




 本文总结了pandas的两种核心数据结构Series和DataFrame,详细介绍了它们的特性、操作方法,包括重新索引、丢弃指定轴上的项、索引选择、算术运算以及处理缺失值。此外,还讨论了pandas的汇总统计和排序功能。
本文总结了pandas的两种核心数据结构Series和DataFrame,详细介绍了它们的特性、操作方法,包括重新索引、丢弃指定轴上的项、索引选择、算术运算以及处理缺失值。此外,还讨论了pandas的汇总统计和排序功能。
简介
pandas 是基于numpy构建的,让以numpy为中心的应用变得更加简单。
#pandas 导入
import pandas as pd
# pandas的两种数据结构
from pandas import Series, DataFrame
一、pandas的两种数据结构
1、Series
Series是一种类似于一维数组的对象,它是由一组数据(各种Numpy数据类型)以及与之相关的数据标签(即索引组成)。仅由一组数据即可产生最简单的Series。
obj = pd.Series([1, 3, 4, 5.6])
obj
# 输出
0 1.0
1 3.0
2 4.0
3 5.6
dtype: float64
Series的字符串表现形式为:索引在左边,值在右边。由于没有设定索引,会自动创建由0到N-1的整数型索引。可以通过Series的values和index属性来获取数组的表示形式和索引对象。
print(obj.values)
print(obj.index)
#输出
[1. 3. 4. 5.6]
RangeIndex(start=0, stop=4, step=1)
对Series的各个数据点设置索引值
obj1 = pd.Series([1, 3, 4, 5.6], index=['Bob', 'Joe', 'Will', 'Jack'])
obj1
# 输出:
Bob 1.0
Joe 3.0
Will 4.0
Jack 5.6
dtype: float64
与普通的Numpy数组相比,可以通过索引的方式选取Series中的单个或一组值
obj1['Bob']
# 输出:1.0
obj1[['Bob', 'Joe']]
# 输出:
Bob 1.0
Joe 3.0
dtype: float64
进行Numpy数组运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等)都会保留索引和值之间的链接。
obj1[obj1>2]
# 输出
Joe 3.0
Will 4.0
Jack 5.6
dtype: float64
obj1*2
# 输出
Bob 2.0
Joe 6.0
Will 8.0
Jack 11.2
dtype: float64
还可以将Series看成是一个定长的有序字典,因为它是索引值到数据的一个映射。
'Bob' in obj1
# 输出:True
# 传入一个字典,则series中的索引就是原字典的键
color = {'red': 2, 'green':5, 'black':4}
obj2 = pd.Series(color)
obj2
# 输出:
red 2
green 5
black 4
dtype: int64
color2 = ['red', 'green', 'orange', 'yellow']
obj3 = pd.Series(obj2, index=color2)
obj3
#输出
red 2.0
green 5.0
orange NaN
yellow NaN
dtype: float64
在pandas中使用NaN表示缺失值,可以用pd.isnull() 和pd.notnull() 来检测缺失值
pd.isnull(obj3)
# 等价于 obj3.isnull()
# 输出:
red False
green False
orange True
yellow True
dtype: bool
pd.notnull(obj3)
# 等价于 obj3.notnull()
# 输出:
red True
green True
orange False
yellow False
dtype: bool
Series还有一个重要的功能是在算术运算中会自动对齐不同索引的数据,比如上面的obj2 和obj3
另外,Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系密切
obj3.name = 'number'
obj3.index.name = 'color'
obj3
# 输出
color
red 2.0
green 5.0
orange NaN
yellow NaN
Name: number, dtype: float64
Series的索引可以通过赋值的方式就地修改
obj3.index=['Bob', 'Joe', 'Will', 'Jack']
obj3
# 输出
Bob 2.0
Joe 5.0
Will NaN
Jack NaN
Name: number, dtype: float64
2、DataFrame
DataFrame 是一个表格型的数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,可以看做由Series组成的字典。DataFrame中面向行和列的操作是平衡的。
构建DataFrame
传入一个由等长列表或Numpy数组组成的字典
data = {'state':['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year':[2001, 2002, 2001, 2003, 2000],
'pop':[1.5, 1.7, 3.6, 2.4, 2.9]
}
df = pd.DataFrame(data)
df
输出结果
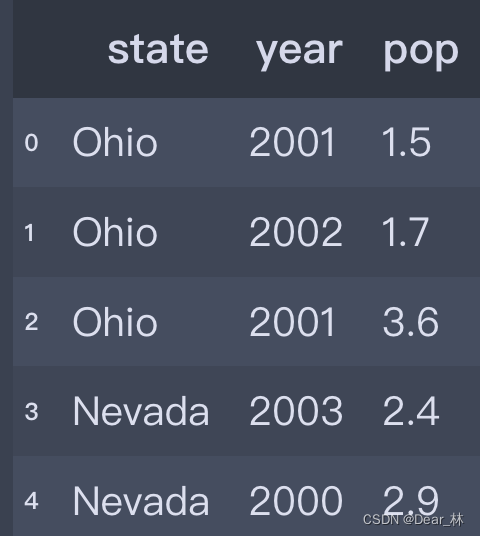
DataFrame会自动加上索引,且全部列会被有序排列,如果指定了列序列,则DataFrame的列会按照指定的顺序进行排列
df2 = pd.DataFrame(data, columns=['pop', 'state', 'year'])
df2
输出结果:
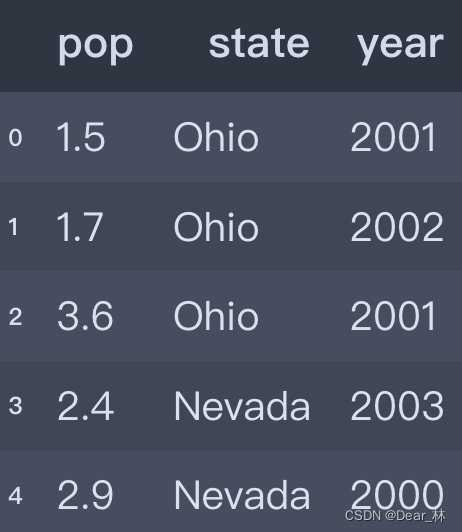
跟Series一样,如果传入的列在数据中找不到,就会产生NaN值,另外可以通过类似于字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series
df3 = pd.DataFrame(data, columns=['pop', 'state', 'year', 'debt'])
df3
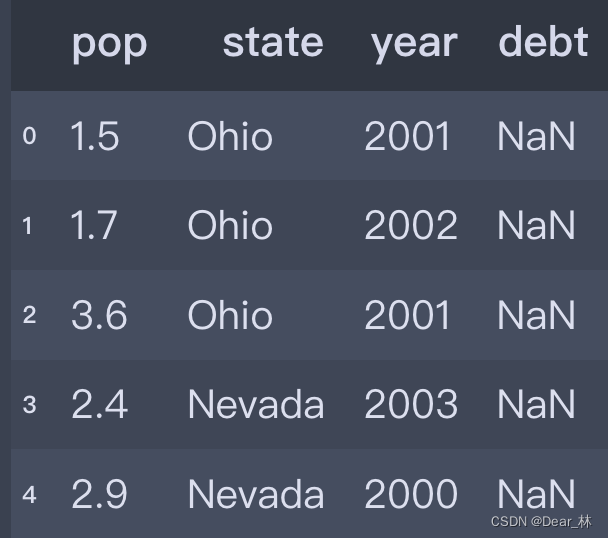
df3['year']
# 等价于 df3.year
# 输出:
0 2001
1 2002
2 2001
3 2003
4 2000
Name: year, dtype: int64
列可以通过赋值的方式进行修改,将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。
df3['debt'] = 16.6
# df3['debt'] = np.arange(5)
另一种常见的数据形式是嵌套字典,将它传给DataFrame时,外层字典的键作为列,内层字典的键作为行索引
pop = {'Nevada':{2003:2.4, 2000:2.9},
'Ohio':{2001:1.5, 2000:2.6, 2003:1.7}}
df4 = pd.DataFrame(pop)
df4
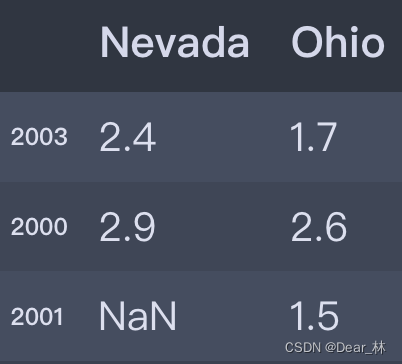
下面对可以输入给DataFrame构造器的数据做一总结:

二、基本功能
1、重新索引
pandas对象的一个重要方法是reindex,其作用是创建一个适应新索引的新对象,
obj = pd.Series([4.5, 7.2, -5.3, 3.6],
index=['d', 'b', 'a', 'c'])
obj.reindex(['a', 'b', 'c', 'd', 'e'])
# 输出:
a -5.3
b 7.2
c 3.6
d 4.5
e NaN
dtype: float64
obj.reindex(['a', 'b', 'c', 'd', 'e'],fill_value=0.0)
# 输出:
a -5.3
b 7.2
c 3.6
d 4.5
e 0.0
dtype: float64
reindex会根据索引值进行重排,如果某个索引值当前不存在,就引入缺失值。可以用fill_value对缺失值进行填充。还可以使用method进行填充:
obj2 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
# 使用ffill可以实现前向值填充
obj3 = obj2.reindex(range(6), method='ffill')
obj3
# 输出
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object
reindex的插值method选项

reindex 可以修改行索引或者列索引,或者两个都修改,如果仅传入一个序列,则会重新索引行。
frame = pd.DataFrame(np.arange(9).reshape(3, 3),
index=['a', 'b', 'c'],
columns=['Ohio', 'Texas', 'Claifornia'])
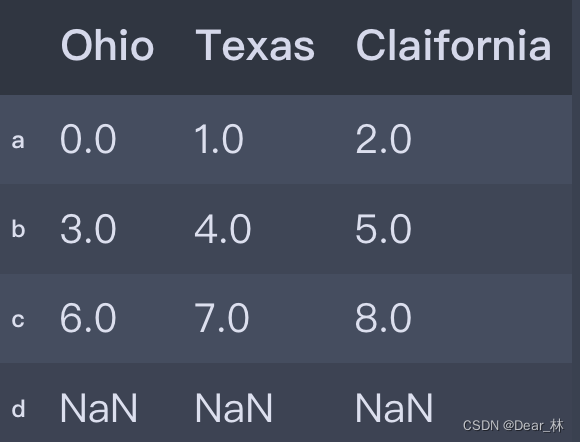
frame2 = frame.reindex(['a', 'b', 'c', 'd'])
frame2
输出结果:
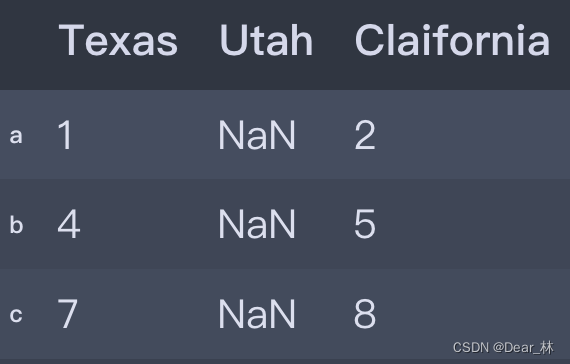
states = ['Texas', 'Utah', 'Claifornia']
frame3 = frame.reindex(columns=states)
frame3
输出结果:
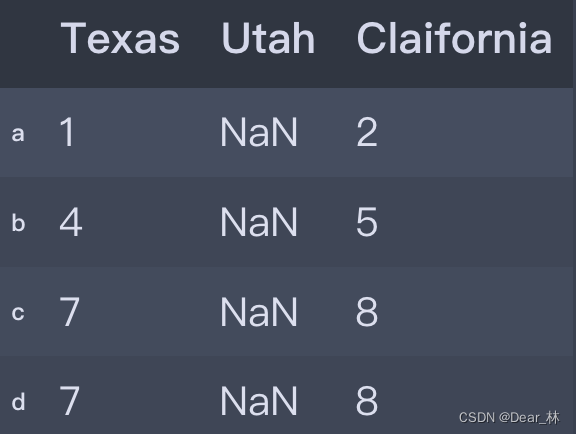
frame3.reindex(index=['a', 'b', 'c', 'd'],method='ffill',columns=states)
输出结果:
reindex 函数的各参数及说明

2、丢弃指定轴上的项
丢弃某条轴上的一个或多个项很简单,只要有一个索引数组或列表即可。
obj = pd.Series(np.arange(5), index=['a', 'b', 'c', 'd', 'e'])
obj.drop(['c'])
# 输出
a 0
b 1
d 3
e 4
dtype: int64
注意使用drop函数是重新生成一个Series,对原来的Series不会做修改
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data

data.drop(['Colorado', 'Ohio'])
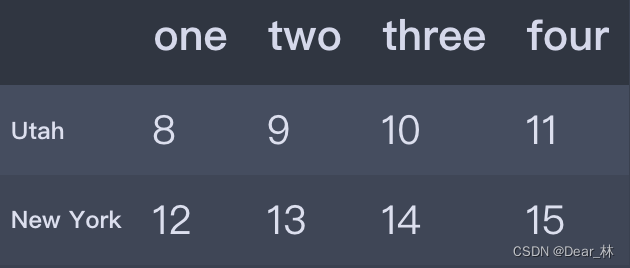
data.drop(['two', 'four'], axis=1)

3、索引、选取和过滤
Series索引类似于Numpy数组,不过Series的索引值不只是整数。对DataFrame进行索引就是获取一个或多个列。
obj = pd.Series(np.arange(5), index=['a', 'b', 'c', 'd', 'e'])
obj['b']
# 等价于 obj[1]
# 输出:1
obj[2:4]
# 输出:
c 2
d 3
dtype: int64
obj['b':'d']
# 相对于Numpy的索引,Series索引末端是包含的
# 输出:
b 1
c 2
d 3
dtype: int64
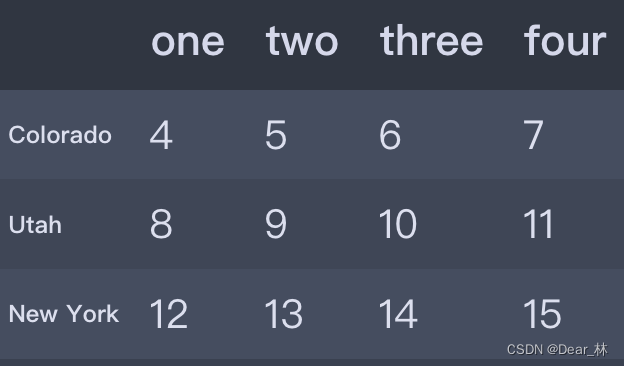
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data['two']
#选取指定行的数据
# 输出:
Ohio 1
Colorado 5
Utah 9
New York 13
Name: two, dtype: int64
data[['one', 'two']]
# 选取指定的两列数据
# 输出:

data[:2]
#选取前两行的数据
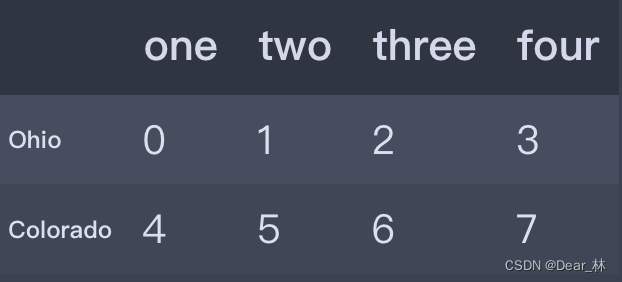
data[data['three']>5]
# 布尔型选取,选取指定列大于5的所有数据
4、算术运算和数据对齐
pandas 最重要的一个功能是可以对不同索引的对象进行算术运算。在将对象进行相加时,如果存在不同的索引对,则结果的索引对就是该索引对的并集。
s1 = pd.Series([1.1, 3.4, 2.5, 5], index=['a', 'b', 'c', 'd'])
s2 = pd.Series([3.2, 4.0, 8.2, 2], index=['a', 'c', 'd', 'e'])
s1 + s2
# 输出结果:
a 4.3
b NaN
c 6.5
d 13.2
e NaN
dtype: float64
# 对于DataFrame 自动对齐操作会同时发生在行和列中
df1 = pd.DataFrame(np.arange(9).reshape((3,3)),
columns=list('bcd'),
index=['Ohio','Texas', 'Colorado'])
df2 = pd.DataFrame(np.arange(12).reshape((4, 3)),
columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
df1 + df2
输出结果:索引和列是原来数据的并集

三、汇总和描述统计
data = pd.DataFrame(np.random.randn(4, 3), columns=list('bcd'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
data
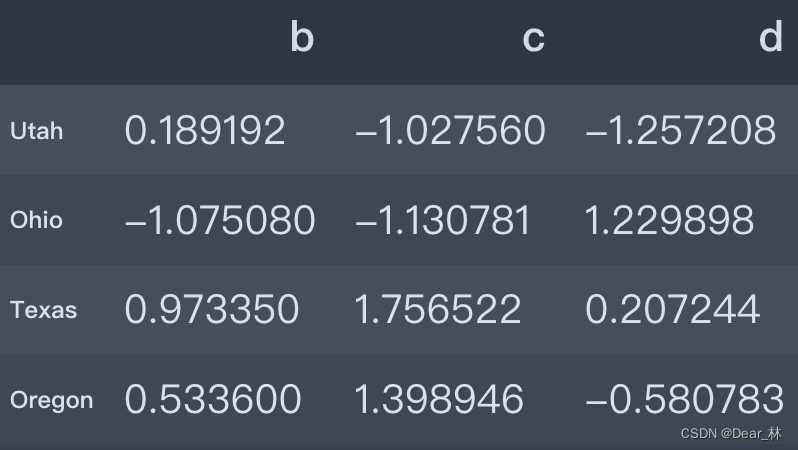
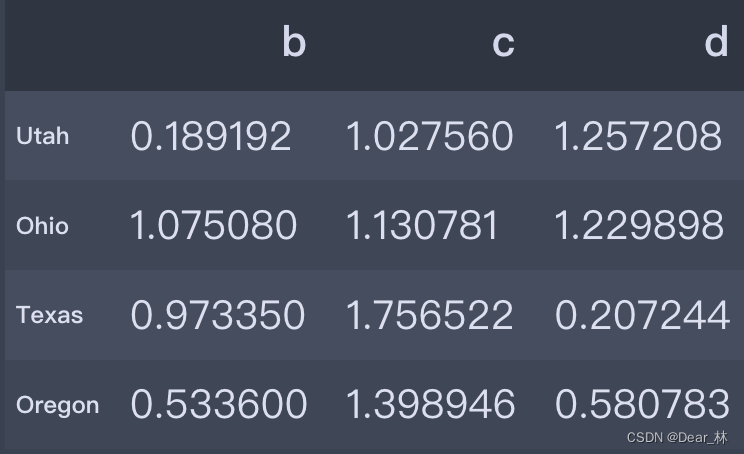
有可以用于整个pandas的函数,也可将函数应用到由各行或列所形成的一维数组上,DataFrame的apply方法即可实现此功能。
np.abs(data)
输出结果:
f = lambda x:x.max() - x.min()
data.apply(f)
# 输出结果:
b 2.048429
c 2.887303
d 2.487107
dtype: float64
data.apply(f, axis=1)
# 输出结果:
Utah 1.446400
Ohio 2.360680
Texas 1.549278
Oregon 1.979729
dtype: float64
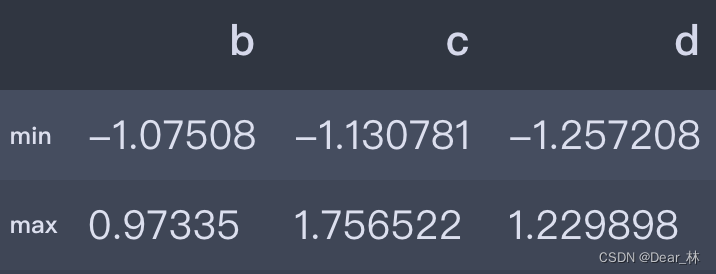
def fun(x):
return pd.Series([x.min(), x.max()], index=['min', 'max'])
data.apply(fun)
输出结果:
排序和排名
根据条件对数据集排序,可用sort_index方法,对行或列进行排序,返回一个已排序的新对象。
对于Series排序还可以用order方法,对DataFrame可以指定轴进行排序,默认是升序排列,也可按降序排列
obj = pd.Series(range(4), index=['a', 'd', 'c', 'b'])
obj.sort_index()
# 等价于 obj.order()
# 输出:
a 0
b 3
c 2
d 1
dtype: int64
df = pd.DataFrame(np.arange(8).reshape(2, 4), index=['three', 'one'],
columns=['d', 'a', 'b', 'c'])
df.sort_index()
#指定轴进行排序
df.sort_index(axis=1)
# 默认是升序排列,也可按照降序排列
df.sort_index(axis=1, ascending=False)
在DataFrame中还可以根据一个或多个列中的值进行排序,将一个或多个列的名字传递给参数by即可。
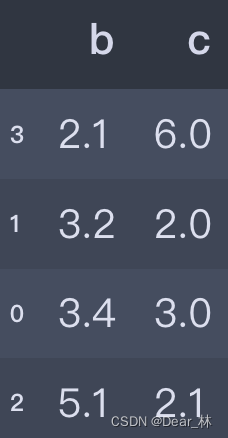
frame = pd.DataFrame({'b':[3.4, 3.2, 5.1, 2.1], 'c':[3, 2, 2.1, 6]})
frame.sort_values(by='b')
输出结果:
四、处理缺失值
pandas中所有描述统计都排出了缺失数据,pandas中使用浮点值NaN表示浮点或非浮点数组中的缺失数据,是一个便于检测出来的标记。下面来了解一下pandas中对缺失值的处理
string_data = pd.Series(['one', 'two', 'three', np.nan])
# 查看缺失值
pd.isnull(string_data)
pd.notnull(string_data)
# 删除缺失值
string_data.dropna()
# 填充缺失值
string_data.fillna('four')
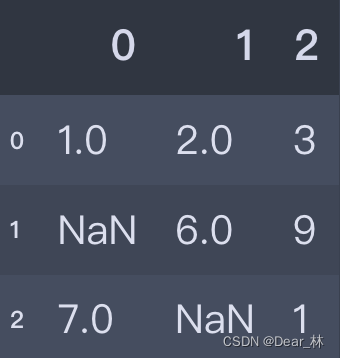
df = pd.DataFrame([[1, 2, 3], [np.nan, 6, 9], [7, np.nan, 1]])
df
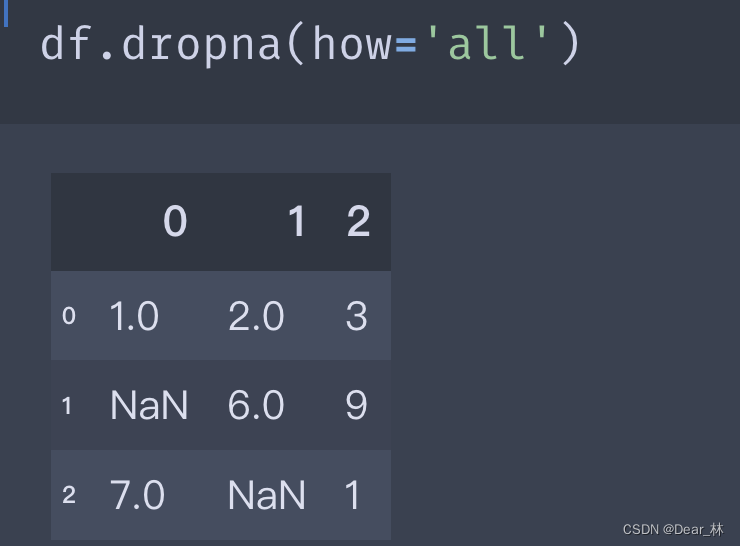
DataFrame 中使用dropna删除缺失值默认丢弃任何含有缺失值的行
df.dropna()

如果传如how='all’则会丢弃全为nan的行

















 7491
7491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









