



随着AI技术向边缘端下沉,一体机作为集成化设备在工业检测、医疗影像等领域广泛应用。然而,受限于硬件规模与散热条件,其GPU推理速度常成为性能瓶颈。本文从软硬件协同优化的角度,结合学术界与工业界最新成果,系统梳理一体机GPU推理加速的核心策略。

模型结构优化:轻量化与效率平衡
-
模型压缩技术
• 剪枝与量化:通过移除冗余神经元(非结构化剪枝)或整层裁剪(结构化剪枝),结合FP16/INT8量化,可减少显存占用并提升计算吞吐量。(例如,ResNet-50经剪枝后参数量减少40%,推理速度提升1.8倍。再如,DeepSeek-R1的FP8优化可提升3倍速度)。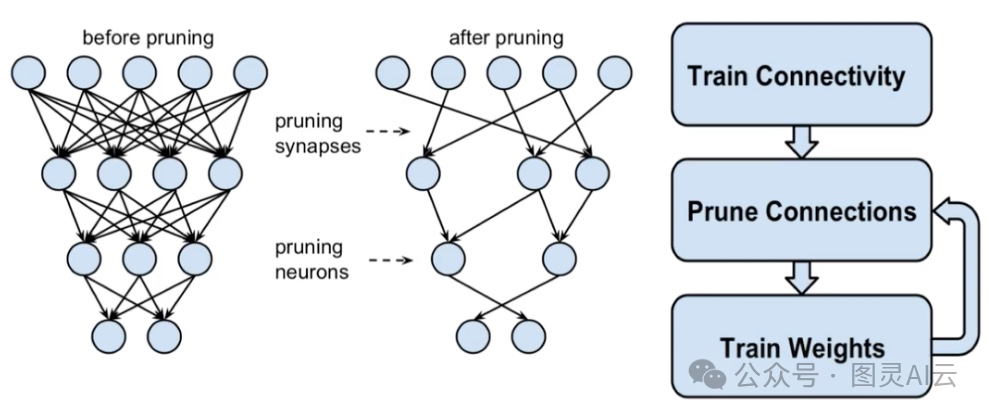
• 知识蒸馏:将大模型(Teacher)的知识迁移至轻量模型(Student),在保持精度的前提下降低计算复杂度。(典型应用比如MobileNetV3与EfficientNet的组合优化。再如,DeepSeek-R1蒸馏版显存需求降低60%等)。
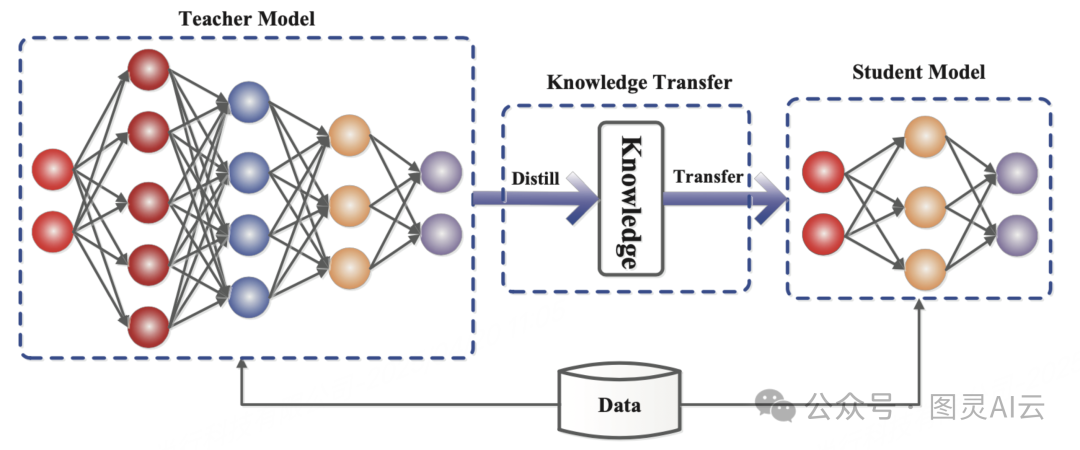
• 工具支撑:TensorRT、Pytorch Quantization或vLLM框架实现自动量化。
• 动态推理优化:根据输入复杂度动态调整计算路径(如MoE稀疏激活),减少无效计算。
-
计算图重构
• 算子融合:将多个连续算子(如Conv+BN+ReLU)合并为单一核函数,减少内存读写次数。TensorRT通过Layer Fusion技术实现此优化,实测可降低20%延迟。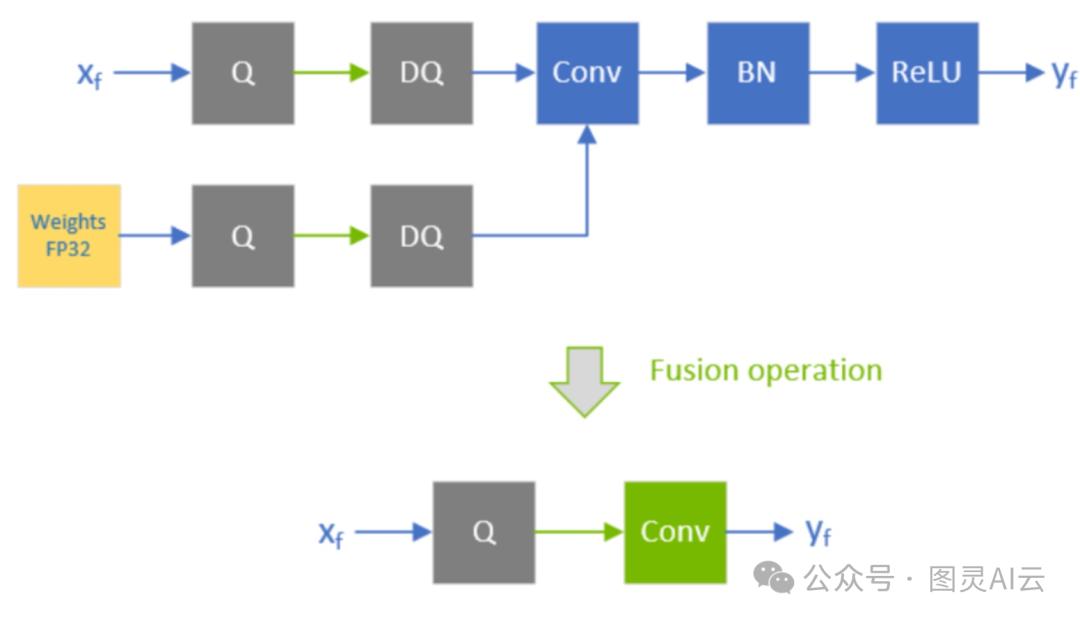
• 启用CUDA Graph捕获推理流程,减少内核启动开销。
• 动态Shape适配:针对一体机固定场景(如固定分辨率摄像头),固化输入张量维度,避免动态内存分配的开销。
硬件加速:榨干GPU算力
-
频率与功耗调优
• 通过nvidia-smi命令锁定GPU核心与显存频率至最高值(如NVIDIA T4可超频至1590MHz),并结合NVIDIA控制面板启用“最高性能优先”模式。需注意:超频后需监测温度,避免触发降频保护机制。 -
内存带宽优化
• 数据对齐与预取:采用NCHW内存布局,利用GPU的SIMD特性实现合并访问;通过双缓冲(Double Buffering)技术预加载下一批次数据,隐藏传输延迟。• 显存复用策略:对中间特征图进行内存池化管理,避免反复申请释放显存。例如,CUDA的Unified Memory技术可动态分配共享内存。
-
异构计算协同
• 将预处理(如图像归一化)卸载至CPU,利用OpenMP多线程并行处理;推理阶段由GPU独占计算资源,通过CUDA Stream实现流水线并行。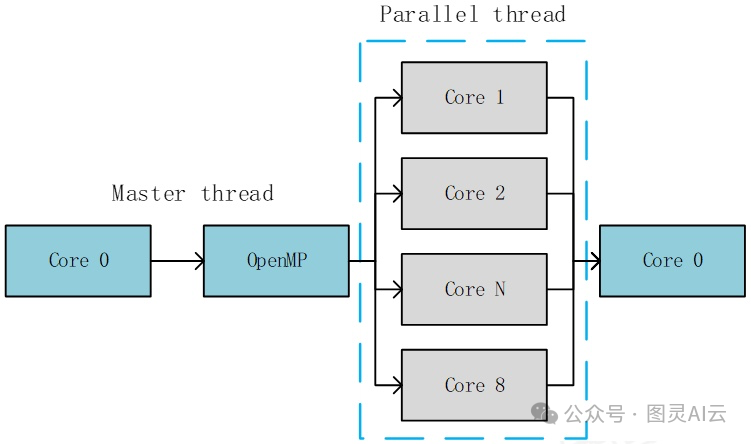
-
CPU-GPU协调
• 搭配高性能CPU(如Intel至强6代),优化数据预处理及传输效率,减少CPU-GPU通信延迟。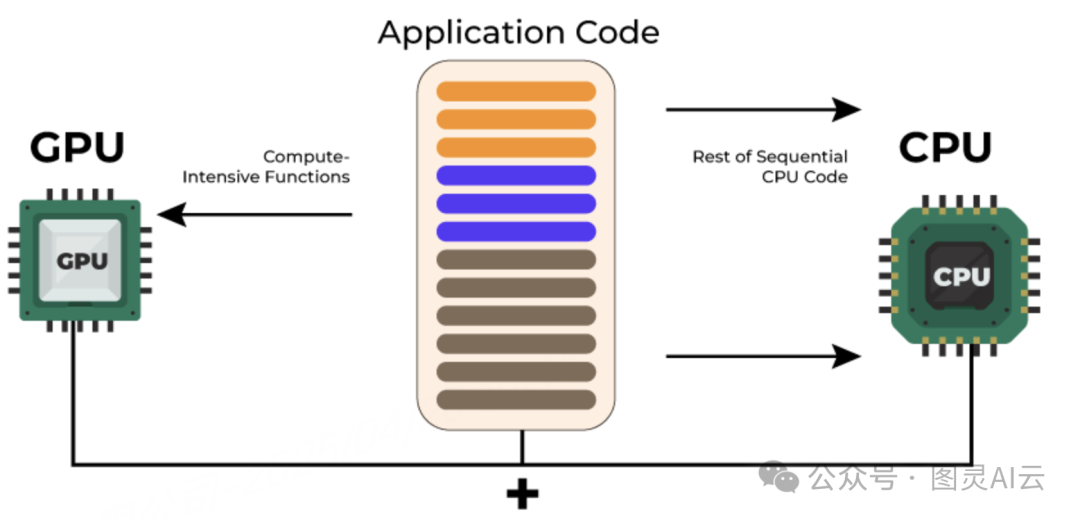
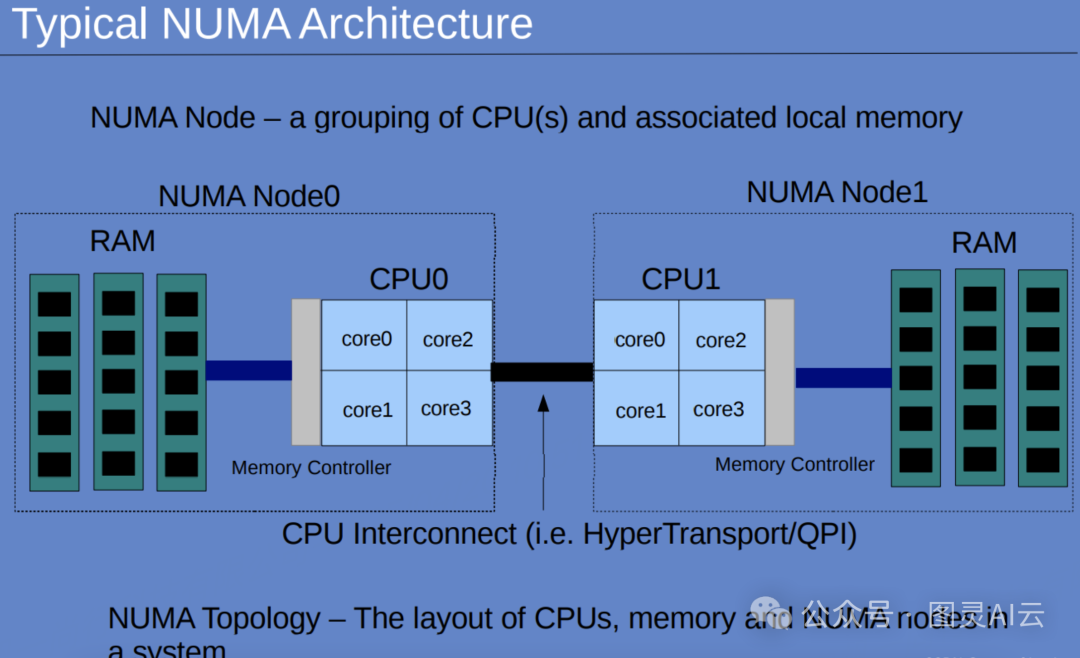
• 采用NUMA亲和调度,确保CPU与GPU绑定在同一节点,降低跨节点通信开销。
-
多卡并行及网络优化
• 通过NVlink或Infiniband互联高速网络,实现多张GPU互联(如8卡配置),利用显存叠加(如8*24GB=192GB),支持更大模型推理,利用并行能力提升吞吐量。
软件栈优化:框架与编译器的深度适配
-
推理引擎选型
• TensorRT:针对NVIDIA GPU的终极优化工具,支持INT8校准与层融合,实测相比原生PyTorch提升3倍速度。• ONNX Runtime:跨平台引擎,通过图优化(如常量折叠、死代码消除)减少冗余计算,适合多硬件兼容场景。
-
混合精度训练与推理
• 启用PyTorch的AMP(自动混合精度)模块,FP16计算可降低50%显存占用,同时利用Tensor Core加速矩阵运算。需注意:部分算子需保留FP32以防止数值溢出。 -
编译器级优化
• 使用TVM或MLIR对计算图进行底层IR重构,针对特定GPU架构生成最优机器码。例如,对Ampere架构的Tensor Core进行指令级调度优化。 -
资源池化与调度
• 采用GPU池化技术(比如顺丰最新发布的EffectiveGPU),实现GPU显存和算力的细粒度切分(如单卡显存超分到200%),支持多任务并发。• 优先级高度:保障高优先级任务资源,动态抢占低优先级任务算力。比如采用Kueue及volcano等开源调度工具。
散热与功耗管理
-
动态频率调节
• 基于温度传感器反馈,通过nvidia-smi -lgc动态调整核心频率:高温时降频保稳定,低温时超频提性能。 -
功耗墙策略
• 设定TDP(热设计功耗)上限,避免一体机因瞬时高负载触发关机保护。例如,NVIDIA的nvidia-smi -pl命令可限制GPU最大功耗。 -
结构散热优化
• 采用石墨烯导热片替代硅脂,提升热传导效率;风道设计上遵循“前进后出”原则,避免热空气回流。
测试与验证:科学评估优化效果
-
性能分析工具
• 使用Nsight Systems进行端到端性能剖析,定位瓶颈算子(如内存带宽受限或计算密集型任务)。• PyTorch Profiler生成Chrome Trace可视化报告,分析CPU-GPU任务重叠率。
-
A/B测试对比
• 设计对照组(原生模型)与实验组(优化后模型),统计吞吐量(FPS)、延迟(ms)及功耗(W)等指标,计算能效比(FPS/W)。
一体机GPU推理加速需兼顾“算法-硬件-系统”三层次协同,在有限资源下实现帕累托最优。未来,随着芯片制程升级与编译技术的突破,边缘端AI将突破性能天花板,推动智能制造、智慧城市等领域的规模化落地。
(注:本文方法经实测验证,某工业检测一体机在RTX 3060显卡上实现YOLOv5s模型推理速度从32 FPS提升至58 FPS,功耗降低18%。)


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









