







pytorch学习笔记(一)
写在前面的话: 要做图像处理,肯定得用到深度学习框架,会一点tf,但是感觉是真的麻烦,所以先选择了pytorch进行学习,最苦恼的搭环境也比较容易。都用于自我复习用,非教程!!!
一. GPU与CPU环境搭建
1. Anaconda——最简单的配置软件
- 下载后是
python3.7版本的,自建了一个3.6的用于学习使用(目前对各种库友好一些) - CPU版本直接在软件里装,或者conda安装即可
2. GPU版本
- 搜索
cuda download,自选版本,windows就选最新的。
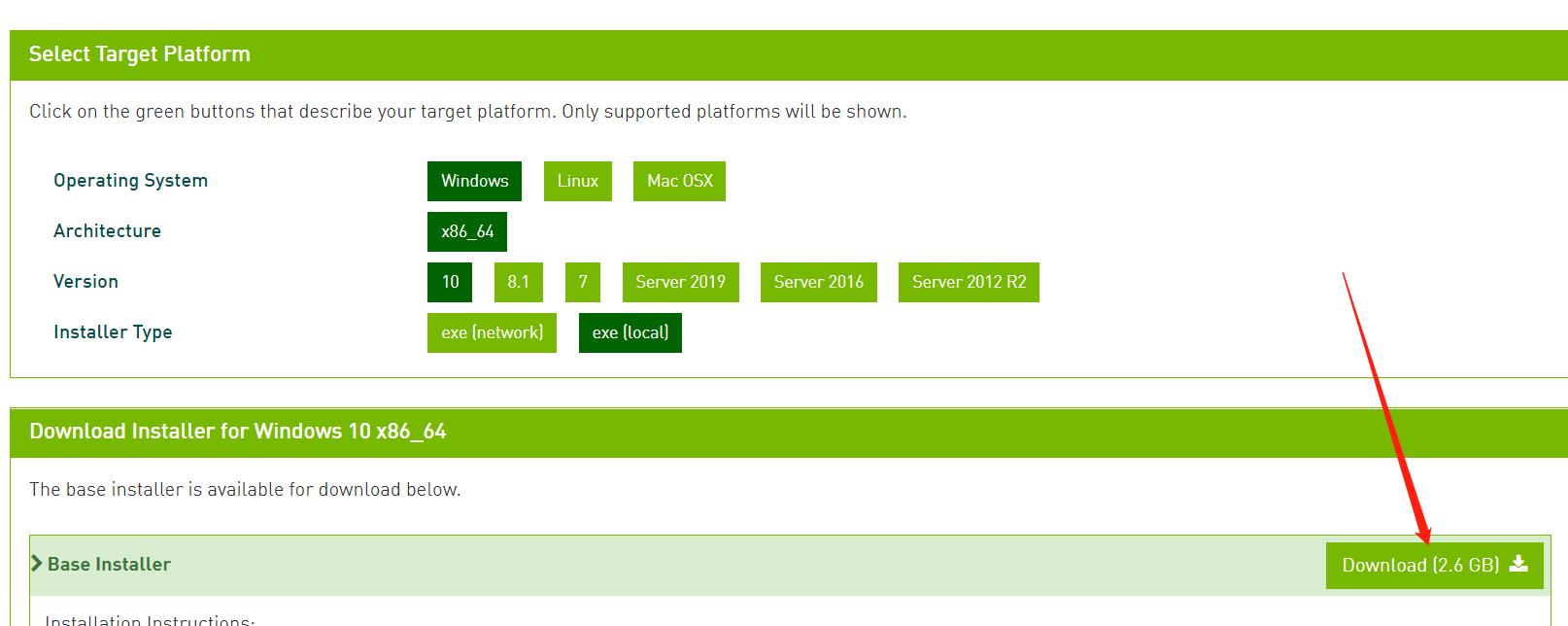
-
安装后在命令窗口输入
nvcc -V可查看其版本,如果报错配置下环境变量 -
搜索
pytorch,去官网选择自己python的对应版本,复制相应指令下载
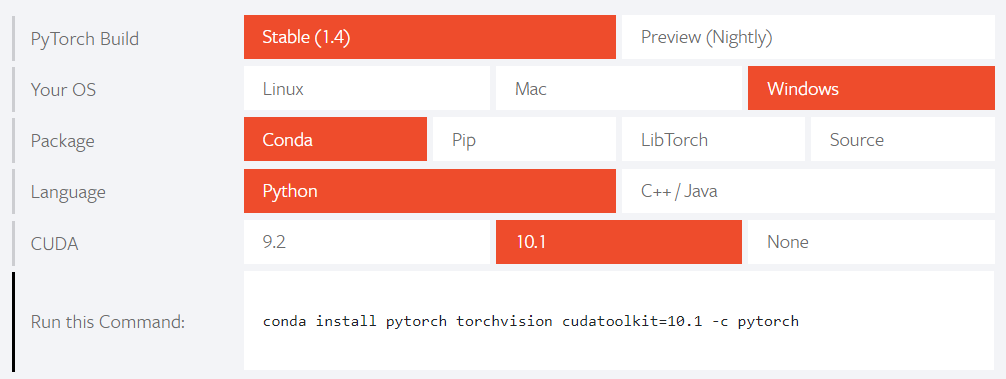
成功后到相应虚拟环境里就可以
import sys
print(sys.executable)
import torch
print(torch.__version__)
print('gpu: ', torch.cuda.is_available())

Got it! 这说明GPU版本可用了
二. visdom可视化安装
1. pip 安装
pip install visdom
2. 源码安装
源码点我 随便下载到自定义的文件夹下并解压,打开cmd窗口。并cd到相应路径(提前激活相应的虚拟环境,也就是要安装的环境内)。不懂的话 点我。到了相应路(一般是在visdom-master下),输入
pip intall -e .
很容易安装成功…
然后输入
cd ../..
相当于到了下载的根目录下
3. 启动服务
其实本质上是一个服务,需要下载一些配置文件。
python -m visdom.server
一般来说会卡住不动了,显示需要等待,然后没有然后了…
解决方法: 使用anaconda安裝visdom及疑難解決 下载后整个文件夹覆盖掉原文件夹就行,再重复上面指令就ok了。
三. 一些个人笔记(慢慢积累…)
写在前面的话: 如有错误,欢迎指正,不胜感激!
- 将数据写入
GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else "cpu")
data.to(device)
Regularization泛化 (L1,L2正则化) 同dropout层类似,防止过拟合,是预测边界更平滑。- 需要梯度信息时需在写入数据时加入
requires_grad=True,如
w1 = torch.randn(200, 784, requires_grad=True)
- 动量
monument,可以加快拟合,并可能找到全局最优解。 CrossEntropyLoss操作后不再需要进行softmax操作,因为已经进行过了- 使用
torchvision中的mnist数据集的分类识别 - 卷积神经网络参数的计算
四. 参考资料
[1] visdom配置
[2] 使用anaconda安裝visdom及疑難解決

















 8509
8509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









