



基于近似自动机的分布式语义过滤模型用于异构多传感器网络
摘要
越来越多的传感器网络被部署用于收集各种应用的信息。然而,这些传感器网络彼此孤立。同时,处理大规模数据流是推式模式系统的瓶颈。为了在异构传感器网络数据中匹配海量事件流,我们提出了近似语义因子(ASR),并在此基础上进一步提出了异构多传感器网络近似语义匹配模型(ASMMN)。此外,还提出了评估模式算法。
ASMMN能够有效解决语义耦合和速度匹配问题。仿真结果表明,所提出的模型可以加速匹配过程,并减少事件流中间状态的内存消耗。同时,该模型具有良好的可扩展性,可广泛应用于异构推送模式传感器网络和物联网(IoT)。
关键词 :发布/订阅系统;多传感器网络;数据集成;异构监控数据;XML;中间件。
1 引言
随着物联网(IoT)和传感器网络(刘等人,2006;王和肖,2006)的快速发展,大规模异构传感器网络正被部署用于收集多种应用领域的信息。从传感器网络中收集数据不仅在监测污染(如PM2.5监测)方面变得日益重要,也在一些军事行动中发挥着作用(王等人,2013)。如何从海量信息资源中快速、准确地获取和处理实时信息,成为一项首要任务。
作为大规模分布式计算的基础,发布/订阅系统发挥着重要作用(丁等人,2013)。发布/订阅系统基于异步通信、多对多、动态即插即用以及松散耦合通信(曹等人,2015;尤斯特和费尔贝尔,2003),引起了产业界和学术界的广泛关注。同时,它也被广泛应用于超大型网络、移动系统和无线传感器网络中。
在以存储设备为载体的这些数据中,半结构化数据已成为大数据背景下信息交互与存储的标准。因此,处理异构数据的通信中间件是非结构化与半结构化数据处理中的关键技术之一,如方等人(2003)所述。
发布/订阅系统通常由新闻发布者、订阅者和匹配模型组成,其中事件是发布者与订阅者之间的网络数据信息。发布者将消息发送至通信中间件的事件代理,而订阅者通过事件代理代码接收消息并获得反馈(克西洛梅诺斯等人,2012)。近年来,大数据的发展使得能够实时处理复杂异构数据的移动终端越来越普及(博卡等人,2012)。
发布/订阅系统通过消息的发布者和订阅者,可在时间、空间和控制流上实现完全解耦,能够很好地满足大规模、高动态网络的需求。然而,在异构网络广泛应用于多传感器网络的背景下,我们提出了一种面向异构多传感器网络的近似语义匹配模型,称为ASMMN。该模型能够有效提高事件流匹配中的匹配度,并降低事件流中间状态的内存消耗。
在近期关于发布/订阅的研究中,事件通知以由应用程序生成的消息形式出现。消息通常由一个包含消息特定信息的通用格式和包含用户特定信息的负载数据组成。典型的头部字段包括消息标识符、发布者、优先级和过期时间,这些可由系统或纯服务解释为面向消费者的信息。
IBM MQSeries(吴等人,2014)和Oracle高级队列不对负载数据的类型做任何假设,并将其视为不透明的字节数组。CORBA通知服务提供了一组消息类型,例如半结构化文本和XML消息(阿尔蒂内尔和富兰克林,2000;黄等人,2008)。近年来,已提出高效的可扩展XML流算法用于发布/订阅系统中的数据过滤(法布雷等人,2001)。
刁等人(2002)提出了YFilter,该方法为过滤构建NFA自动机并合并相应的XPath表达式。YFilter涉及大量中间状态,占用较多内存空间并降低过滤效率。陈等人(2002)提出了XTrie,它是YFilter的扩展,在接收到数据流后解析事件序列。然而,XTrie仍无法高效处理堆栈运行元素。
古普塔和苏奇乌(2003)提出了XPush模型。尽管通过确定性自动机的表达解决了上述问题,但代价是空间索引级别因确定性表达而增加。金等人(2007)在POSfilter中使用后缀共享NFA自动机。它通过构造后缀自动机来缩短过滤时间,从而提高处理效率。
能够处理自然树结构更多数据模型的树自动机变得流行起来。XEBT(高等人,2005)基于树自动机,无需额外的中间状态。查询通过自顶向下和自底向上的组合进行处理。XEBT降低了空间消耗成本。此外,在有限条件下自动机构造需要不断增加的时间,这对实时数据流处理而言并不理想。
XTAfilter(托马斯,2007)也基于树自动机,但在运行时无法减少系统的灵活状态,且谓词匹配必须在结构匹配之后进行。然而,这些系统研究的基础是时间、空间和控制流的耦合。它们无法解决网络爆炸式增长中异构事件流匹配所引发的语义问题。针对上述问题,本文提出了ASMMN模型。
2 系统模型
在本节中,我们将给出一个称为近似语义因子(ASR)的定义。然后,我们将提出基于近似语义因子的异构多传感器网络近似语义匹配模型。此外,还将提供评估模式算法和执行过程。
2.1 近似语义因子
解决语义匹配问题的关键技术是将XML数据与查询事件流中包含的语义信息进行匹配。通常我们需要建立事件流索引。此外,根据已设置的排序条件,还需要通过解析器匹配并反馈过滤后的信息。目前,常用的查询事件有XQL、XSLT、XQuery和XPath。因此,我们将详细介绍能够解决语义耦合问题的近似语义模型。
具有强大表达能力的通信中间件必须支持异构复杂事件和不同语义事件。这不仅关系到发布者能否清晰地描述事件以及系统能否完整解析事件的形式意义,还关系到通信中间件在事件匹配上的准确性。对不同结构数据的匹配结果不仅要能从字面上完成用户感兴趣的信息匹配,还需具备一定的语义层面的理解和解析能力。
同时,使匹配结果不遗漏用户感兴趣的重要信息,并排除大量无关信息。此外,推动多传感器网络通信中间件与物联网语义智能的发展。因此,引入近似语义因子并设计自动机的整体架构如图1所示。
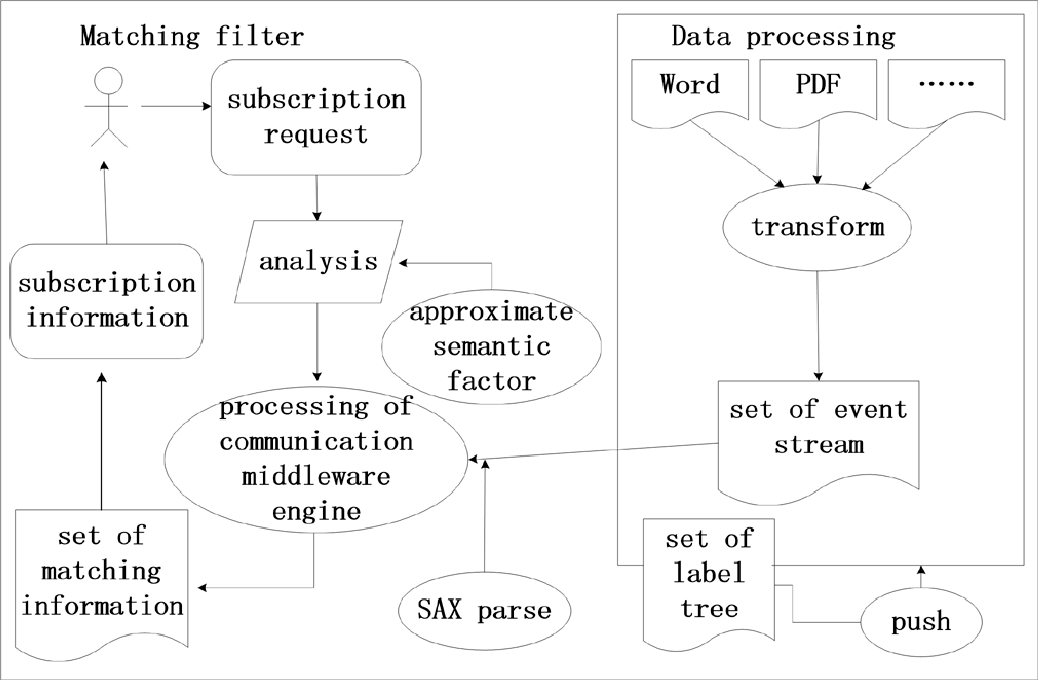
近似语义因子在事件流匹配过程中去除了不必要的和无关的信息。因此,其定义如下:
-
事件流模型
:发布者发送给通信中间件的消息是事件,事件是一组属性。我们将其定义为
$$
\text{Event} = {T_1, T_2, …, T_n},\quad n \geq 1
$$
$$
T \in \Delta,\quad \lambda(v) = (\text{lab}(v), \text{val}(v)),\quad E \cup \text{Trait}
$$
我们使用三元组{类型, 名称, 值}来表示一个属性,其中类型是预先确定的,名称是一个字符串。同时,该属性的值应在属性的数据类型范围内,发布者限制其范围也是可以接受的。
XML具有结构和语义信息,具备自身优势,已取代HTML。越来越多的传感器监控信息通过XML格式进行传输和交换。即使在无线传感器网络等资源受限环境中,仍存在多种类XML语言用于描述数据,例如传感器描述语言(SensorML)、电子设备描述语言(EDDL)、设备间M2M通信协议(M2MXML)、跨范围仪器组(IRIG)、应急数据交换语言(EXDL)以及拉特帕特TeX(LATEX,最流行的出版工具)等。
此外,XML能够在不同数据库(如Oracle、Microsoft SQL Server和SYBASE)之间进行数据交换。由于XML及其扩展能够描述大多数传感器语言,我们将采用XML的超集来统一我们原型中传感器网络的各种传感器数据。
在推送模式无线传感器网络中,实时数据流的处理一直是一个需要解决的关键问题。此类查询以子代轴“//”开头,通常为路径的一部分。例如图2中的Q1,其查询结果用完整路径表达相同的含义,如
/store/milk/commodity/name
和
/store/fruits/commodity/name
。

如果频繁使用部分匹配谓词路径,则后缀共享的效率将优于前缀共享。用于处理和发布实时信息的发布/订阅思想模型以XML子集或超集的形式提供,以高效匹配实时数据流。在XML文档预处理阶段的数据匹配中,我们提出了一种用于收集XML路径的相似度计算方法,该路径通常被视为标签序列。路径相似度计算是XML文档相似性的关键问题。
-
订阅模型 :订阅请求是表达订阅者对某些事件代理感兴趣的信息。订阅信息是一组约束,可以表示为
$$
\text{Sub} = {C_1, C_2, …, C_n},\quad n \geq 1
$$
约束可描述为四元组{类型, 名称, 操作符, 值},其中操作符包括子串、前缀、后缀以及一些计算操作符。该操作符也可以是自定义的。 -
事件匹配 :对于任何订阅中的约束 $ C $,如果事件的属性 $ T $ 能够与该约束匹配,则认为事件与订阅匹配。然而,在事件中,若不存在能与订阅信息的属性约束协同工作的属性,则认为事件与订阅不匹配。
-
近似语义自动机 :表示为一个四元组($ A, V, Q, F $)。
其中与有限自动机相同的表达分别为元素集 $ V $、状态集 $ Q $ 和终止状态集 $ F $。$ \Delta $ 是自动机的状态转移函数,而转移自动机 $ A $ 的规则 $ Q^* \times V \to Q $ 在树 $ t $ 中具有标签映射:
$$
\lambda: \text{Dom}(t) \to Q
$$
它必须符合以下陈述:对于任意节点 $ v \in \text{Dom}(t) $,其中节点 $ v $ 包含 $ n $ 个代码 $ v_1, …, v_n $,公式
$$
(\lambda(v), \text{lab}(v)) \in \Delta(\lambda(v), v_i)
$$
始终成立。
2.2 ASMMN模型
在ASMMN架构中,处理事件流的过滤匹配由数据预处理和过滤匹配模块组成。它能够从手机、iPad以及个人电脑等移动智能终端收集网络信息,并将收集到的信息转换为XML格式。数据流的解析事件可通过SAX(Martens, 2007)解析器完成。
SAX解析器的输出不是文档树,而是传输网络数据时的事件流,包括
startDocument()
、
startElement()
、
text()
、
endElement()
、
endDocument()
等。一段网络数据如图3所示。

通过SAX解析器处理,该数据片段可以获得上述文档的结果如下:开始元素(学校)、开始元素(学生)、开始元素(姓名)、文本(小华)、结束元素(姓名)、结束元素(学生)和结束元素(学校)。通信中间件处理模型的实际输入是由SAX解析器已解析的事件流。此类事件流的匹配系统结构通常如图4所示。
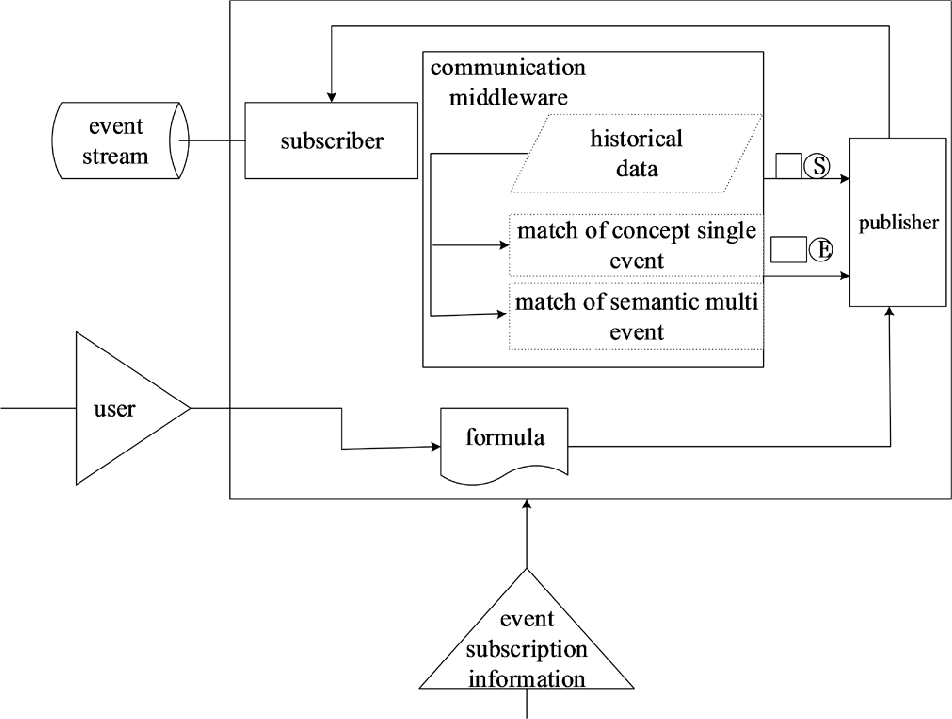
经过解析过程后,我们可以获得事件流集合。数据处理模块用于处理在数据模型中表示为发布信息的事件,同时将订阅请求解析为路径表达式,并通过过滤引擎实现过滤算法,从而完成发布信息与订阅请求之间的匹配。
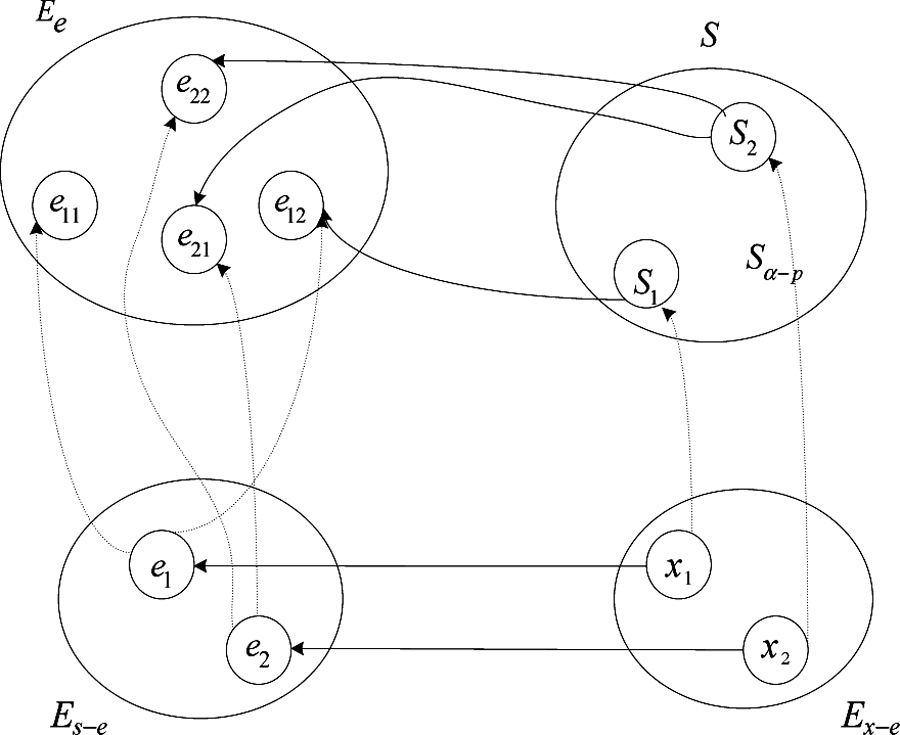
为了赋予ASMMN智能性,我们需要解耦语义内容。具体的近似语义匹配耦合模型如图5所示。其中,S表示通信中间件中接收器的事件。Sα–p表示具有近似语义的接收到的事件。Sx–p表示精确接收事件。Ee表示可扩展事件。ES–e表示具有可扩展性语义的接收到的事件。
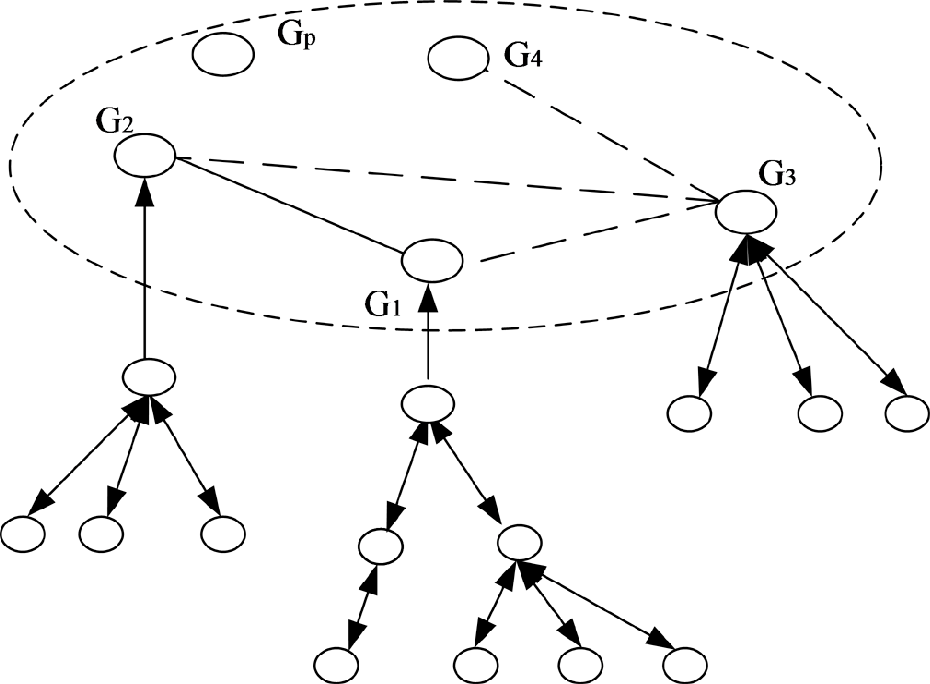
拓扑结构分为两层:覆盖层和子网络层。如图6所示,覆盖层由传感器网关G1、G2和Gp组成。多传感器网络布置在关键传感器网关上。子网络层无环路,呈分层嵌套结构,其根节点为传感器网关。每个网络由一个父网络和若干子网络节点构成。该架构支持在所有网络路径中传输信息,仅选择一次路径,以避免网络流量大幅增加。
2.3 评估模式算法
通过描述实现近似语义匹配耦合的模型,我们可以完成事件流的匹配算法。该算法主要引入了通信中的语义信息中间件。它完全实现了网络数据的实时输入,并处理了数据的网络异构性问题。评估模式算法的伪代码如图7所示。

我们提出了评估模式算法,该算法可通过主解析函数
startElement()
、
endElement()
解析发布者的信息,并将获取的实时事件流与动态网络异构数据进行匹配。利用自动机技术和自底向上方法处理匹配过程,该算法将状态集存储到集合中。
上述评估模式算法实现了属于无序树自动机的每个代码及其状态的转换,从而得到状态集。因此,该状态集与解析实时网络数据后获得的事件流相匹配,并完成了松耦合近似语义的高效过滤匹配。
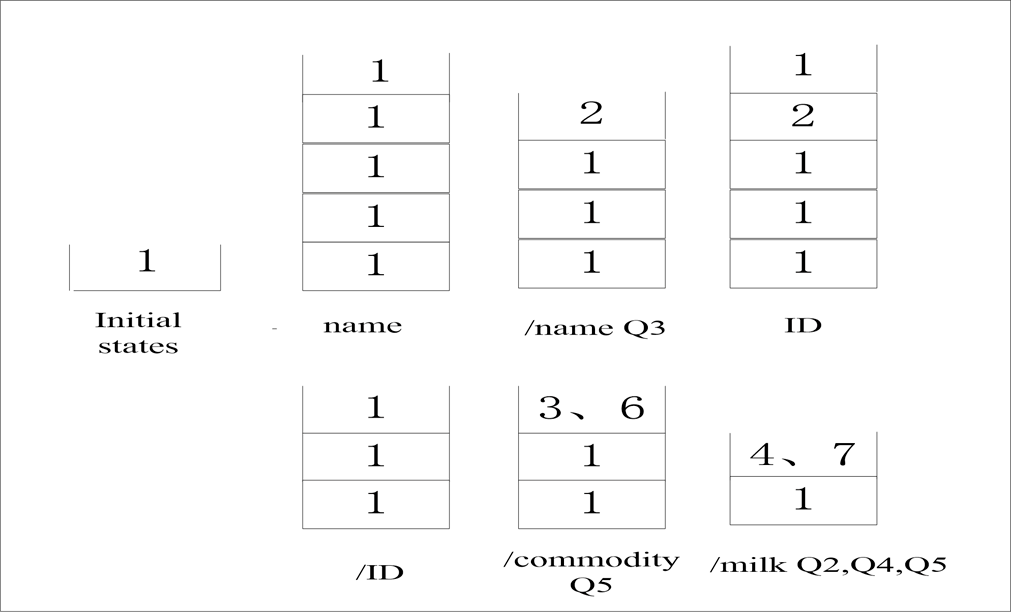
evaluate pattern
的执行过程如图8所示。在
startDocument()
事件中,我们将状态ID 1作为初始状态添加到运行时堆栈中。当元素
<store><milk><commodity><name>
被编码时,状态ID 1将被进入四次。当第一个结束事件
</name>
到达时,堆栈中的当前状态被弹出,并根据状态1的下一个转移状态的名称进行检查。根据转移规则,状态ID 2被压入运行时堆栈。根据规则,状态2是可访问的,并返回查询Q3。当遇到
<commodity>
时,将其压入状态ID 2。它解析
</commodity>
并弹出ID。转换状态ID 3是被压入查询Q5。由于递归,我们得到查询Q1和Q2。当解析
</milk>
时,我们在运行时堆栈中得到(4, 7),并返回查询Q2和Q4。对于重复的查询Q6,PTA过滤处理减少了重复判断,将其压入堆栈并放入Q4的集合中。
3 算法仿真与分析
3.1 参数分析
本文中关于监控传感器数据的XML文件由生成器XMark生成。XPath是YFilter拥有的查询,并具有受限DTD文件。
本研究使用JAVA语言,环境为Eclipse4.3.2,其频率为1.86GHz,内存为1.99GB。关键性能指标包括过滤时间和每秒堆栈处理元素数量。为了使结果更加准确,我们平均执行10次实验评估。
3.2 吞吐量分析
在本实验中,订阅者接收到的订阅数量为100–500。发布的信息可分为本地信息和网络信息,而信息解析后产生的事件可分为
common_event
、
order_event
和
semantic_event
。我们分别对它们进行测试。采用每秒运行时堆栈处理的元素数量作为性能指标,用于衡量通信中间件中最优匹配模型的性能(Resnik, 1999)。最优匹配模型的性能如图9所示。
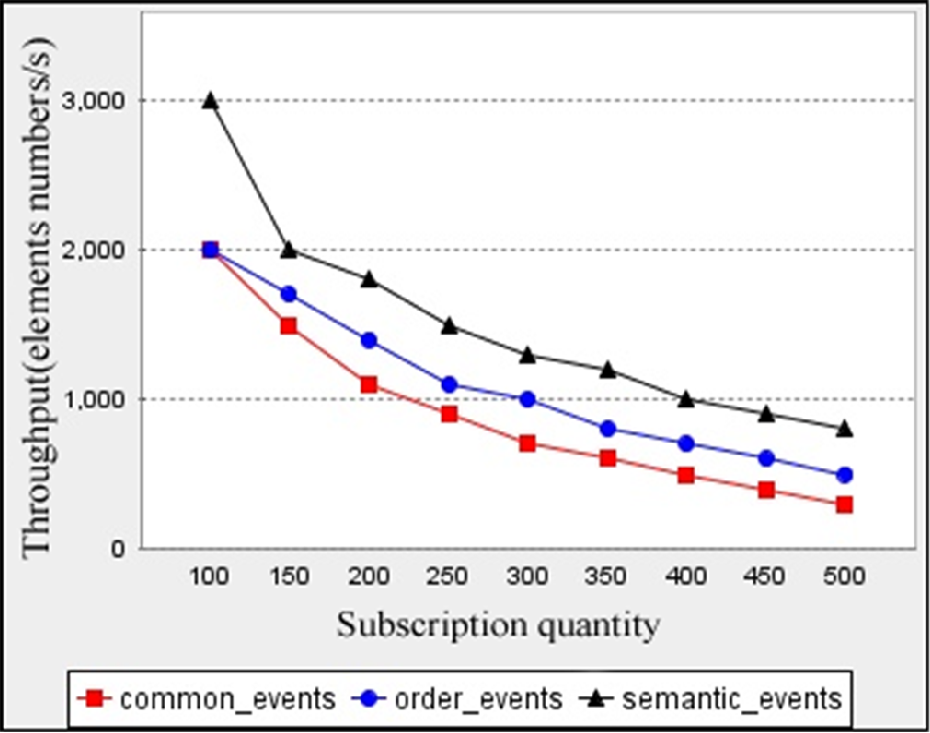
如图9所示,随着订阅数量的增加,每秒运行时堆栈处理的元素数量逐渐减少,且基于语义事件的算法下降幅度大于其他两种算法。因此,在近似语义匹配模型中,本文提出的处理事件流的算法优于传统算法。
3.3 近似语义因子的影响
近似语义因子的引入为自动机技术在通信中间件中的广泛应用前景提供了可能。在实验中,我们使用近似语义度来衡量其影响。DA(近似语义度)范围从0%到100%。实验结果如图10所示,其中Y轴表示通信中间件匹配过程中每秒运行时堆栈处理的元素数量。
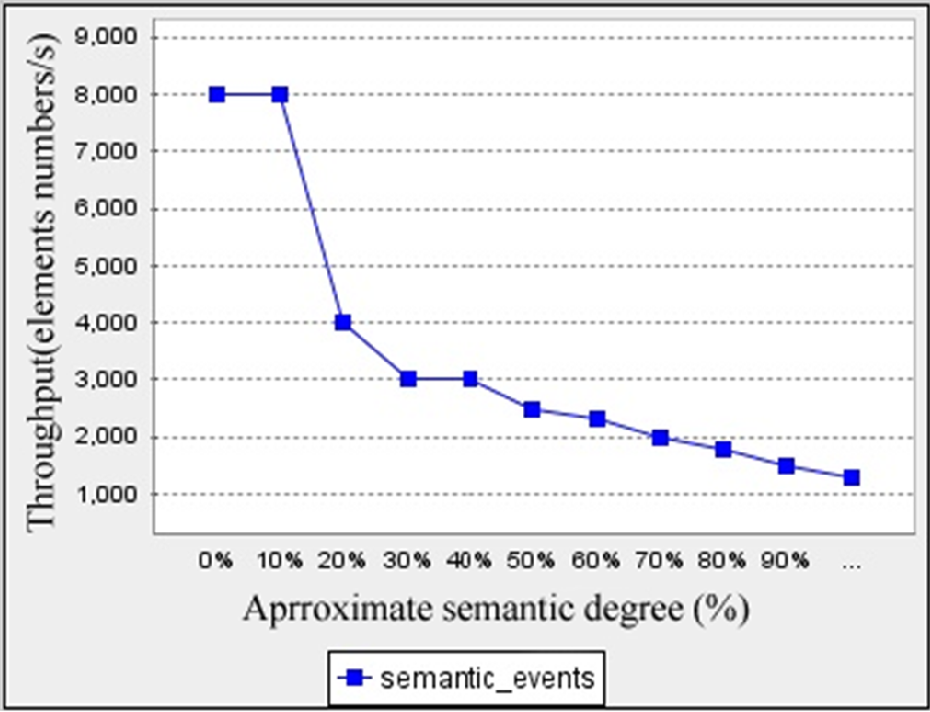
从图10可以看出,随着近似语义度的增加,每秒运行时堆栈处理的元素数量(性能指标)在表示10%近似语义度的位置开始逐渐减少。同时,随着近似语义度的增加,处理的元素数量下降得更多且更快。这证明了本文提出的近似语义因子具有重要意义。
3.4 可扩展性研究
为了使该通信中间件中的模型适用于更多场景,应评估其可扩展性。结果如表1所示。
| 网络数据 (M) | 5 | 11 | 23 | 34 | 46 |
|---|---|---|---|---|---|
| 代码数量 | 9845 | 11,510 | 12,659 | 154,699 | 203,201 |
| 匹配时间 | 438 | 750 | 1485 | 2172 | 2938 |
订阅数量的增加会延长匹配时间以及运行时堆栈中处理的代码量。它可广泛应用于实际的推式模式传感器网络中。
4 结论
在异构多传感器网络和物联网背景下,为了克服大规模异构语义数据和动态网络环境中事件流匹配的延迟问题,我们引入了近似语义因子,并提出了一种基于事件流的近似语义匹配模型。通过仿真得出,该通信中间件模型不仅能够有效提升事件匹配的语义耦合度,还能加速匹配过程并减少中间状态的内存消耗。同时,它具有良好的可扩展性,可广泛应用于推式模式传感器网络和物联网的大规模数据处理中。

















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









