






 WoodScape是一个独特的数据集,包含鱼眼图像和多种注释类型,支持自动驾驶的多任务学习,包括语义分割、2D/3D物体检测等。此数据集旨在促进在鱼眼图像上的本地视觉算法开发。
WoodScape是一个独特的数据集,包含鱼眼图像和多种注释类型,支持自动驾驶的多任务学习,包括语义分割、2D/3D物体检测等。此数据集旨在促进在鱼眼图像上的本地视觉算法开发。
一、简介:
KITTI数据集是第一个用于多任务的数据集,驱动了很多自动驾驶的研究
cityscape提供了语义分割数据集
Mapillary[39]提供了更大的数据集
Apolloscape[24]和BDD100k[59]是较新的数据集这进一步推动了注释比例
WoodScape的独特之处在于,它提供鱼眼图像数据以及全面的注释类型。表1提供了这些不同数据集的比较汇总
1.第一个鱼眼数据集,包含10000多个包含实例级语义注释的图像。
2.四摄像机九任务数据集,旨在鼓励统一的多任务和多摄像机模型。
3.引入新的污染检测任务,并发布第一个此类数据集。
4.针对3D盒子检测任务提出了一个有效的指标,将培训时间提高了95倍。
本文的结构如下。第二节概述了鱼眼摄像机模型、去失真方法和视觉算法的鱼眼自适应。第3节讨论了数据集的细节,包括目标、捕获基础设施和数据集设计。第4节列出了支持的任务和基线实验。最后,第五部分对本文进行了总结和总结。
二、鱼眼相机投影概述
鱼眼相机优点明显,就是能看的视野范围更广泛,有了这个优点就可以用最少的传感器捕捉最全的画面。鱼眼相机所呈现的投影几何体要复杂得多,但这种优势也有一些缺点。也就是说,鱼眼相机的图像显示严重失真。对于鱼眼相机图像,必须充分理解适当的相机模型,以处理算法中的失真或在处理之前扭曲图像。本节旨在向读者强调鱼眼相机型号需要特别注意。我们提供了一个简要的概述和参考资料,以了解更多细节,并讨论了在原始鱼眼上操作与图像不失真相比的优点。
2.1鱼眼相机模型
鱼眼畸变由径向映射函数r建模,其中r是图像上距畸变中心的距离,是入射光线与相机系统光轴的角度的函数。畸变中心是光轴与像平面的交点,是径向映射函数r()的原点。Stereographic projection 是使用从球体到平面的映射的最简单模型。最近的投影模型是统一摄像机模型(UCM)
[1,7]和eUCM(增强型UCM)[27]。在[25]中对各种投影模型的精度进行了更详细的分析。这些模型并不完全适合鱼眼相机,因为它们encode特定的几何体(例如球面投影),并且通过使用附加的失真校正组件来补偿模型中产生的误差
在WoodScape中,我们为更通用的鱼眼固有校准提供了模型参数,该校准独立于任何特定的投影模型,并且不需要额外的失真校正步骤。我们的模型基于四阶多项式,将入射角映射为以像素为单位的图像半径![]() 根据我们的经验,较高的订单不能提供额外的准确性。数据集中的每个视频序列都提供了鱼眼内在函数的四阶多项式模型的参数
根据我们的经验,较高的订单不能提供额外的准确性。数据集中的每个视频序列都提供了鱼眼内在函数的四阶多项式模型的参数
作为比较,为了让读者了解不同模型的行为,图3显示了五种不同投影模型的映射函数r(),它们是多项式、直线、立体、UCM和eUCM。四阶多项式的参数取自我们鱼眼透镜的校准。我们优化了其他模型的参数,以在0到120范围内匹配该模型(即FOV高达240)。该图表明对于低入射角,UCM与原始四阶多项式的差值约为四个像素,eUCM为一个像素。对于入射角,这些模型不太精确。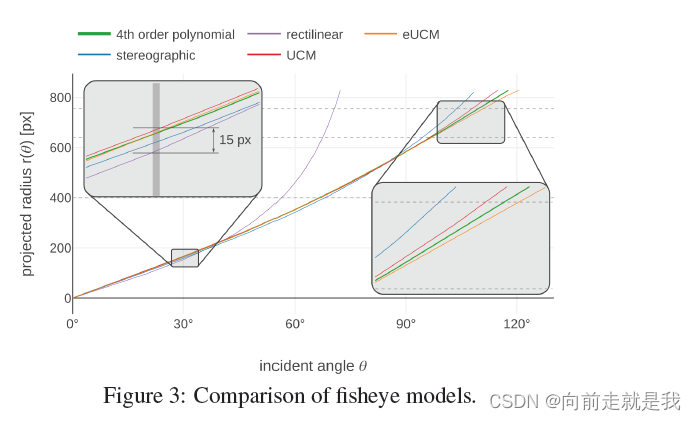
2.2 图像不失真与模型调整
由于非线性失真较大,标准的计算机视觉模型不容易推广到鱼眼摄像机。例如,标准卷积神经网络(CNN)的平移不变性会丢失。鱼眼相机算法发展的唯一途径 是进行直线校正,以便应用标准模型。最简单的不失真是将像素重新扭曲为直线图像,如图4(a)所示。但有两个主要问题。首先,FOV大于180,因此存在从相机后面入射的光线,不可能建立到直线视口的完整映射。这导致视野丧失,这可以通过校正图像中丢失的黄色柱看到。其次,有一个问题重采样失真,在图像边缘附近更明显,较小的区域映射到较大的区域
ps:不变性意味着即使目标的外观发生了某种变化,但是你依然可以把它识别出来。这对图像分类来说是一种很好的特性,因为我们希望图像中目标无论是被平移,被旋转,还是被缩放,甚至是不同的光照条件、视角,都可以被成功地识别出来。

如图4(b)所示,可以通过多个线性视口解决缺少的视野。然而,从一个平面到另一个平面的过渡区域存在问题。这可以看作是鱼眼透镜歧管。图4(c)显示了使用圆柱形视口的准线性校正,其中垂直方向呈线性,并保留了行人等垂直直线对象。然而,沿水平轴存在二次扭曲。在许多情况下,它提供了合理的权衡,但仍有局限性。在学习算法的情况下,可以优化参数变换,以优化目标应用精度的性能。
由于不失真的基本限制,采用另一种方法,即结合上一节讨论的鱼眼模型调整算法,可能是最佳解决方案。对于经典几何算法,可以合并非线性投影的分析版本。例如,Kukelova等人[32]通过合并径向畸变模型扩展了单应性估计。对于深度学习算法,一个可能的解决方案是训练CNN模型来学习失真。然而,CNN的翻译不变性假设由于空间变异失真而崩溃,因此让网络隐式学习是无效的。这导致美国有线电视新闻网(CNN)进行了多次修改,以处理球形图像,如[52]和[9]。然而,球形模型不提供鱼眼镜片的精确配合,这是一个公开的问题。
三、WoodScape数据集概述
3.1 高阶目标
该数据集的主要目标之一是鼓励研究社区在鱼眼图像上开发本地视觉算法,而不会产生失真。公共鱼眼数据集很少,没有一个提供语义分割注释。Fisheye特别适用于汽车低速操控场景,例如停车[21],在停车场,仅需四个摄像头即可实现精确的全覆盖近场感测。
全方位视图系统至少有四个摄像头与车身刚性连接。普莱斯[42]在推导摄像机网络建模框架方面做了开创性的工作,这种方法对于视觉里程表等几何视觉算法很有用。然而,对于语义分割算法,还没有关于刚性连接摄像机联合建模的文献。
自主驾驶有多种视觉任务,大部分工作都集中在独立解决个人任务上。然而,最近
趋势[30,53,51,8]使用单个多任务模型求解任务,以实现编码器特征的有效重用,并在学习多个任务时提供正则化。然而,在这些情况下,只有编码器是共享的,解码器之间没有协同作用。现有数据集主要是旨在促进特定任务的学习,并且它们不为所有任务提供同步注释。我们设计了数据集,以便为各种任务提供同步注释,但由于每个任务的最佳数据集设计的实际局限性,存在一些例外。
3.2 数据集的采集
3.3 数据集的设计
机器学习数据集的设计是一项非常复杂的任务。不幸的是,由于深度学习取得了压倒性的成功,最近它并没有像我们认为的那样得到应有的重视。然而,在
同时,研究表明,仔细检查训练集中的异常值可以提高深度神经网络的鲁棒性[36],特别是对于对抗性示例。因此,我们相信,无论何时
一个新的数据集发布后,不仅要在数据采集上花费大量的精力,还要在仔细的一致性检查和数据库拆分上花费大量精力,以满足培训、模型选择和测试的需要。
采样策略:让我们定义一些符号和命名约定,我们将首先参考它们(我们遵循[4]中提供的定义)。总体是所有现有特征向量的集合。在某些过程中收集的一个子集称为样本集S。代表集S 明显小于S,同时从S中捕获大多数信息(与相同大小的任何不同子集相比),并且在样本集之间具有低冗余它包含的代表
在理想情况下,我们希望我们的训练集等于S。这在实践中极难实现。一种近似方法是训练集的最小一致子集的概念,其中,给定训练集T,我们感兴趣的是一个子集T,它是Acc(T)=Acc(T)的最小集,其中Acc()表示所选的精度度量(例如Jaccard指数)。注意,准确度的计算意味着
基本真相标签。其目的是通过删除非信息性样本来减小训练集的大小,这些样本无助于改进学习的模型,因此可以简化注释工作。
有几种获得T的方法。一种常用的方法是实例选择[40,35,26]。有两组主要的实例选择:包装器和过滤器。基于包装器的方法使用基于构造分类器准确性的选择标准。基于筛选器另一方面,方法使用基于无关选择函数的选择标准。最小一致子集的概念对于我们的设置至关重要,我们从摄像机中记录图像数据。以每秒30帧的帧速率收集帧,特别是在低速时,最终会导致显著的图像重叠,因此,具有有效的采样策略来提取数据集至关重要。我们结合使用了一种包装方法,该方法使用基于分类器准确性的选择标准[40]和基于图像相似性度量的简单过滤器。
数据分割和类平衡:数据集按6:1:3的比例分为三个块,即训练、验证和测试。对于经典算法,所有数据都可以用于测试。顾名思义,培训部分仅用于培训目的,验证部分可以与培训集结合(例如,当所寻求的模型不需要超参数选择时),也可以用于模型选择,最后,测试集仅用于模型评估目的。该数据集支持正确的假设评估[55],因此提供了多个分割(总共5个)。根据特定任务(完整列表见第4节),阶级不平衡可能是一个问题[19],因此,也提供了特定任务的划分。提供了对分割机制的完全控制,允许在每次分割中平均代表每个类别(即分层抽样)。
GDPR挑战:最近欧洲的《通用数据保护条例》(GDPR)规定给我们的数据公开带来了挑战。超过三分之一的数据集记录在欧洲因此,由于行人和车牌的面部可见,GDPR敏感。处理隐私的主要方法有三种,即(1)手动模糊,(2)基于GAN的重定目标和(3)严格的数据处理许可协议。模糊是隐私保护的常用方法图像中的敏感区域被手动模糊。也有可能使用基于GAN的重新定位,其中面部由自动生成的面部进行交换[31]。在最近的欧洲城市人员数据集[5]中,作者认为任何匿名化措施都会引入偏见。因此,他们发布了带有原始数据和许可协议的数据集,强制用户严格遵守GDPR。我们将采用类似的方法。
四、任务、指标和基线实验
由于篇幅有限,我们简要描述了每个任务的指标和基线实验,并在表2中进行了总结。每个任务的测试数据集包含表1中所列注释样本的30%。代码可在WoodScape GitHub和样本视频中获得
结果在补充材料中共享。
4.1语义分割
用于自动驾驶的语义分割网络[47]已在[12,45]中直接在鱼眼图像上成功训练。由于缺乏鱼眼数据集,他们利用了城市景观的人工扭曲图像对鱼眼图像进行训练和测试。然而,人工图像不能增加最初捕获的视野。我们的语义分割数据集为40个对象类别提供像素级标签,相比之下,Cityscapes数据集[10]提供了30个对象类别。图6说明了主要类的分布。我们使用ENet[41]生成基线结果。通过使用分类交叉熵损失和Adam[29]优化器进行训练,我们为我们的数据集微调了他们的模型。我们选择Intersection over Union(IoU)metric[16]来报告基线结果 如表2所示。我们在这个测试集上获得了51:4的平均IoU。图7显示了测试集中鱼眼图像的分割示例结果。这四幅相机图像被处理得一模一样,但探索为每个相机定制模型会很有趣。该数据集还提供了实例分割标签,以探索全景分割模型[34]。
[47] Mennatullah Siam, Sara Elkerdawy, Martin Jagersand, and
Senthil Yogamani. Deep semantic segmentation for automated
driving: Taxonomy, roadmap and challenges. In 2017
IEEE 20th International Conference on Intelligent Transportation
Systems (ITSC), pages 1–8. IEEE, 2017. 6
[45] Alvaro S´aez, Luis M Bergasa, Eduardo Romeral, Elena
L´opez, Rafael Barea, and Rafael Sanz. CNN-based fisheye
image real-time semantic segmentation. In 2018 IEEE Intelligent
Vehicles Symposium (IV), pages 1039–1044. IEEE,
2018. 6
[12] Liuyuan Deng, Ming Yang, Yeqiang Qian, ChunxiangWang,
and Bing Wang. CNN based semantic segmentation for urban
traffic scenes using fisheye camera. In 2017 IEEE Intelligent
Vehicles Symposium (IV), pages 231–236. IEEE, 2017.
[41] Adam Paszke, Abhishek Chaurasia, Sangpil Kim, and Eugenio
Culurciello. ENet: A deep neural network architecture
for real-time semantic segmentation, 2016. 6, 7
[34] Qizhu Li, Anurag Arnab, and Philip HS Torr. Weaklyand
semi-supervised panoptic segmentation. In Proceedings
of the European Conference on Computer Vision (ECCV),
pages 102–118, 2018. 6
4.2 2DBBox检测
我们的2D对象检测数据集是通过从7个不同对象类别的实例分割标签中提取边界框来获得的,这些对象类别包括行人、车辆、自行车手和摩托车手。我们使用Faster R-CNN[43]和ResNet101[20]作为编码器。我们使用ImageNet[11]预先训练的权重初始化网络。通过对KITTI[18]和我们的目标检测数据集进行培训,我们对检测网络进行了微调。在以下情况下,2D目标检测的性能以平均精度(mAP)表示预测和地面真实边界框之间的IoU 0:5。我们的mAP得分为31,这明显低于其他数据集的准确度。这是意料之中的,因为边界框检测是鱼眼上的一项困难任务(图像边缘的物体方向与中心区域非常不同)。为了更好地量化这一点,我们对一个预先训练好的人际网络进行了测试,与我们的数据集训练值45分相比,mAP得分很低,仅为12分训练后的模型如图7所示。我们发现有必要明确地合并鱼眼几何,这是一个开放的研究问题。
[43] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.
Faster R-CNN: Towards real-time object detection with region
proposal networks. In Advances in Neural Information
Processing Systems, pages 91–99, 2015. 6, 7
[20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), pages 770–778, 2016. 6
[11] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,
and Li Fei-Fei. ImageNet: A large-scale hierarchical image
database. In Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), pages 248–
255. Ieee, 2009. 6
[18] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we
ready for Autonomous Driving? The KITTI Vision Benchmark
Suite. In Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), 2012. 6, 7

















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









