



作为一名AI大模型应用开发工程师,我深知RAG(Retrieval-Augmented Generation)系统在实际应用中的挑战:检索不精准、回答不聚焦,往往是分块(Chunking)环节出了问题。分块作为RAG的数据预处理核心,直接影响嵌入模型和LLM的效能。
本文基于专业实践和全网技术资源,深入剖析分块的原理、策略和优化技巧,帮助你构建更智能的RAG应用。
引言:分块——RAG系统的命脉
在RAG架构中,分块是连接原始文档和语义检索的桥梁。它决定了嵌入模型能否精准捕捉文本语义,以及LLM能否生成高质量回答。许多开发者误以为“越大越好”,直接将整篇文档喂给模型,结果导致信息稀释和检索失效。分块的本质是为语义“降噪”,适应模型的上下文限制。我将系统拆解分块的最佳实践,包括大小选择、主流策略和高级技巧,助你突破RAG性能瓶颈。
一、为什么分块如此重要?核心原理剖析
分块在RAG中的作用远超简单的文本切割。它解决了两大核心问题:
- 语义降噪:嵌入模型(如OpenAI的text-embedding-ada)将文本压缩为固定维度的向量(如1536维)。如果文本块过大(例如接近模型的8191 token上限),多个主题混杂会导致向量模糊不清。就像一张全景照片,信息量大但细节丢失。合理的分块确保每个块聚焦单一主题,提升嵌入向量的语义纯度。
- 适应模型限制:LLM的上下文窗口有限(如GPT-4的128K token窗口并非万能)。即便技术发展,处理长文本时仍可能“遗忘”关键信息。分块将文档切分为小块,确保每个块在模型的最佳处理范围内,避免信息过载。
案例佐证:医疗文档查询示例
- 问题场景:用户查询“糖尿病肾病的症状”。
- 大分块(500+ token):包含分型、并发症、饮食等多主题,导致检索时相关性分数低,回答泛化。
- 小分块(200 token):聚焦主题如“糖尿病肾病的症状包括蛋白尿、水肿”,检索精准,回答一针见血。 这印证了分块的核心价值:提升语义密度,避免主题稀释。
二、分块大小的“黄金法则”:200-800 Token的平衡艺术
一个常见误区是追求分块接近模型token上限。实际上,分块大小需在语义完整性和信息密度间权衡:
Token陷阱:嵌入模型对任何大小的输入都输出相同维度的向量。大块(如3000 token)压缩率高,信息损失严重;小块(如100 token)语义纯粹但可能缺乏上下文。业界实证(如LangChain社区测试)表明,200-800 token是最佳区间。
最佳实践:
- 起点推荐:从256 token开始测试(覆盖多数主题的完整性)。
- 动态调整:结构化文档(如技术手册)可用更大块(500 token),非结构化文本(如论坛帖子)用更小块(200 token)。
- 工具实现:使用Hugging Face的transformers库计算token,或LlamaIndex的SentenceSplitter自动分块。
全网扩展:在开源社区(如GitHub),开发者常用滑动窗口分块法:重叠10-20%的token,确保上下文连贯。例如,处理PDF文档时,PyPDF2结合NLTK分句实现动态切分。
三、四大主流分块策略详解与实战对比
分块策略选择取决于文档类型。以下是核心方法及其适用场景(配图示增强理解):
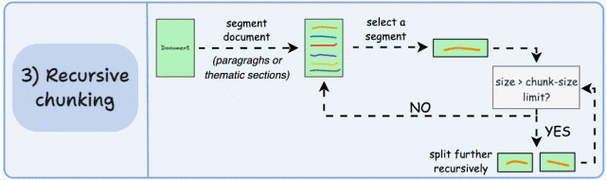
递归分块(Recursive Chunking)
- 原理:基于自然语言边界(如句号、段落)递归切割文本,优先保留语义单元。适合通用文本,如新闻或报告。
- 优势:简单高效,在多数场景表现最佳。
- 工具示例:LangChain的RecursiveCharacterTextSplitter支持自定义分隔符(如\n\n)。
格式分块(Format Chunking)
- 原理:利用文档结构(如Markdown标题、HTML标签)分块。例如,将每个H2标题下的内容作为一个块。
- 优势:保留结构化信息,适合技术文档或API手册。
- 案例:处理GitHub README时,按章节分块提升检索精度。
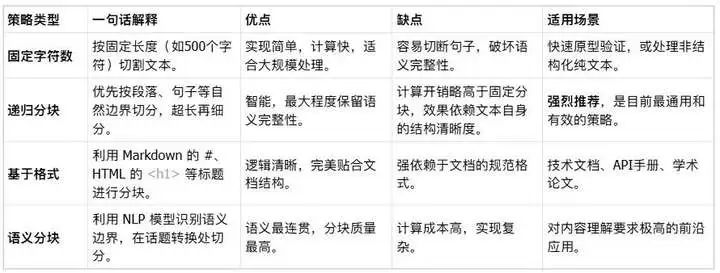
固定大小分块(Fixed-size Chunking)
- 原理:按固定token数切割,简单粗暴。适合流水线处理,但可能破坏语义。
- 适用场景:大批量文本预处理,需搭配重叠机制。
内容感知分块(Content-aware Chunking)
- 原理:使用NLP模型(如BERT)识别主题边界分块。适合复杂文档(如研究论文)。
- 全网资源:SpaCy的实体识别可辅助分块,提升主题一致性。
策略选择指南:
- 优先递归分块(80%场景适用)。
- 结构化文档用格式分块。
- 实验是关键:构建评测集(如使用Rouge指标)比较不同策略的检索召回率。
四、高级索引技巧:突破精度瓶颈
当基础分块不足时,进阶技巧能大幅提升性能。以下是全网验证的实战方案:
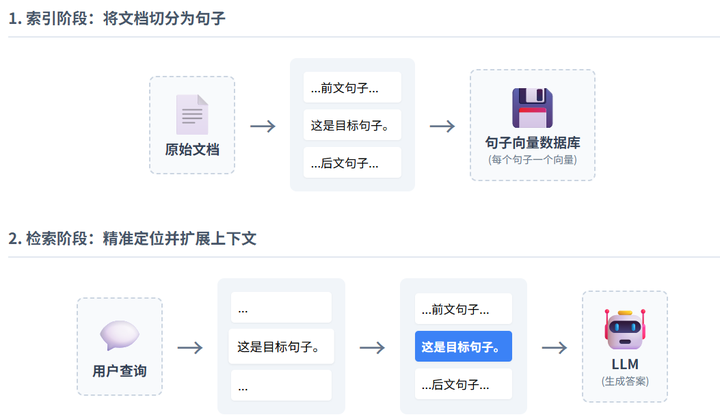
句子窗口检索(Sentence Window)
- 原理:检索单个句子(高精度),但返回时附加前后句子作为上下文窗口。
- 效果:平衡精度与信息量,避免LLM生成片面回答。
- 实现:用Faiss索引句子,窗口大小通常为3-5句。
父文档检索器(Parent Document Retriever)
- 原理:小块索引(子块),检索后返回父块(更大上下文)。例如,子块是段落,父块是章节。
- 效果:小块提升检索,父块丰富生成。
- 工具支持:LlamaIndex的ParentDocRetriever内置该功能。

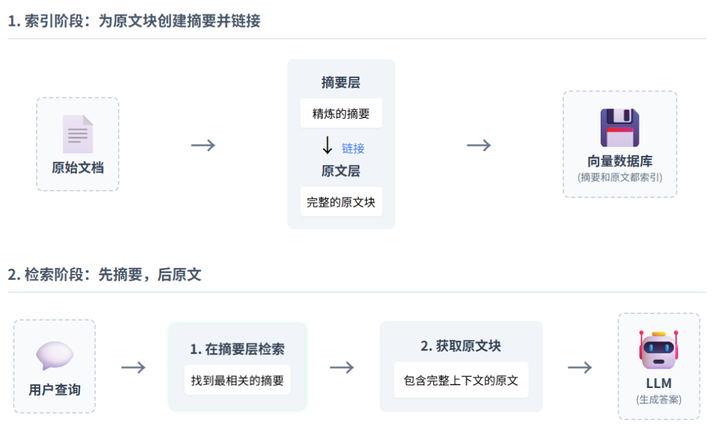
摘要索引(Summary Indexing)
- 原理:为每个块生成摘要,先在摘要层检索,再获取原文块。
- 优势:加速检索,避免噪音。
- 案例:处理长报告时,用T5生成摘要,检索效率提升50%。
元数据过滤(Metadata Filtering)
- 原理:分块时添加元数据(如页码、文档标题),检索前过滤无关块。
- 应用:多源文档(如企业知识库)中,快速缩小搜索范围。
- 实现:Elasticsearch结合向量数据库,元数据作为预过滤条件。

五、最佳实践与实验指南
分块非银弹,需基于业务定制。以下是可落地的建议:
起步方案:
- 分块大小:256 token(默认),递归分块优先。
- 工具链:LangChain + ChromaDB,快速搭建原型。
实验方法论:
- 构建评测集:使用TruthfulQA或自定义数据集,评估检索精度(如Hit Rate)和生成质量(如BLEU分数)。
- 参数调优:测试不同大小(128、256、512 token)和重叠率(0-20%)。
进阶优化:
- 混合策略:格式分块用于结构化部分,递归用于其余。
- 监控迭代:接入Prometheus监控检索延迟,动态调整分块参数。
避坑提示:
- 避免静态分块:文档更新时需重新分块。
- 安全考虑:分块时过滤敏感信息(如PII)。
作者结语:
分块是RAG系统中最易忽视却最关键的一环。记住,分块是艺术而非科学——大胆实验,结合业务数据迭代。未来,随着多模态RAG兴起,分块将扩展至图像和音视频领域。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









