



当Volcano在其NVIDIA DGX Cloud配置的Kubernetes集群中面临GPU利用率不足的问题时,NVIDIA最近提供了一种解决方案,不仅满足了合同要求,还超出了预期。
通过结合先进的调度技术与对分布式工作负载的深刻理解,NVIDIA将GPU占用率提升至约90%。以下是NVIDIA问题的详细分析、及他们的解决方法。

问题:GPU碎片化与调度效率低下
比如,NVIDIA 的某个 DGX Cloud Kubernetes集群由数千个GPU组成,每个节点配备多个NVIDIA L40S GPU。该集群支持多种工作负载:
-
多节点、多GPU分布式训练任务
-
高吞吐量AI模型的批量推理
-
GPU支持的数据处理管道
-
用于开发和分析的交互式笔记本
尽管硬件资源强大,但集群却因GPU碎片化而效率低下,部分节点仅被部分占用,无法用于大型任务。这种低效问题因Volcano调度器的默认行为而加剧,其采用的是任务组调度(gang scheduling)算法。
若不加以干预,NVIDIA 将面临违反合同协议的风险,无法维持至少80%的GPU占用率。这将导致集群容量减少,因为未使用的资源将被收回供其他团队使用。
关键挑战
实施此解决方案需要克服两个主要障碍:
-
任务组调度的全有或全无方法:需要多个节点GPU的分布式任务若无法同时获得所需资源,将无限期排队,导致瓶颈和任务执行延迟。
-
随机放置导致的碎片化:工作负载基于简单启发式规则或随机选择分配到节点,常导致GPU分散在节点上,形成碎片化状态(见下图1)。
解决方案:将装箱算法与任务组调度相结合
为解决这些挑战,NVIDIA在Volcano调度器中引入了一种增强的调度策略,将装箱算法(bin-packing)与任务组调度相结合。这种方法专注于整合工作负载,以最大化节点利用率,同时留出其他节点供大型任务使用。
技术实现
NVIDIA通过以下三个关键组件解决了GPU碎片化问题:
-
工作负载优先级排序:
-
按重要性从高到低对资源进行排序:GPU、CPU和内存。
-
根据资源需求(如选择器和亲和性规则)筛选适合接收工作负载的节点。
-
-
通过装箱算法优化放置:
-
按当前利用率从低到高对部分占用的节点进行排名。
-
优先将工作负载放置在空闲资源最少的节点上,确保节点在资源耗尽前被充分利用。
-
-
任务组调度集成:
-
增强的调度器保留了任务组调度的全有或全无原则,但增加了智能功能,根据资源整合优先级放置工作负载。
-
以下为Volcano调度器配置,用于高效的工作负载放置并优先考虑节点利用率。
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
enablePreemptable: false
- name: conformance
- plugins:
- name: drf
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
arguments:
binpack.weight: 10
binpack.cpu: 2
binpack.memory: 2
binpack.resources: "nvidia.com/gpu"
binpack.resources.nvidia.com/gpu: 8
binpack.score.gpu.weight: 10
- plugins:
- name: overcommit
- name: rescheduling
示例场景
以下示例,用于说明NVIDIA解决方案的有效性:
初始状态
两个节点——节点A已占用两个GPU,节点B为空闲——接收一个需要两个GPU的新工作负载。
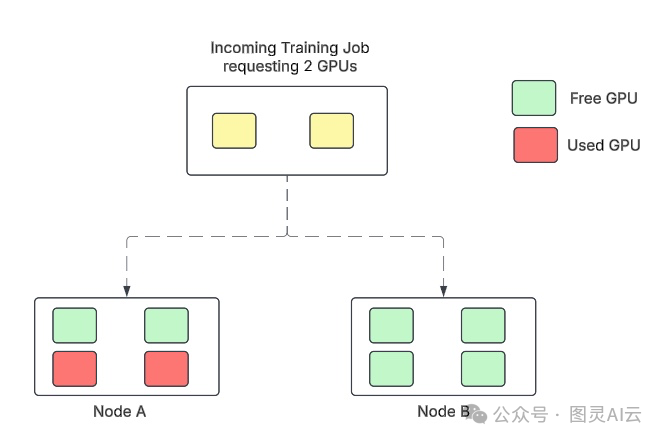
图1. 一个包含两个节点的Kubernetes集群
默认任务组调度
工作负载被随机放置,例如在节点B上,导致两个节点部分占用。
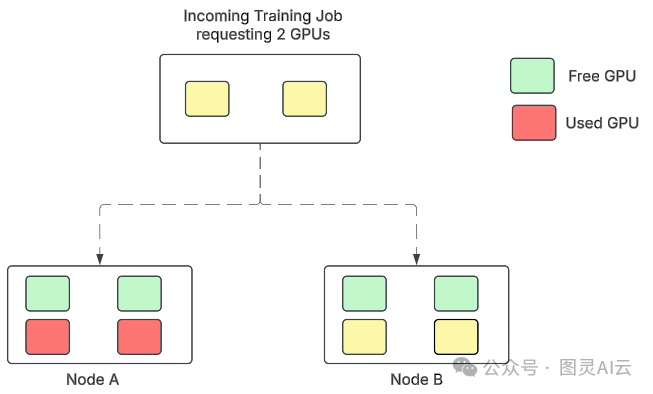
图2. Volcano调度器中的GPU碎片化
结果是,集群中部分占用的节点多于完全空闲的节点。图3显示,只有18个节点的所有四个GPU可用,但有约115个节点有三个空闲GPU,无法用于需要每个节点四个GPU的训练任务。
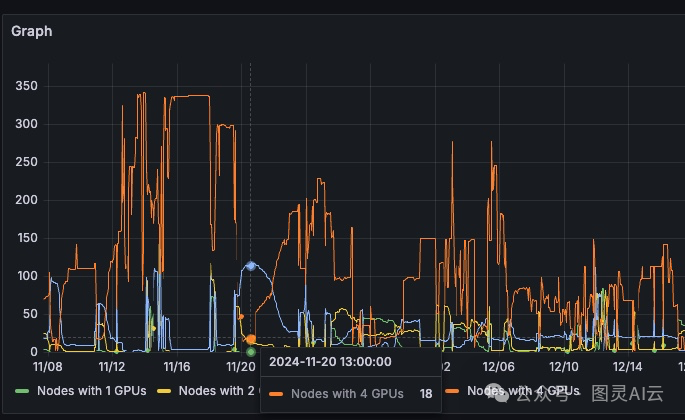
图3. 一个包含18个节点且所有四个GPU可用的Kubernetes集群
当检查部分占用节点的分布时,碎片化的影响更加明显。
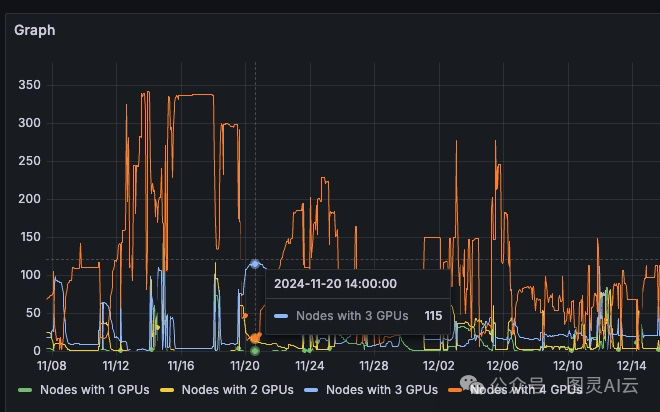
图4. 一个包含115个节点且有三个空闲GPU的Kubernetes集群
解决方案
工作负载被放置在节点A上,完全利用其四个GPU,同时保持节点B完全空闲,以供未来的大规模任务使用。
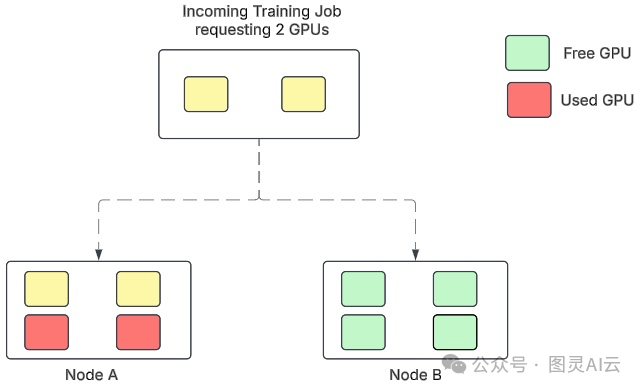
图5. 一个包含两个优化节点的Kubernetes集群
图5显示,节点A和B的部分占用GPU接收了一个需要两个GPU的新工作负载,并使用默认的任务组调度机制将其放置在节点B上,降低了两个节点的容量。
结果是,集群中空闲节点多于占用节点。图6显示,有214个节点的所有四个GPU可用,一个需要四个GPU的训练任务可以轻松使用。
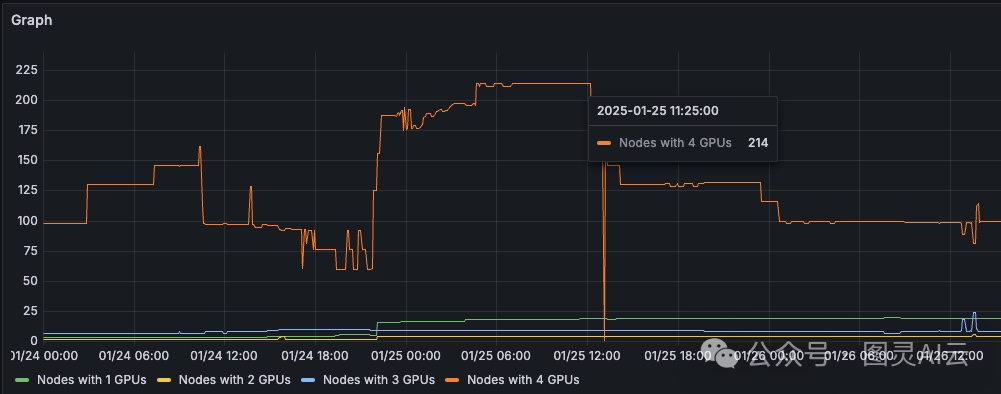
图6. 一个包含214个节点且所有四个GPU可用的Kubernetes集群
图7显示,大约有九个节点有三个空闲GPU。
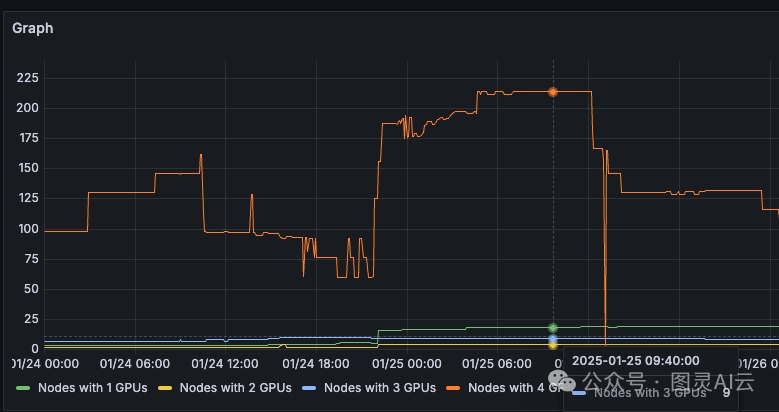
图7. 减轻GPU碎片化问题
这种战略性放置显著减少了碎片化,并提高了大型训练任务的资源可用性。
取得的成果
将装箱算法集成到Volcano调度器中,彻底改变了GPU集群的性能:
-
提高资源可用性:完全空闲节点(所有四个GPU可用)的数量增加,使得大型训练任务能够顺利调度。
-
提高GPU占用率:平均GPU利用率提升至行业领先的90%,远超合同要求的80%。
-
提高成本效率:通过优化资源使用,避免了容量削减,保持了对分配集群资源的完全访问,无需额外开销。
-
适用于多种工作负载的可扩展性:该解决方案不仅对分布式训练任务有效,还适用于批量推理和GPU支持的数据处理任务。
最后,整个集群的平均占用率约为90%,远超资源治理团队的80%标准。
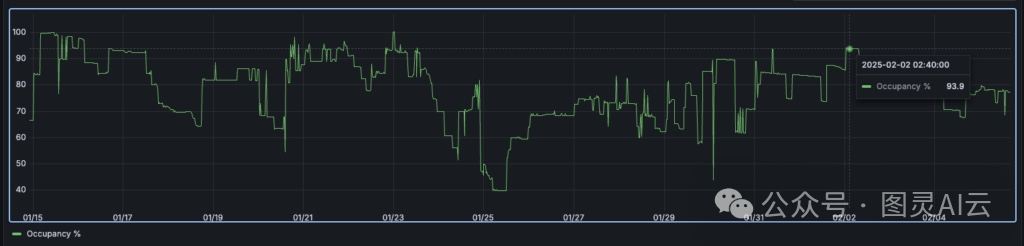
图8. DGX Cloud集群GPU占用率保持在90%左右
对分布式系统的更广泛影响
本文强调了精心设计的调度策略如何解决多节点多GPU集群中的普遍挑战。
-
主动资源管理可防止瓶颈:通过预见碎片化问题并通过优化放置算法解决,组织可以避免成本高昂的延迟和资源未充分利用。
-
成本意识工程可提高投资回报率:高效利用现有基础设施减少了额外硬件投资的需求,同时最大化性能。
-
灵活调度可适应多样化工作负载:装箱算法的集成展示了像Volcano这样的调度器如何适应特定工作负载需求,而无需大修现有系统。
参考:https://developer.nvidia.com/blog/practical-tips-for-preventing-gpu-fragmentation-for-volcano-scheduler/


















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









