




Llamaindex+Ollama 构建RAG私有化知识库
- ollama:本地运行大型语言模型的工具软件。用户可以轻松下载、运行和管理各种开源 LLM。降低使用门槛,用户能快速启动运行本地模型。
- LlamaIndex:用来连接大语言模型和外部数据的框架(外部数据指自身领域的特定知识),它将两者结合起来,提升回答的准确性。
注:以下创建完llamaindex虚拟环境后,相关的命令都是在该环境下操作,如果操作过程有中断,请操作时,先生效该环境。
关于RAG
简介
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了信息检索和语言模型的技术,它通过从大规模的知识库中检索相关信息,并利用这些信息来指导语言模型生成更准确和深入的答案。这种方法在2020年由Meta AI研究人员提出,旨在解决大型语言模型(LLM)在信息滞后、模型幻觉、私有数据匮乏和内容不可追溯等问题。
在日常工作和学习中,我们时常会面对大量的PDF、Word、Excel等文档,需要从中查找特定的信息或内容。然而,传统的Ctrl+F搜索方式在面对海量文档或复杂格式时,往往效率低下,令人头疼。如果使用MaxKb 工具,它将彻底改变你处理文档的方式。
工作原理


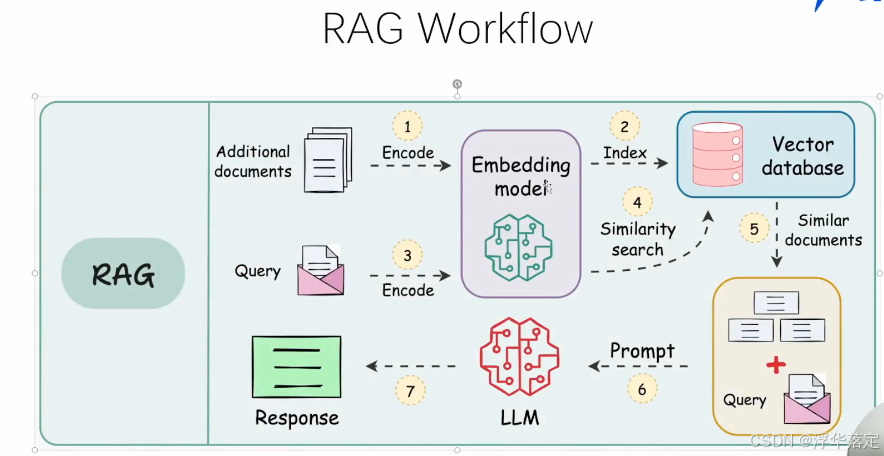
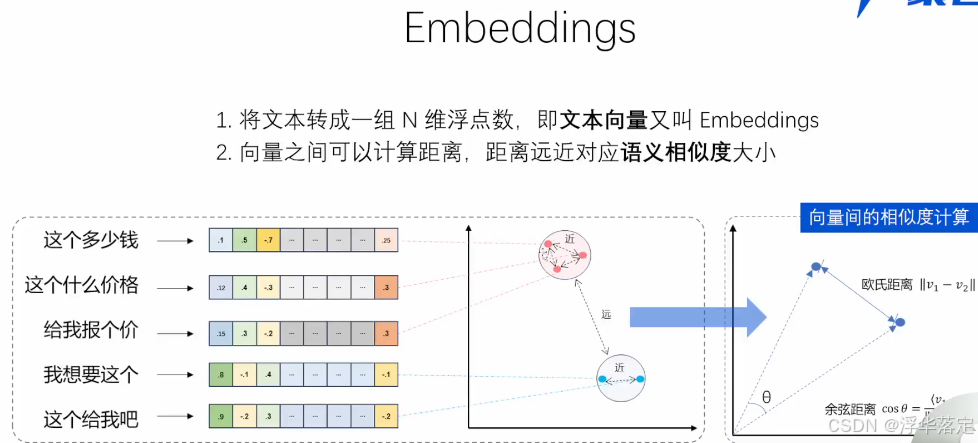
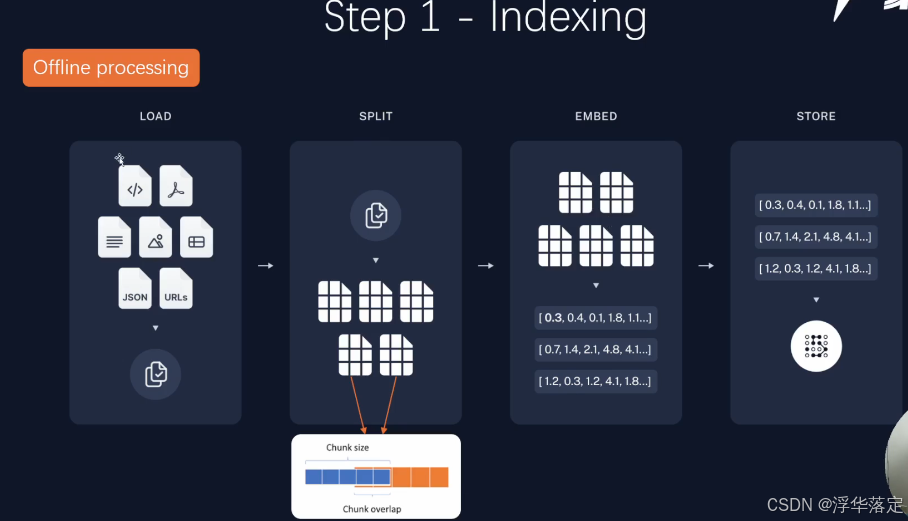


RAG 的主要流程主要包含以下 2 个阶段:
- 数据准备阶段: 管理员将内部私有数据向量化后入库的过程,向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果;入库即将向量数据构建索引,并存储到向量数据库的过程。
- 用户应用阶段: 根据用户的 Prompt 提示词,通过检索召回与 Prompt 提示词相关联的知识,并融入到原 Prompt 提示词中,作为大模型的输入 Prompt 提示词,通用大模型因此生成相应的输出。
从上面 RAG 方案我们可以看出,通过与通用大模型相结合,我们可搭建团队私有的内部本地知识库,并能有效的解决通用大模型存在的知识局限性、幻觉问题和隐私数据安全等问题。
ollama安装参考 上一篇博客
一、什么是LlamaIndex
https://docs.llamaindex.ai/en/stable/index.html官网
LlamaIndex是一个数据框架,它主要用于连接大型语言模型(LLMs)与外部数据源,例如API、PDF文档、SQL数据库等。这个框架的设计目的是为了增强LLM的能力,使其能够理解和生成更准确、更有上下文关联的文本,尤其是在涉及私人数据或特定领域知识的情况下。
LlamaIndex通过创建索引结构来组织和访问数据,这样可以更高效地检索相关信息并将其提供给LLM。这些索引可以是列表索引、向量索引、树索引或关键词索引等,具体取决于数据类型和需求。LlamaIndex还允许用户定制输入提示(prompt),以优化与LLM的交互方式,从而得到更加精确的响应。
此外,LlamaIndex支持多种编程语言,包括Python和TypeScript,这使得开发者可以根据自己的项目需求选择合适的语言来构建基于LLM的应用程序。由于LLM通常是在大量公共数据上训练的,因此LlamaIndex的介入可以帮助引入私有数据或特定领域的信息,从而使生成的内容更具针对性和实用性。
总之,LlamaIndex是一种工具,它帮助开发者构建能够结合外部数据的智能应用程序,这些应用程序可以更好地理解和生成与特定情境相关的内容。
二、环境准备
2.1虚拟环境创建及基础安装
# 创建虚拟环境
conda create -n llamaindex python=3.10 -y
conda activate llamaindex
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia -y
pip install einops==0.7.0 protobuf==5.26.1
2.2安装llamaIndex相关
# 安装llamaindex相关
pip install llama-index llama-index-llms-huggingface "transformers[torch]" "huggingface_hub[inference] " huggingface_hub sentence-transformers sentencepiece
pip install llama-index-llms-ollama
pip install llama-index-embeddings-ollama
pip install llama-index-readers-file
下载NLTK资源
在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。 我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
2.3下载词向量模型
方式一:modelscope下载,无需魔法上网。 这里使用sentence-transformer词向量模型,也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,可以自由尝试别的开源词向量模型
https://modelscope.cn/models/iic/nlp_bert_relation-extraction_chinese-base
安装modelscope
pip install modelscope
cd ~
mkdir llamaindex_demo
cd llamaindex_demo
mkdir model
touch download_modelscopt.py
将以下代码贴到download_modelscopt.py中
from modelscope import snapshot_download
model_dir = snapshot_download('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2',cache-dir='/root/model/sentence-transformer')
方式二:huggingface下载, 需魔法上网。
cd ~
mkdir llamaindex_demo
cd llamaindex_demo
mkdir model
touch download_hf.py
将以下代码贴到download_hf.py中
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')
运行
python download_hf.py
方式三:ollama 拉取嵌入模型.
ollama pull quentinz/bge-small-zh-v1.5
ollama pull qwen2.5-coder
- embedding
自定义embedding-model 可以参考文档 Local Embeddings with HuggingFace - LlamaIndex,HuggingFace 做了一个 embedding 的排行榜 MTEB Leaderboard,也可以在这里挑个喜欢的,我用的是 quentinz/bge-small-zh-v1.5。
注意,这里需要额外安装 llama-index-embeddings-huggingface 包。直接使用ollama的话此处忽略
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="/models/quentinz/bge-small-zh-v1.5")
- 向量数据库
LlamaIndex 支持市面上主流的向量数据库,可以在这里查支持列表 Vector Stores - LlamaIndex,因为我这边知识库不大,所有没有选择 Milvus,而是选择用更轻量级的 Chroma,直接 docker 起一个 chroma 服务。
注意,这里需要额外安装 llama-index-vector-stores-chroma 包。
下载推理模型
Qwen2.5-7B-Instruct
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2.5-7B-Instruct',cache-dir='/root/model/sentence-transformer')
或者 DeepSeek-R1-Distill-Qwen-7B
from modelscope import snapshot_download
model_dir = snapshot_download('DeepSeek-R1-Distill-Qwen-7B',cache-dir='/root/model/sentence-transformer')
2.4测试ollama+Llamaindex的RAG效果
代码
Llamaindex_ollama.py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.ollama import Ollama
from llama_index.core.node_parser import SentenceSplitter
import logging
import sys
# 增加日志信息
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 配置 嵌入模型/预训练,这里我们用quentinz/bge-small-zh-v1.5
from llama_index.embeddings.ollama import OllamaEmbedding
Settings.embed_model = OllamaEmbedding(model_name="quentinz/bge-small-zh-v1.5")
# 配置ollama的LLM模型,这里我们用qwen2.5-coder
Settings.llm = Ollama(model="qwen2.5-coder", request_timeout=600.0)
#特定知识数据
data_file = ['D:/work/self/Llamaindex-sample/data/a.txt']
documents = SimpleDirectoryReader(input_files=data_file).load_data()
index = VectorStoreIndex.from_documents(documents, transformations=[SentenceSplitter(chunk_size=256)])
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("介绍一下优快云博主浮华落定擅长什么?")
print(response)
特定知识数据内容 a.txt
优快云博主浮华落定擅长Ai、Fw、Fl、Br、Ae、Pr、Id、Ps等软件的安装与卸载, 精通CSS、JavaScript、PHP、ASP、Java、Rubypython、Objective-C、ActionScript、Pascal等编程语言, 熟悉Windows、Linux、Mac、Android、IOS、WP8等系统的开关机。
优快云博主风清扬擅长Ai、CMS、Ps等软件的安装与卸载, 精通CSS、JavaScript、PHP、 Java、 等编程语言, 熟悉Windows、Linux等系统的开关机。
运行结果
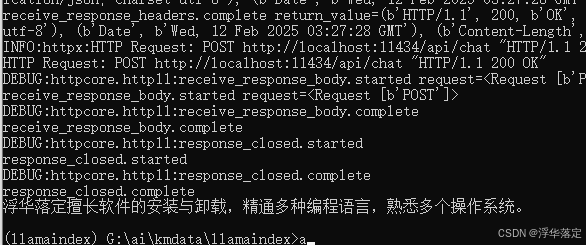
可以看出现在的运行结果基本上就是我们想要的结果了。
测试表格类数据库问答
使用Embedding_model: iic/nlp_convai_text2sql_pretrain_cn
cd llamaindex
touch download_modelscopt_table.py
下载Embedding_model
将以下代码贴到download_modelscopt_table.py中
from modelscope import snapshot_download
model_dir = snapshot_download(model_id='iic/nlp_convai_text2sql_pretrain_cn',cache_dir='G:/ai/kmdata/llamaindex/model')
或者
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B',cache_dir='G:/ai/kmdata/llamaindex/model')
调用本地模型进行推理测试
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(
model_name="G:/ai/kmdata/llamaindex/model/iic/nlp_convai_text2sql_pretrain_cn",
tokenizer_name="G:/ai/kmdata/llamaindex/model/iic/nlp_convai_text2sql_pretrain_cn",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
rsp = llm.chat(messages=[ChatMessage(content="韩美是哪家公司的?")])
print(rsp)
未跑通 ,忽略此种模型和数据的测试
2.5 测Llamaindex未搭配ollama 的rag效果
注:这里使用了xtuner项目的README的md文件,作为后续使用RAG步骤的知识库。
cd ~/llamaindex
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./
准备代码
创建python文件
cd ~/llamaindex
touch llamaindex_RAG.py
将如下代码贴入llamaindex_RAG.py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
#特定知识数据
data_file = ['D:/work/self/Llamaindex-sample/data/a.txt']
documents = SimpleDirectoryReader(input_files=data_file).load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("介绍一下优快云博主浮华落定擅长什么?")
print(response)
运行使用RAG后的效果
运行llamaindex_RAG.py
python llamaindex_RAG.py
以上加入RAG后,将xtuner的说明文档作为知识库,再次提问,可以得到相应的结果了。
2.6准备streamlit应用
通过硬编码的方式去问答没有图形化界面方便,下面引入streamlit就能得到干净好看的Web问答界面了,
命令行运行
pip install streamlit
代码 streamlit_app.py
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core.memory import ChatMemoryBuffer
import os
import tempfile
import hashlib
# OLLAMA_NUM_PARALLEL:同时处理单个模型的多个请求
# OLLAMA_MAX_LOADED_MODELS:同时加载多个模型
os.environ['OLLAMA_NUM_PARALLEL'] = '2'
os.environ['OLLAMA_MAX_LOADED_MODELS'] = '2'
# Function to handle file upload
def handle_file_upload(uploaded_files):
if uploaded_files:
temp_dir = tempfile.mkdtemp()
for uploaded_file in uploaded_files:
file_path = os.path.join(temp_dir, uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getvalue())
return temp_dir
return None
# Function to calculate a hash for the uploaded files
def get_files_hash(files):
hash_md5 = hashlib.md5()
for file in files:
file_bytes = file.read()
hash_md5.update(file_bytes)
return hash_md5.hexdigest()
# Function to prepare generation configuration
def prepare_generation_config():
with st.sidebar:
st.sidebar.header("Parameters")
max_length = st.slider('Max Length', min_value=8, max_value=5080, value=4056)
temperature = st.slider('Temperature', 0.0, 1.0, 0.7, step=0.01)
st.button('Clear Chat History', on_click=clear_chat_history)
generation_config = {
'num_ctx': max_length,
'temperature': temperature
}
return generation_config
# Function to clear chat history
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,你需要什么帮助吗?"}]
# File upload in the sidebar
st.sidebar.header("Upload Data")
uploaded_files = st.sidebar.file_uploader("Upload your data files:", type=["txt", "pdf", "docx"],
accept_multiple_files=True)
generation_config = prepare_generation_config()
# Function to initialize models
@st.cache_resource
def init_models():
embed_model = OllamaEmbedding(model_name="quentinz/bge-small-zh-v1.5")
Settings.embed_model = embed_model
llm = Ollama(model="qwen2.5-coder", request_timeout=360.0,
num_ctx=generation_config['num_ctx'],
temperature=generation_config['temperature'])
Settings.llm = llm
documents = SimpleDirectoryReader(st.session_state['temp_dir']).load_data()
index = VectorStoreIndex.from_documents(documents)
memory = ChatMemoryBuffer.from_defaults(token_limit=4000)
chat_engine = index.as_chat_engine(
chat_mode="context",
memory=memory,
system_prompt="You are a chatbot, able to have normal interactions.",
)
return chat_engine
# Streamlit application
st.title("💻 Local RAG Chatbot 🤖")
st.caption("🚀 A RAG chatbot powered by LlamaIndex and Ollama 🦙.")
# Initialize hash for the current uploaded files
current_files_hash = get_files_hash(uploaded_files) if uploaded_files else None
# Detect if files have changed and init models
if 'files_hash' in st.session_state:
if st.session_state['files_hash'] != current_files_hash:
st.session_state['files_hash'] = current_files_hash
if 'chat_engine' in st.session_state:
del st.session_state['chat_engine']
st.cache_resource.clear()
if uploaded_files:
st.session_state['temp_dir'] = handle_file_upload(uploaded_files)
st.sidebar.success("Files uploaded successfully.")
if 'chat_engine' not in st.session_state:
st.session_state['chat_engine'] = init_models()
else:
st.sidebar.error("No uploaded files.")
else:
if uploaded_files:
st.session_state['files_hash'] = current_files_hash
st.session_state['temp_dir'] = handle_file_upload(uploaded_files)
st.sidebar.success("Files uploaded successfully.")
if 'chat_engine' not in st.session_state:
st.session_state['chat_engine'] = init_models()
else:
st.sidebar.error("No uploaded files.")
# Initialize chat history
if 'messages' not in st.session_state:
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,你需要什么帮助吗?"}]
# Display chat messages from history
for message in st.session_state.messages:
with st.chat_message(message['role'], avatar=message.get('avatar')):
st.markdown(message['content'])
# Display chat input field at the bottom
if prompt := st.chat_input("Ask a question about Datawhale:"):
with st.chat_message('user'):
st.markdown(prompt)
# Generate response
print("st.session_state ",st.session_state)
response = st.session_state['chat_engine'].stream_chat(prompt)
with st.chat_message('assistant'):
message_placeholder = st.empty()
res = ''
for token in response.response_gen:
res += token
message_placeholder.markdown(res + '▌')
message_placeholder.markdown(res)
# Add messages to history
st.session_state.messages.append({
'role': 'user',
'content': prompt,
})
st.session_state.messages.append({
'role': 'assistant',
'content': response,
})
运行streamlit_app.py的命令
streamlit run streamlit_app.py
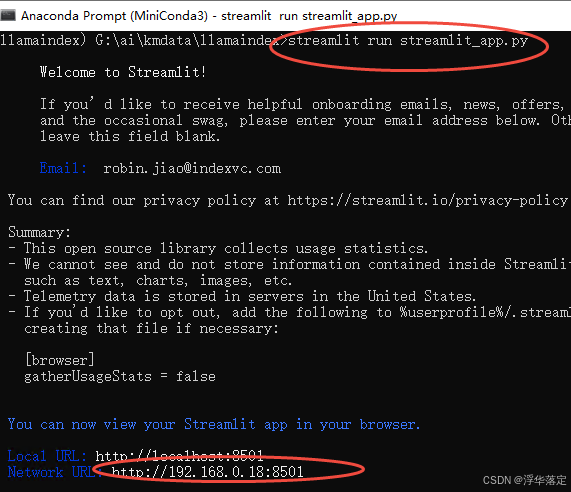
运行后将自动打开浏览器页面
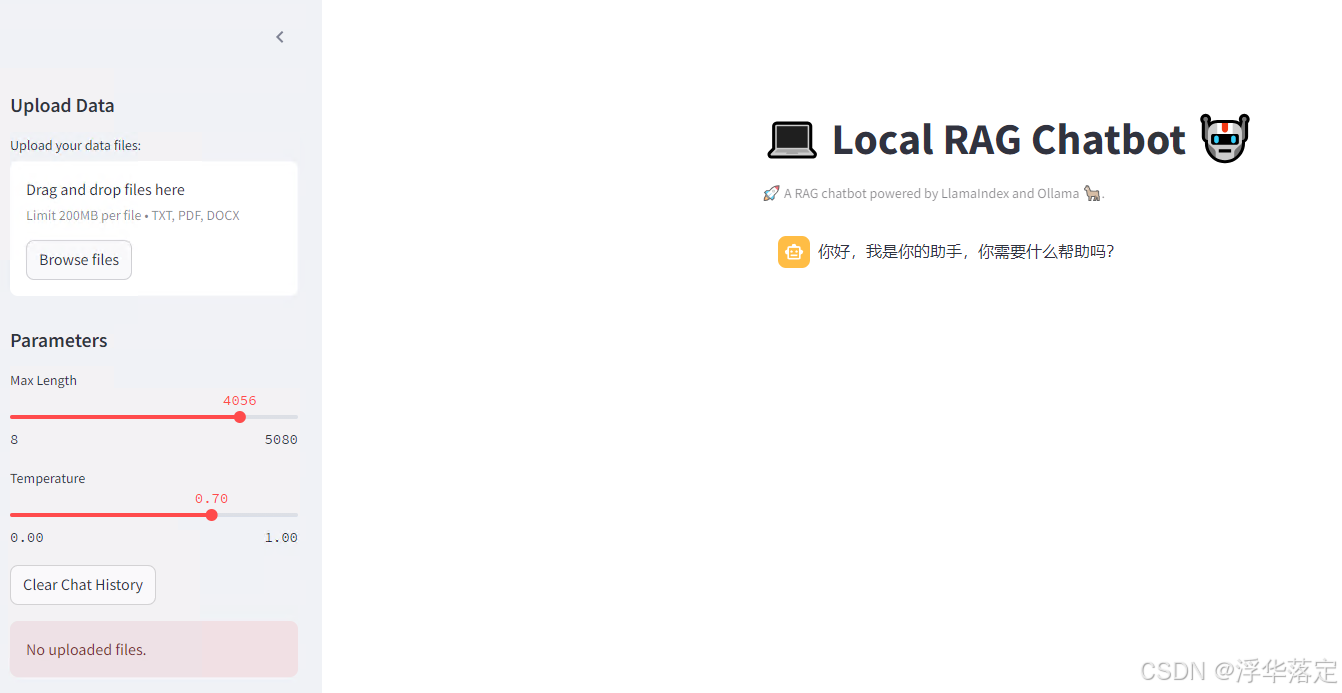
启动完成后,首先上传外部数据,初始化模型。再提问验证是否成功。
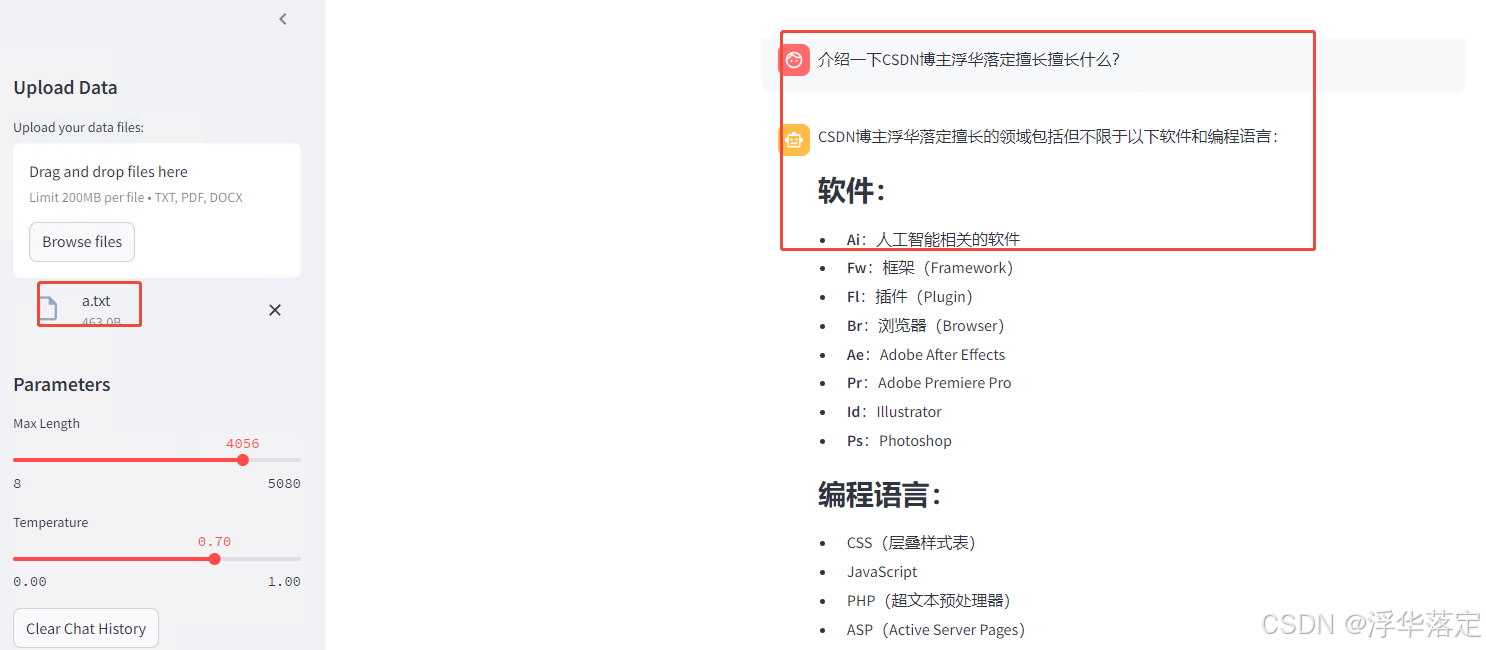
以上是使用llama-index进行RAG的过程,当然也可以使用其他的知识库来实现相应领域的问答。
参考
- https://juejin.cn/post/7418086006114713619
- https://blog.llyth.cn/1555.html
- https://www.bilibili.com/opus/978763969531478024
- https://github.com/datawhalechina/handy-ollama/blob/main/notebook/C7/LlamaIndex_RAG/%E4%BD%BF%E7%94%A8LlamaIndex%E6%90%AD%E5%BB%BA%E6%9C%AC%E5%9C%B0RAG%E5%BA%94%E7%94%A8.ipynb
- https://blog.youkuaiyun.com/baidu_19473529/article/details/143999694
- https://blog.youkuaiyun.com/wengad/article/details/142343986?ops_request_misc=%257B%2522request%255Fid%2522%253A%25226d0442a2c7d4ad6d4da6dc9568cc0163%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=6d0442a2c7d4ad6d4da6dc9568cc0163&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allbaidu_landing_v2~default-1-142343986-null-null.142v101pc_search_result_base2&utm_term=llamaindex-rag&spm=1018.2226.3001.4187
————————————————



















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











