







 本文详细介绍了Python数据分析库pandas的基础知识,包括Series的创建、修改索引、切片和索引,以及DataFrame的构造、索引、列操作。重点讲解了如何利用pandas处理和操作数据,如读取mongodb数据,并提到了数据排序方法sort_values()。此外,还涵盖了pandas中缺失数据的处理和读写文本文件的功能。虽然pandas没有内置的mongodb读取方法,但通过示例展示了如何实现。最后,强调了在实际工作中灵活运用pandas参数的重要性。
本文详细介绍了Python数据分析库pandas的基础知识,包括Series的创建、修改索引、切片和索引,以及DataFrame的构造、索引、列操作。重点讲解了如何利用pandas处理和操作数据,如读取mongodb数据,并提到了数据排序方法sort_values()。此外,还涵盖了pandas中缺失数据的处理和读写文本文件的功能。虽然pandas没有内置的mongodb读取方法,但通过示例展示了如何实现。最后,强调了在实际工作中灵活运用pandas参数的重要性。
介绍
在Python中,pandas是基于numpy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而numpy更适合处理统一的数值数组数据。
使用下面格式约定,引入pandas包:import pandas as pd
pandas有两个主要数据结构:Series 和 DataFrame
一、Series(一维,带标签数组)
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的 数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
1、Series的创建:
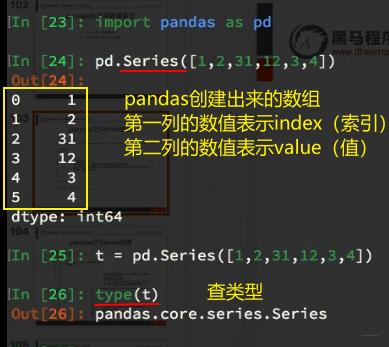
2、修改index:
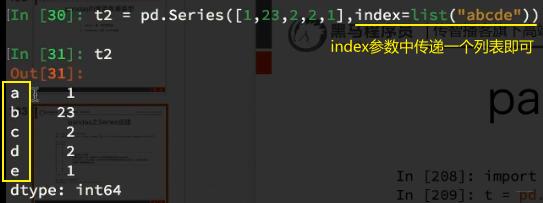
3、用string方法,给index属性传递字母:
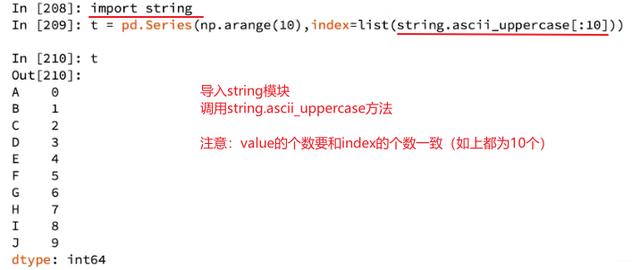
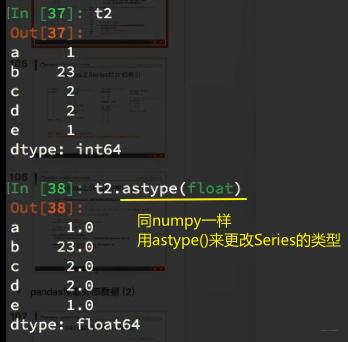
4、Series还可以用字典的格式来表示【dtype()查类型,astype()改类型】
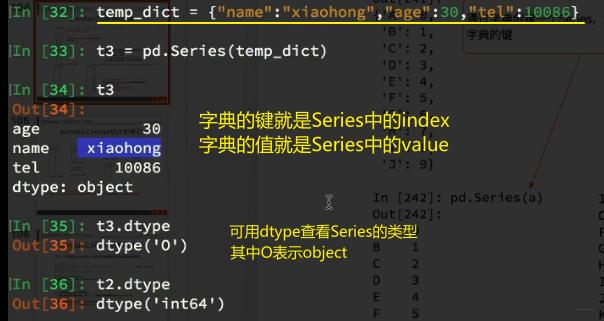

5、Series切片和索引

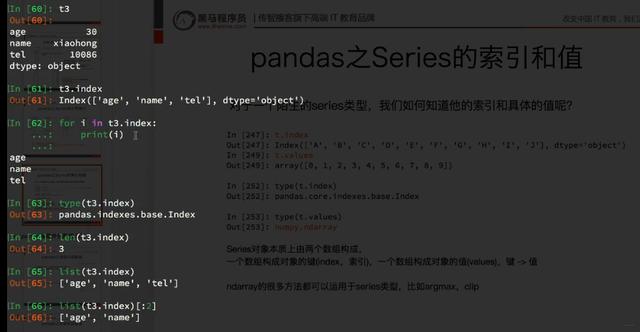
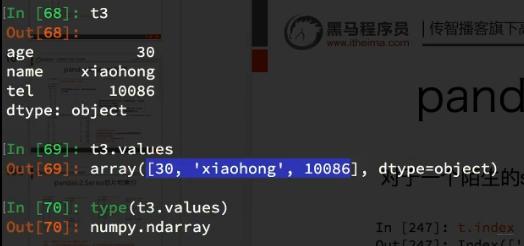
6、Series的索引和值
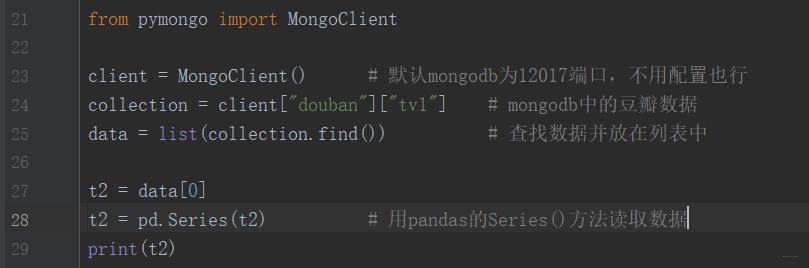
7、用Series()方法读取mongodb数据【pandas没有自带获取mongodb的方法】
二、DataFrame(二维,Series容器)
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。
DataFrame既有行索引,也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
1、DataFrame的创建:

2、更改行、列索引
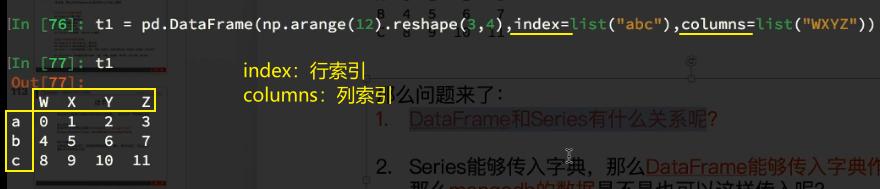
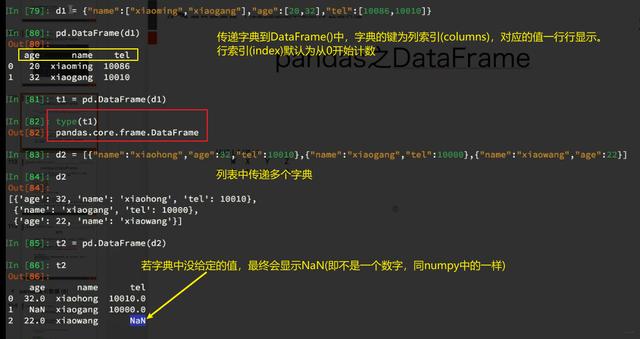
3、DataFrame还可以用字典的格式来表示
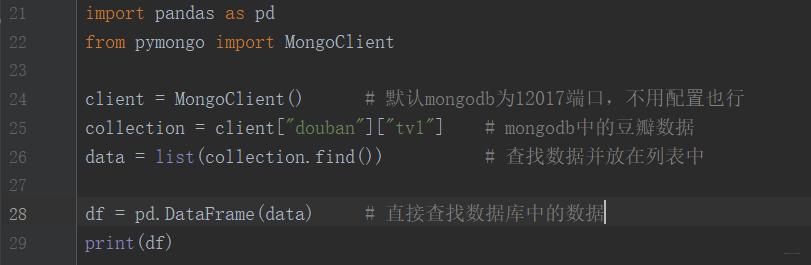
4、用DataFrame()方法读取mongodb数据【pandas没有自带获取mongodb的方法】
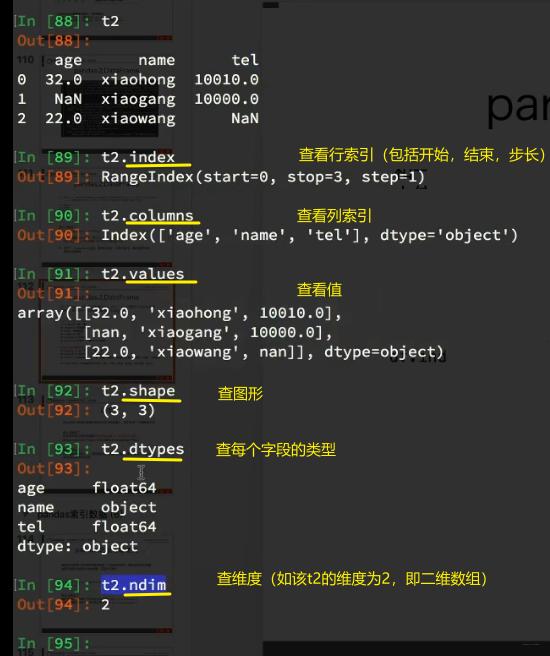
5、DataFrame的属性、用法 和 描述信息

》另外记住一个常用查询方法:sort_values()【用于对DataFrame数据进行排序】
df.sort_values(by="xxx", ascending=False) # by参数传递“需要按照哪个列排序”;ascending参数表示升序或降序,True为升序,False为降序。 12
6、DataFrame取值、取索引
》 取值:
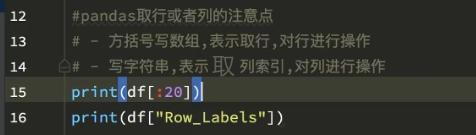
》① loc方法:

》 ② iloc方法:

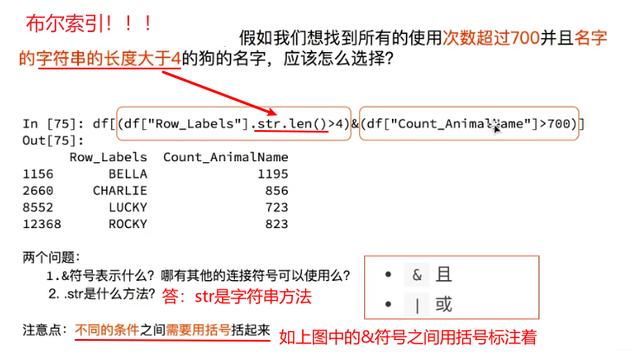
7、DataFrame布尔索引

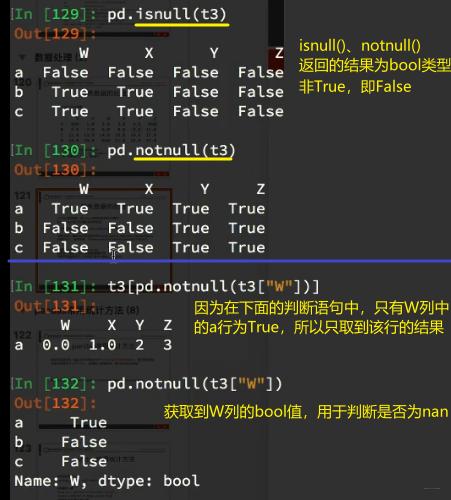
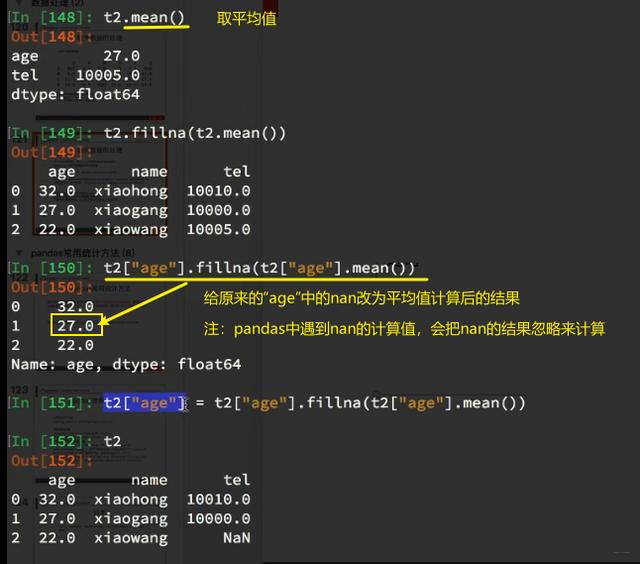
三、pandas中缺失数据的处理

四、pandas读写文本格式的数据
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。下表对它们进行了总结,其中read_csv()、read_table()、to_csv()是用得最多的。
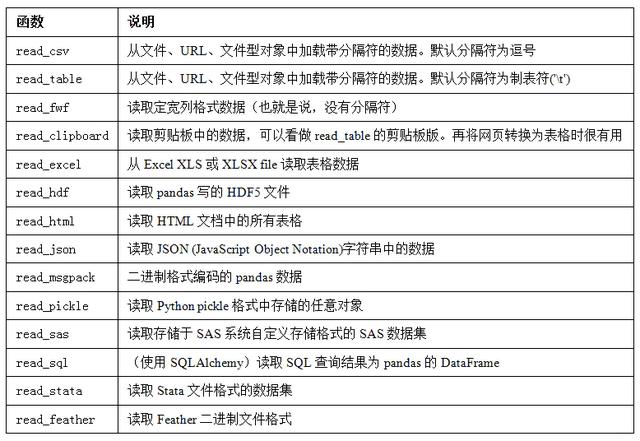
工作中实际碰到的数据可能十分混乱,一些数据加载函数(尤其是read_csv)的参数非常多(read_csv有超过50个参数)。
完整教程视频点这里获取

















 2531
2531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









