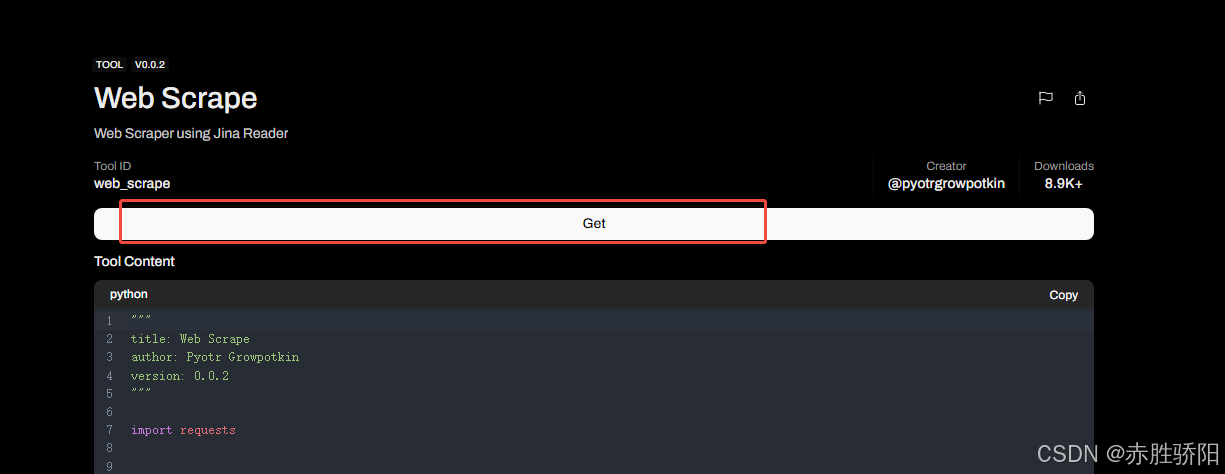
- 输入本地openwebui地址 : 默认localhost:3000
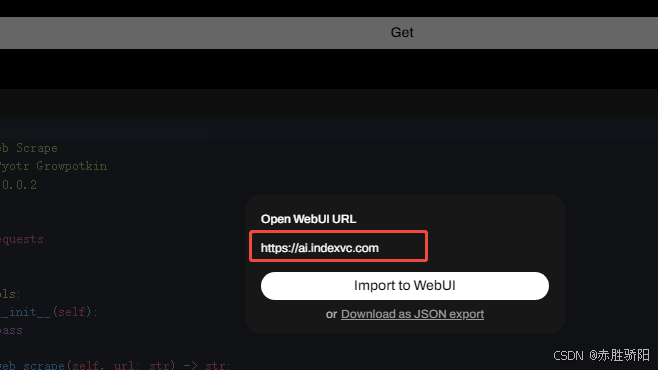
- 保存导入的工具
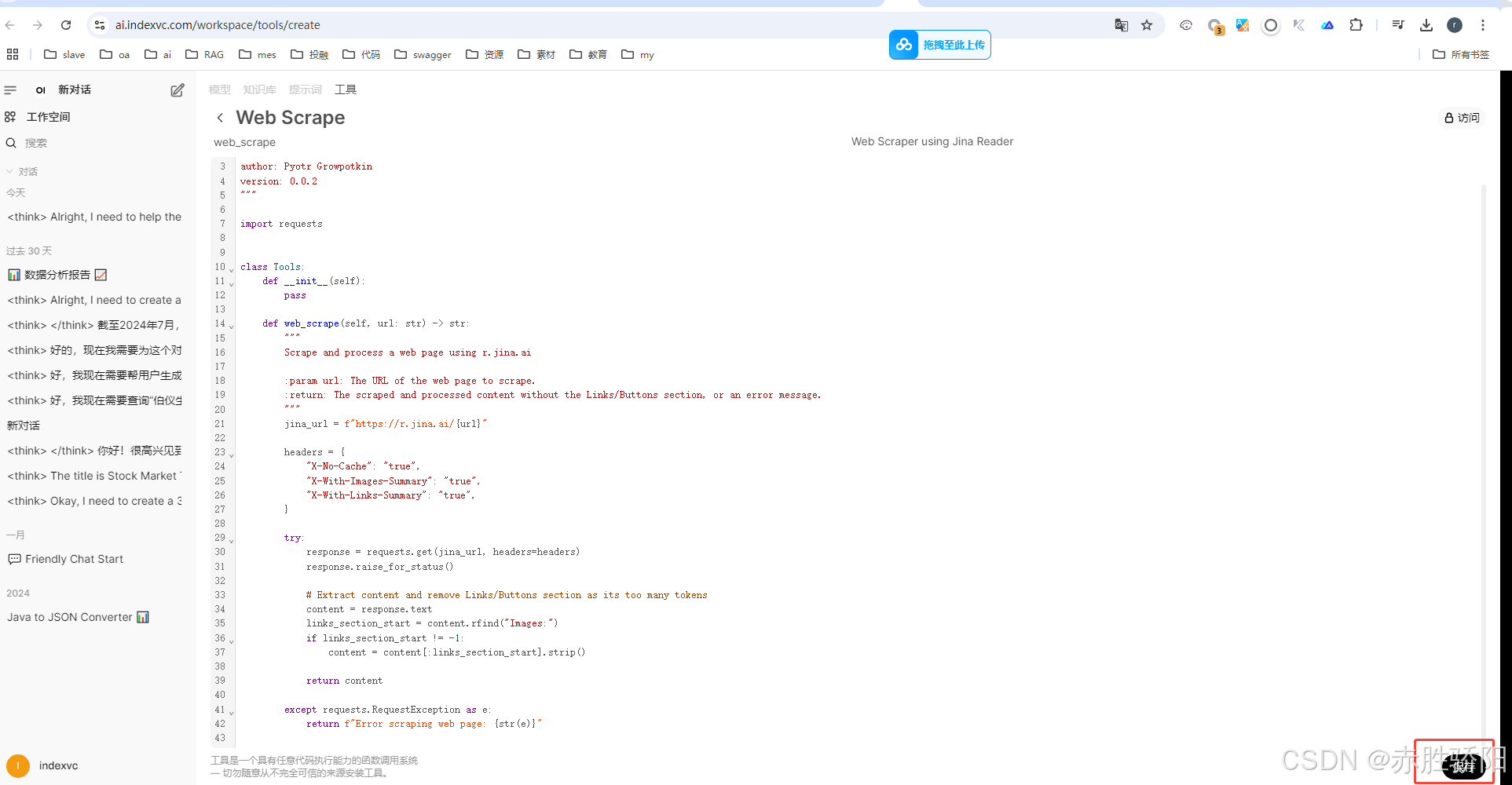
3.3.4 配置或更新语义向量模型
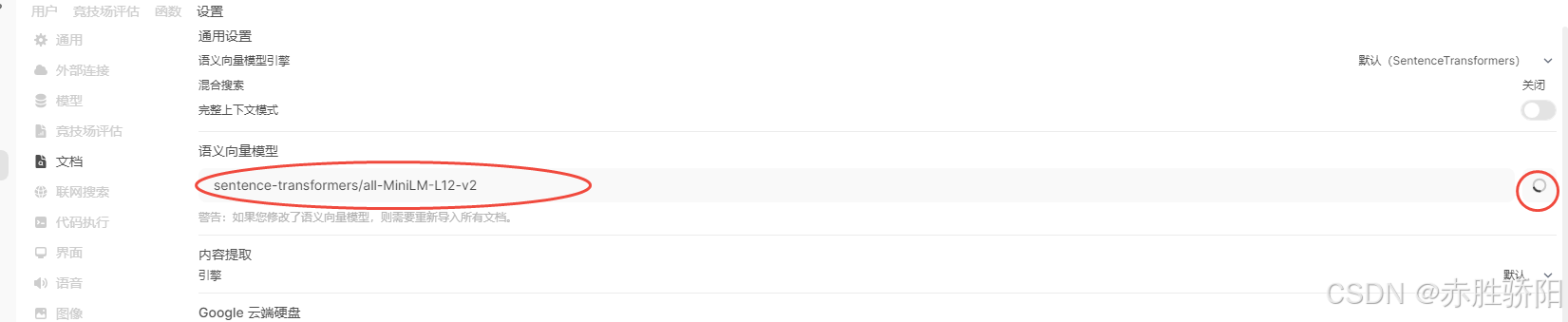
3.3.5 开启联网搜索
开启联网搜索前, 确认文档-》语义向量模型开启
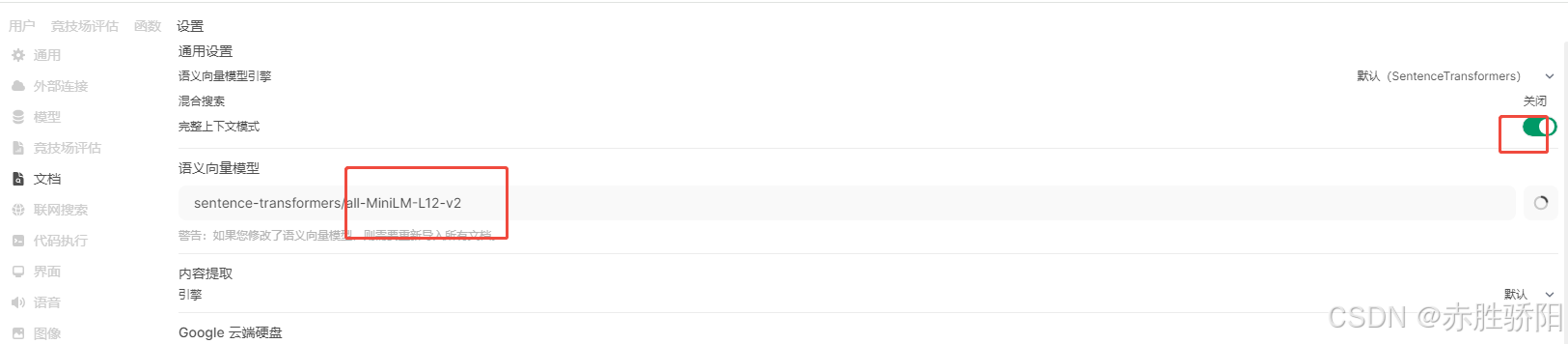
开启联网搜索。 其他google bing都需要api key ,选duckduckgo不需要
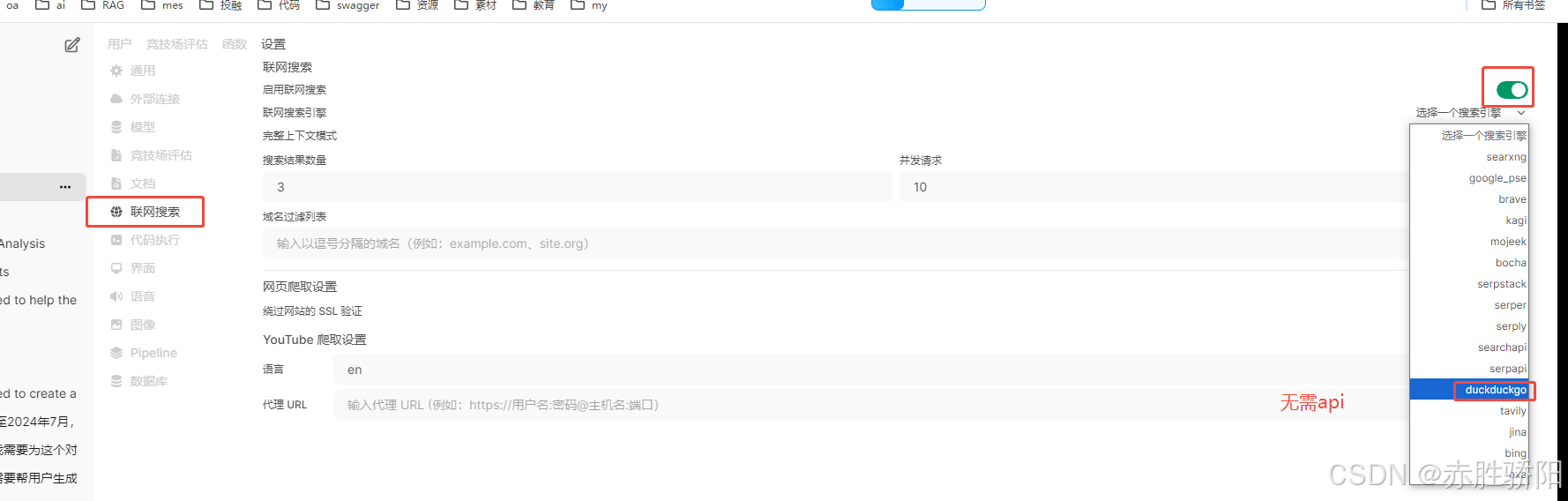
3.3.5 关闭openai 解决卡顿问题

3.3.6 添加DeepSeeksi思维链
官网下载函数入口
https://openwebui.com/f/zgccrui/deepseek_r1
点击Get
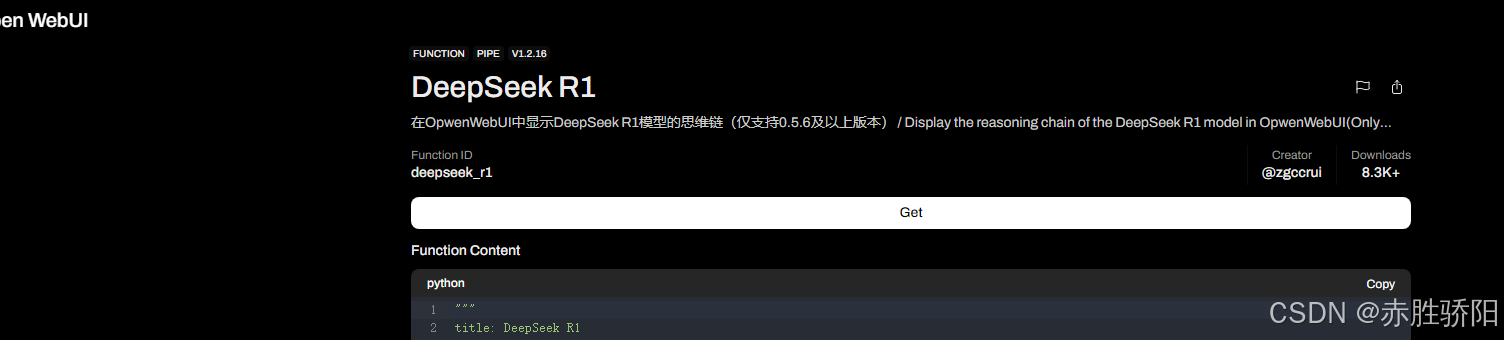
输入本地openwebui地址后保存
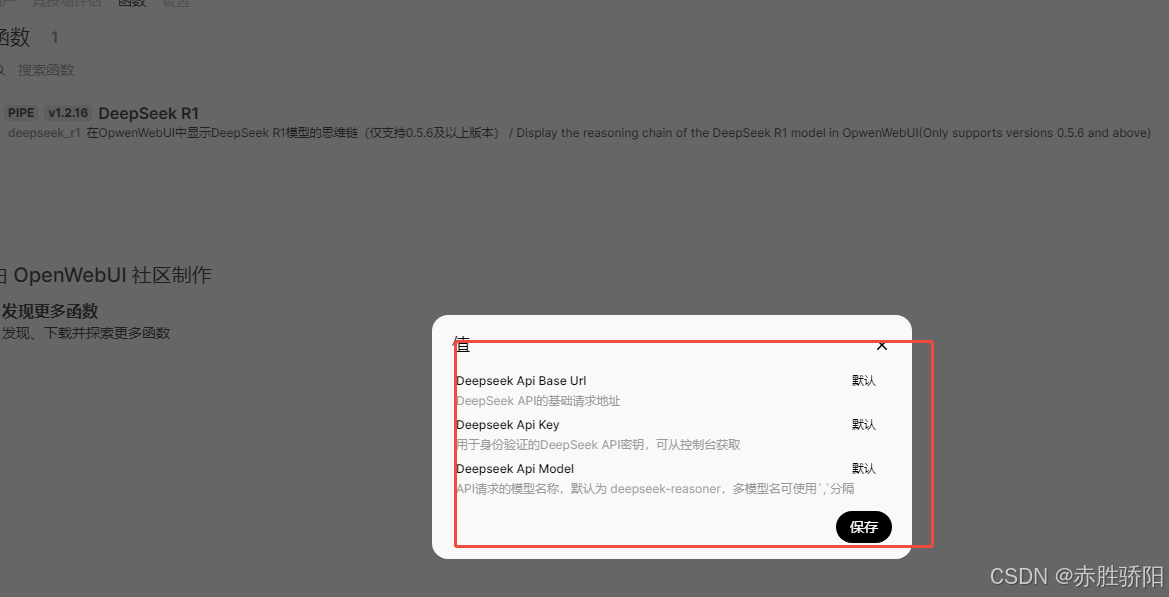
3.4 离线部署
先安装Docker
将在线下载的docker images保存

在离线的机器上装载该镜像
docker load -i open-webui.tar
使用3.2章节的命令启动容器即可
3.5 更新
官网有多种更新方式, 本文采用最简单
docker rm -f open-webui
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
053b9bb47a5de00499568e2a6e13527711375a789cf293de30e25c17e4395dd7
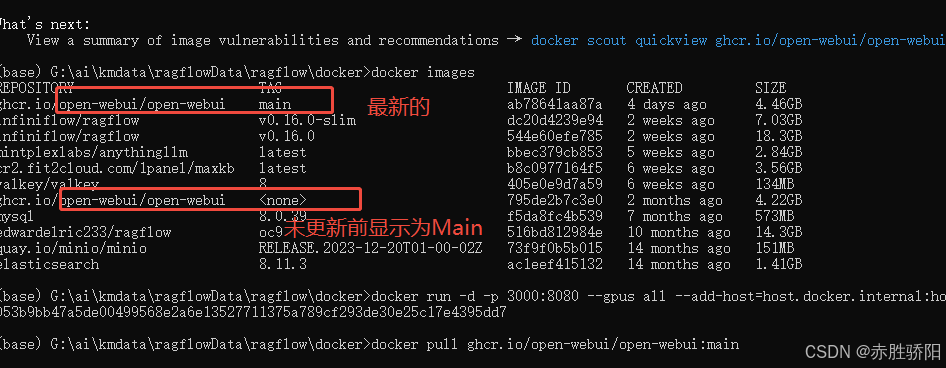
更新后遇到问题
使用nginx配置的代理会遇到此问题, 直接访问ip端口 , 一切正常
内网访问
- 配置 Ollama 服务的监听地址
Ollama 服务使用环境变量 OLLAMA_HOST 来指定监听的地址,默认情况下,它只监听 localhost,即只能本地访问。如果要让局域网内其他设备访问 Ollama 服务,需要将 OLLAMA_HOST 设为 0.0.0.0。
设置环境变量
在 Windows 中,可以通过以下步骤来设置环境变量 OLLAMA_HOST:
打开系统属性:
右键点击 此电脑 或 计算机,选择 属性。
在左侧点击 高级系统设置。
环境变量:
在弹出的窗口中,点击 环境变量。
新建系统环境变量:
在 系统变量 部分,点击 新建。
在 变量名 输入框中,输入 OLLAMA_HOST,在 变量值 输入框中,输入 0.0.0.0,然后点击 确定。
新建OLLAMA_ORIGINS,值为"*"

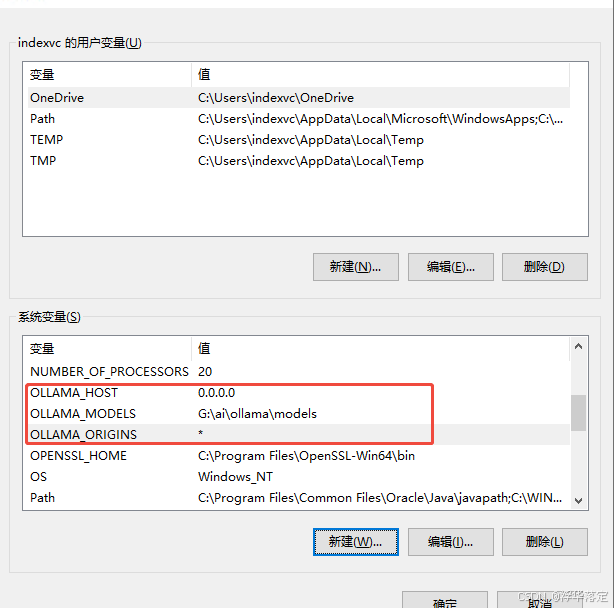
重启命令行窗口:
设置完成后,确保关闭并重新打开命令行窗口,使新的环境变量生效。
完成后,Ollama 服务将在所有网络接口上监听,包括局域网。
- linux配置
Ollama服务默认支持localhost,自动拒绝外网访问,若想支持外网访问接口,需要
修改ollama服务的配置文件。
打开 /etc/systemd/system/ollama.service.d/override.conf
加入environment
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
然后重启守护进程和服务,这时候,配置参数才能被重新加载。
systemctl daemon-reload
systemctl restart ollama
就可以了。
至于URL,Ollama的逻辑是这样的:
优先级:
最高优先级:显式传递 host 参数
如果指定了 host,则使用该值作为 base_url。
中等优先级:环境变量 OLLAMA_HOST
如果未传递 host,则检查并使用环境变量 OLLAMA_HOST 的值。
最低优先级:默认值 http://127.0.0.1:11434
如果 host 和 OLLAMA_HOST 均未设置,则使用默认值,假定服务在本地运行。
常用指令
开启ollam服务
ollama serve
查询已安装大模型
ollama list
然后,再打开一个窗口,执行下面的命令安装和在命令行中调用llama3大模型:
ollama run llama3
启动后,可以在命令行调用:
另外,回到代码环境,可以使用openai风格代码调用
!pip install openai
1
from openai import OpenAI
client =0penAI(
base url='http://localhost:11434/v1/',
api key='ollama', # required but ignored
)
chat_completion=client.chat.completions.create(
messages=[{'role':'user''content':'你好,请介绍下你自己’}],
model='llama3',
)
chat_completion.choices[0]
写一个多轮对话脚本
lef run chat session():
# 初始化客户端
client = 0penAI(base_url='http://localhost:11434/v1/',
api_key='ollama', # API key is required but ig
#初始化对话历史
chat_history =[]
#启动对话循环
while True:
# 获取用户输入
user_input = input("你:")
# 检查是否退出对话
if user_input.lower()=='exit':
print("退出对话。”)
break
#更新对话历史
chat_history.append({'role': 'user','content':user_input})
# 调用模型获取回答
try:
chat completion=client.chat.completions.create(
messages=chat_history,
model='llama3'
)
# 获取最新回答,适当修改以适应对象属性
model_response=chat_completion.choices[0]
print("AI:"model response)
# 更新对话历史
chat_history.append({'role':'assistant', 'content':model_response)
except Exception as e:
print("发生错误:",e)
break
run_chat_session()
总结
至此,完成了LLAMA3的模型部署,从测试的结果可以看到, llama3的基础模型对于中文的支持并不好,我们的问题是中文,它却返回了英文的结果,原因可能是因为它的训练集有15个T但是其中95%是英文,想要它支持中文更好,还需要使用中文的训练集进行微调,可喜的是,微调llma系列的中文训练集并不少(可能是因为llama系列都有这个问题),后续我会接着对llama3进行微调, 待续。。。



















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











