



本文首发于公众号:机器感知

ControlNet++、Any2Point、ConsistencyDet、G-NeRF、GoMAvatar
Object-Conditioned Energy-Based Attention Map Alignment in Text-to-Image Diffusion Models

Text-to-image diffusion models have shown great success in generating high-quality text-guided images. Yet, these models may still fail to semantically align generated images with the provided text prompts, leading to problems like incorrect attribute binding and/or catastrophic object neglect. Given the pervasive object-oriented structure underlying text prompts, we introduce a novel object-conditioned Energy-Based Attention Map Alignment (EBAMA) method to address the aforementioned problems. We show that an object-centric attribute binding loss naturally emerges by approximately maximizing the log-likelihood of a $z$-parameterized energy-based model with the help of the negative sampling technique. We further propose an object-centric intensity regularizer to prevent excessive shifts of objects attention towards their attributes. Extensive qualitative and quantitative experiments, including human evaluation, on several challenging benchmarks demonstrate the superior perform......
JetMoE: Reaching Llama2 Performance with 0.1M Dollars
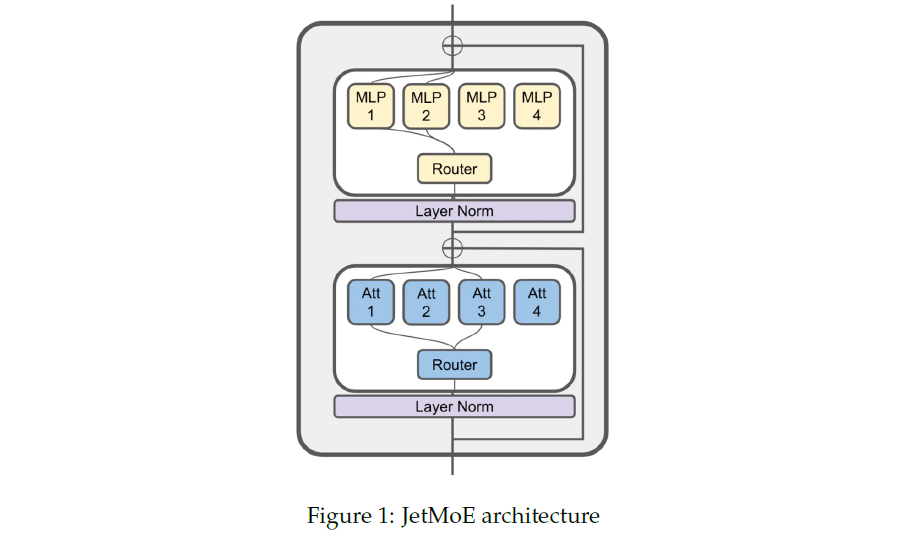
Large Language Models (LLMs) have achieved remarkable results, but their increasing resource demand has become a major obstacle to the development of powerful and accessible super-human intelligence. This report introduces JetMoE-8B, a new LLM trained with less than $0.1 million, using 1.25T tokens from carefully mixed open-source corpora and 30,000 H100 GPU hours. Despite its low cost, the JetMoE-8B demonstrates impressive performance, with JetMoE-8B outperforming the Llama2-7B model and JetMoE-8B-Chat surpassing the Llama2-13B-Chat model. These results suggest that LLM training can be much more cost-effective than generally thought. JetMoE-8B is based on an efficient Sparsely-gated Mixture-of-Experts (SMoE) architecture, composed of attention and feedforward experts. Both layers are sparsely activated, allowing JetMoE-8B to have 8B parameters while only activating 2B for each input token, reducing inference computation by about 70% compared to Llama2-7B. Moreover, JetMoE-8B......
G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images

Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through......
CAT: Contrastive Adapter Training for Personalized Image Generation
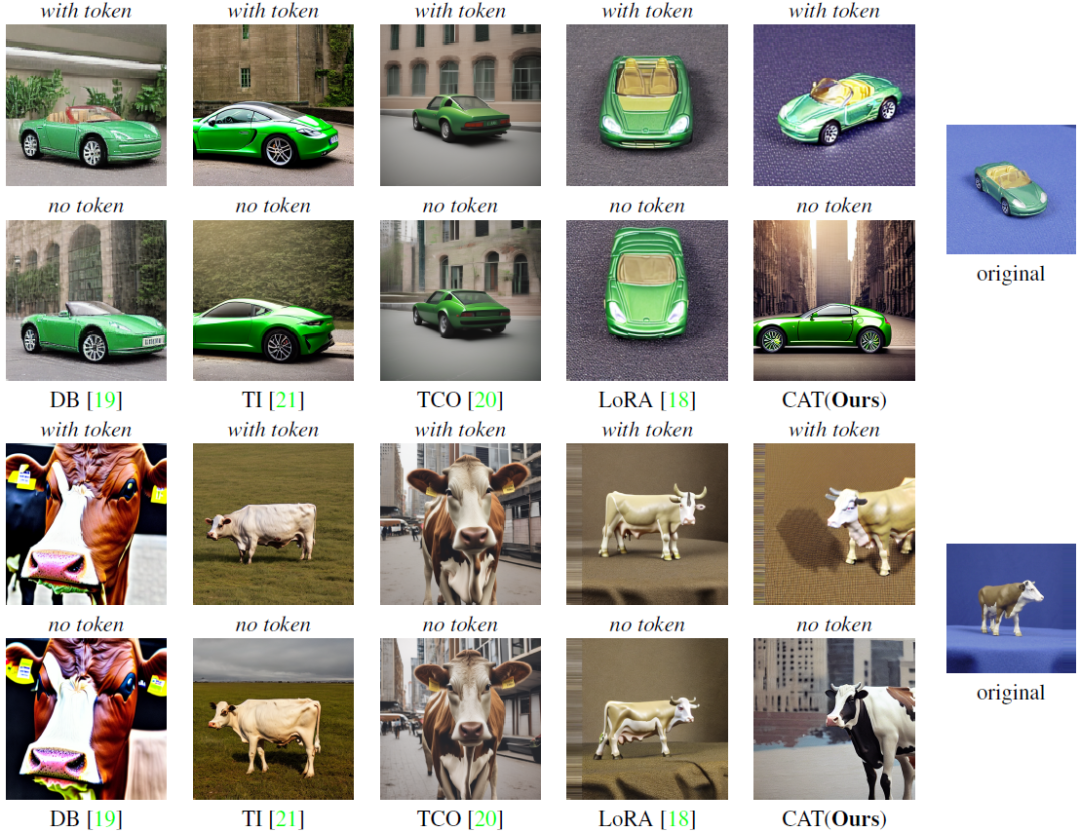
The emergence of various adapters, including Low-Rank Adaptation (LoRA) applied from the field of natural language processing, has allowed diffusion models to personalize image generation at a low cost. However, due to the various challenges including limited datasets and shortage of regularization and computation resources, adapter training often results in unsatisfactory outcomes, leading to the corruption of the backbone model's prior knowledge. One of the well known phenomena is the loss of diversity in object generation, especially within the same class which leads to generating almost identical objects with minor variations. This poses challenges in generation capabilities. To solve this issue, we present Contrastive Adapter Training (CAT), a simple yet effective strategy to enhance adapter training through the application of CAT loss. Our approach facilitates the preservation of the base model's original knowledge when the model initiates adapters. Furthermore, we intr......
ConsistencyDet: Robust Object Detector with Denoising Paradigm of Consistency Model
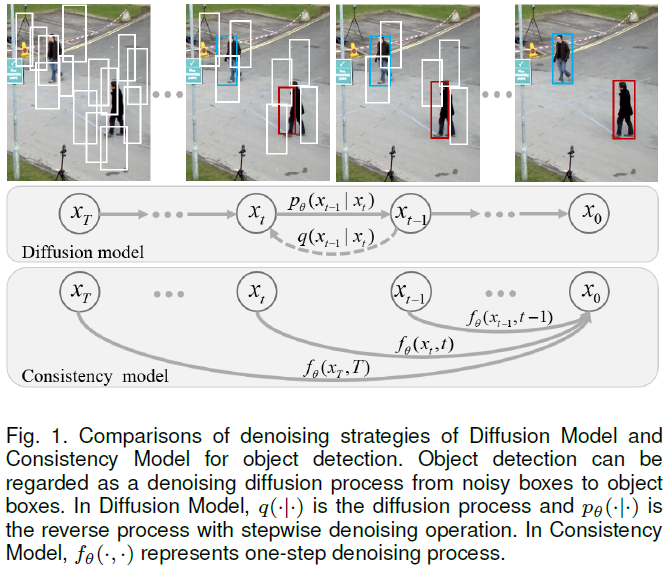
Object detection, a quintessential task in the realm of perceptual computing, can be tackled using a generative methodology. In the present study, we introduce a novel framework designed to articulate object detection as a denoising diffusion process, which operates on perturbed bounding boxes of annotated entities. This framework, termed ConsistencyDet, leverages an innovative denoising concept known as the Consistency Model. The hallmark of this model is its self-consistency feature, which empowers the model to map distorted information from any temporal stage back to its pristine state, thereby realizing a ``one-step denoising'' mechanism. Such an attribute markedly elevates the operational efficiency of the model, setting it apart from the conventional Diffusion Model. Throughout the training phase, ConsistencyDet initiates the diffusion sequence with noise-infused boxes derived from the ground-truth annotations and conditions the model to perform the denoising task. Subs......
PRAM: Place Recognition Anywhere Model for Efficient Visual Localization
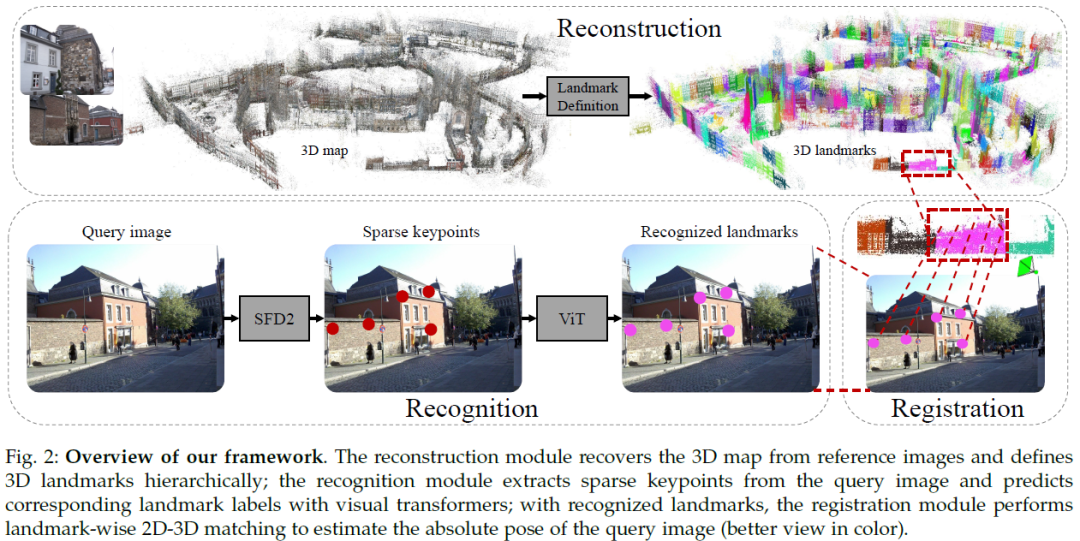
Humans localize themselves efficiently in known environments by first recognizing landmarks defined on certain objects and their spatial relationships, and then verifying the location by aligning detailed structures of recognized objects with those in the memory. Inspired by this, we propose the place recognition anywhere model (PRAM) to perform visual localization as efficiently as humans do. PRAM consists of two main components - recognition and registration. In detail, first of all, a self-supervised map-centric landmark definition strategy is adopted, making places in either indoor or outdoor scenes act as unique landmarks. Then, sparse keypoints extracted from images, are utilized as the input to a transformer-based deep neural network for landmark recognition; these keypoints enable PRAM to recognize hundreds of landmarks with high time and memory efficiency. Keypoints along with recognized landmark labels are further used for registration between query images and the 3......
Towards Faster Training of Diffusion Models: An Inspiration of A Consistency Phenomenon

Diffusion models (DMs) are a powerful generative framework that have attracted significant attention in recent years. However, the high computational cost of training DMs limits their practical applications. In this paper, we start with a consistency phenomenon of DMs: we observe that DMs with different initializations or even different architectures can produce very similar outputs given the same noise inputs, which is rare in other generative models. We attribute this phenomenon to two factors: (1) the learning difficulty of DMs is lower when the noise-prediction diffusion model approaches the upper bound of the timestep (the input becomes pure noise), where the structural information of the output is usually generated; and (2) the loss landscape of DMs is highly smooth, which implies that the model tends to converge to similar local minima and exhibit similar behavior patterns. This finding not only reveals the stability of DMs, but also inspires us to devise two strategie......
Taming Stable Diffusion for Text to 360° Panorama Image Generation

Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https:/......
ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
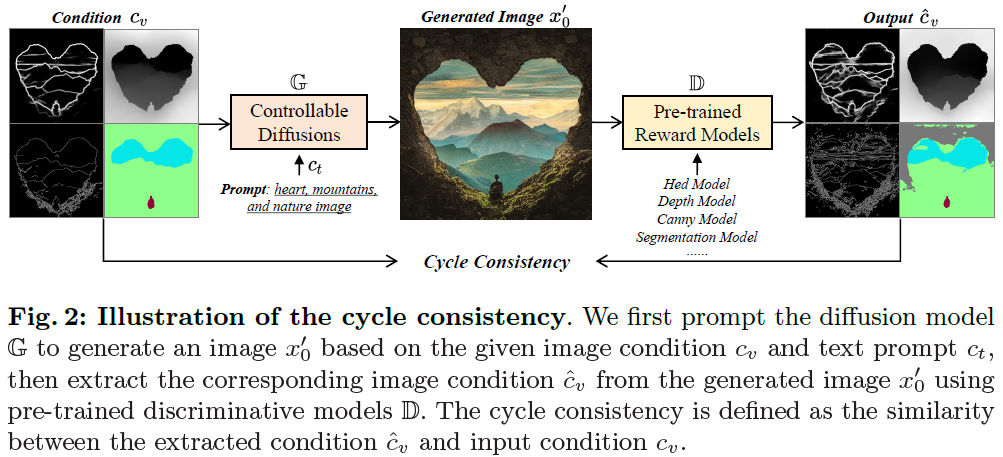
To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time ......
Any2Point: Empowering Any-modality Large Models for Efficient 3D Understanding
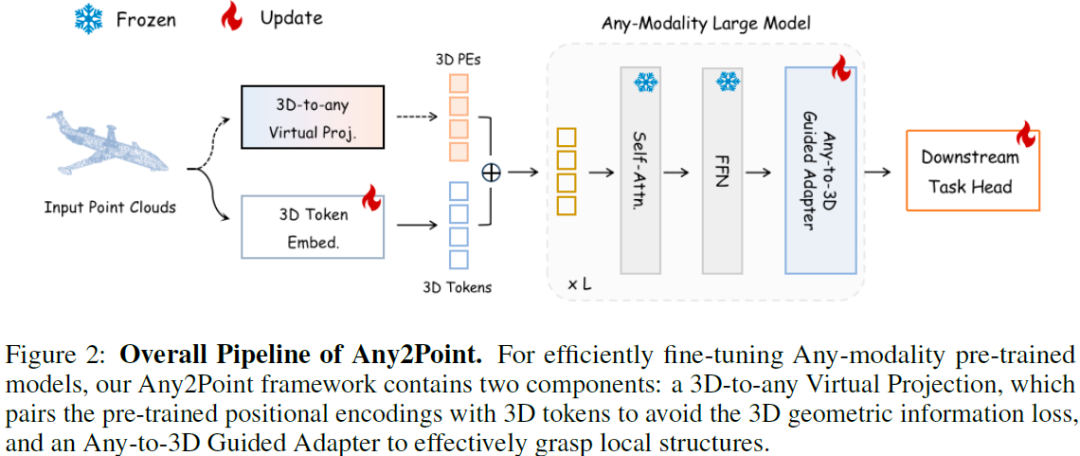
Large foundation models have recently emerged as a prominent focus of interest, attaining superior performance in widespread scenarios. Due to the scarcity of 3D data, many efforts have been made to adapt pre-trained transformers from vision to 3D domains. However, such 2D-to-3D approaches are still limited, due to the potential loss of spatial geometries and high computation cost. More importantly, their frameworks are mainly designed for 2D models, lacking a general any-to-3D paradigm. In this paper, we introduce Any2Point, a parameter-efficient method to empower any-modality large models (vision, language, audio) for 3D understanding. Given a frozen transformer from any source modality, we propose a 3D-to-any (1D or 2D) virtual projection strategy that correlates the input 3D points to the original 1D or 2D positions within the source modality. This mechanism enables us to assign each 3D token with a positional encoding paired with the pre-trained model, which avoids 3D ge......
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
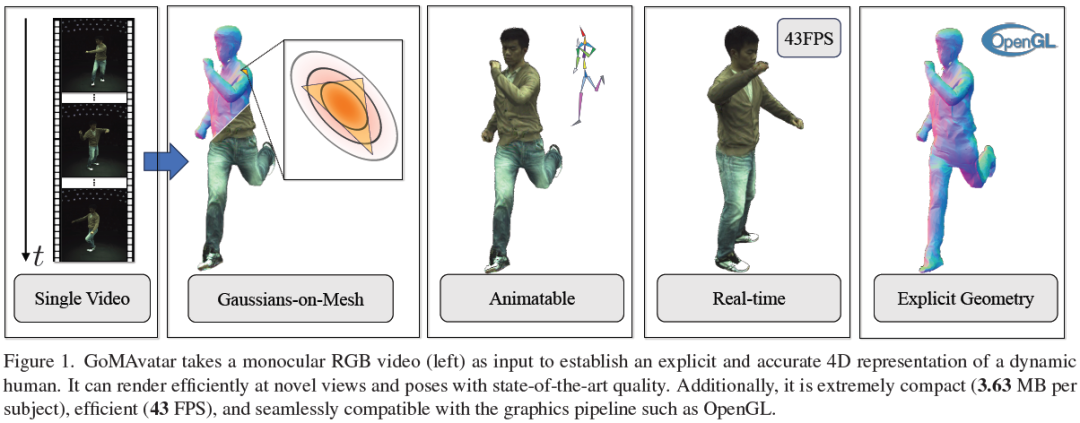
We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject). ......
Connecting NeRFs, Images, and Text
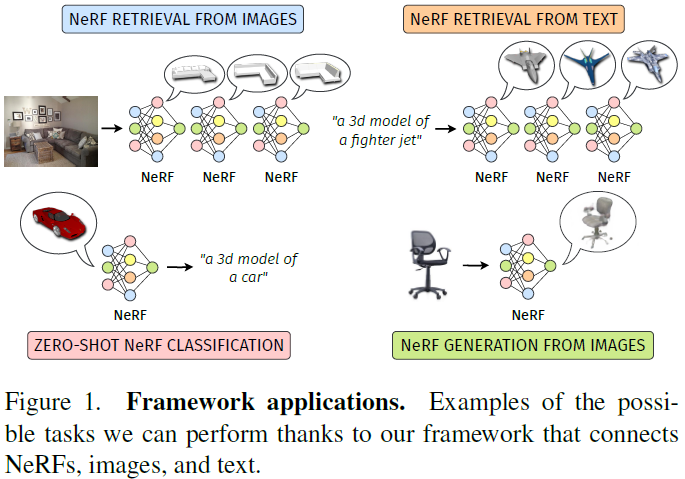
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text. ......


















 1715
1715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









