



Hello 大家好,用Langchian两年多了,今天想讲下我对这个框架的一些了解。
LangChain这几年已经算是构建基于大型语言模型LLM应用的那种高效工具之一了。说实话,不管你是刚刚开始了解AI,还是想深造的开发者,这个系列都会从最基础一直到进阶内容,系统地把LangChain的核心原理与关键组件帮你理清楚思路、全盘掌握应用落地的技巧。
LangChain 到底是啥?
LangChain 它主要是一个为了 LLM 就是诞生的开源开发框架。它其实就是把语言模型调用、知识检索、还有语义搜索这些很常见的流程都给封装好啦。这样开发者们就可以比较专注于业务层面的创新,省得一直反复自己“造轮子”。

为什么说 LangChain 必不可少?
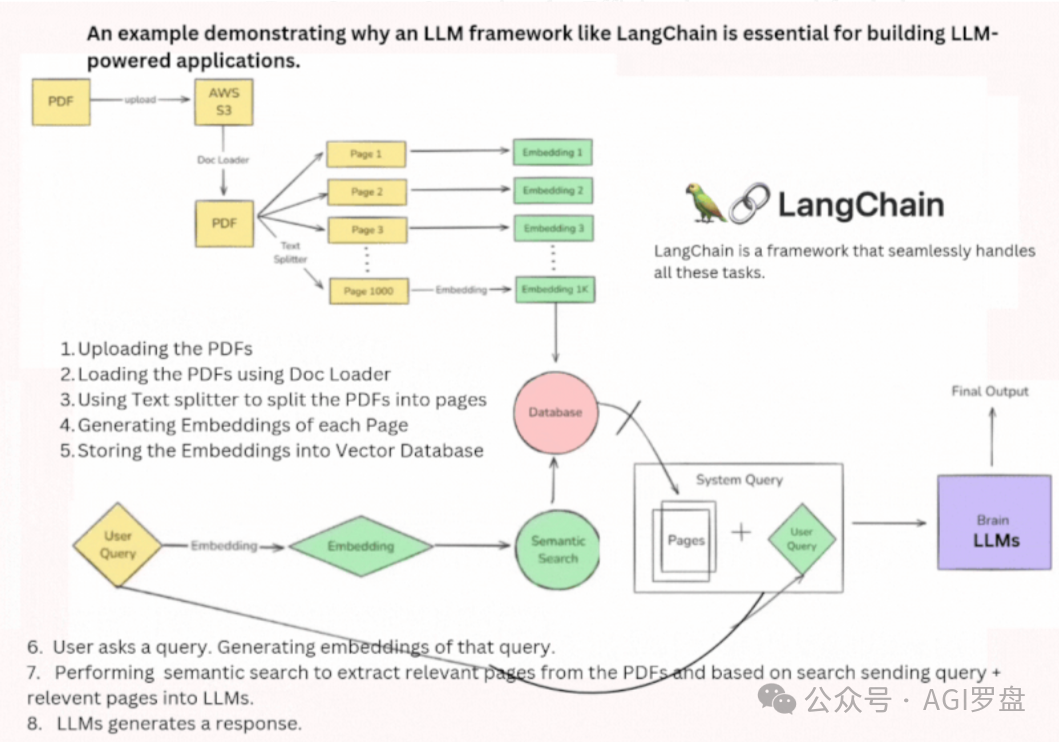
就比如说吧,你打算开发一个智能助手,用户可以上传 PDF 这种机器学习类的文档,而且还能像聊天那样跟文档互动,提出一些问题,比如:
-
• “用通俗易懂方式总结第 5 页内容。”
-
• “针对线性回归生成真假判断题。”
-
• “请简要整理决策树相关知识点”
要实现这些功能,开发者基本上面临这些技术点子:
-
1. 数据存储与检索:你得高效率的保存、访问文档内容;
-
2. 语义搜素 :理解用户真正的吗想法,绝不是仅仅关键词匹配就行;
-
3. LLM 集成:得接入 GPT、LLaMA 这些大的模型;
-
4. 流程管理:让文档向量化、建索引等步骤顺畅衔接,不掉链子。
-
LangChain 就有点像“百宝箱”,为你准备好了很多现成能力,比如:
-
• 文档处理、语义搜素模块随拿随用;
-
• LLM 调度和响应管理非常灵活;
-
• 会话记忆保证上下文连贯;
-
• 外部工具的集成也不麻烦。
所以讲啊,开发者根本不用从头到尾自己框架,各种复杂应用就比较容易做出来。
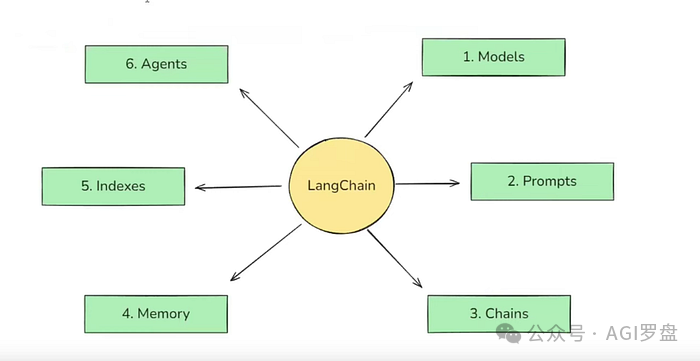
LangChain 六大核心组件
LangChain 框架其实拆分下来有 6 大部分,理解它们,基本上就是智能应用开发的重点啦。
1.模型(Models)
模型组件是整个 LangChain 的底座,主要负责对接各种 AI 模型。说到底,早期聊天机器人总卡在两个大难题:就是理解人类自然语言(NLU)和生成合理回复(上下文感知文本生成)。LLM 的涌现,让这两块有了突破——但也带来新问题:模型体积太庞大,个人电脑甚至小型服务器都吃不消。
那主流云服务厂商就开始开放AI模型API,比如 OpenAI 的 GPT。开发者直接通过互联网调用、按用量付费,不用本地布署,也省心多了。不过厂商接口都不一样,集成起来其实特别“恶心人”。LangChain 的模型组件,就把这些接口都统一封装好啦,无论是 OpenAI、Anthropic 还是第三方模型,那个调配置切换就可以,主代码几乎不用改动。
两类模型
-
• 语言模型:传统 LLM,输入文本,输出文本。
-
• 嵌入模型:输入文本,生成向量,做语义检索用。
import getpass
import os
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
ifnot os.environ.get("GOOGLE_API_KEY"):
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter API key for Google Gemini: ")
# Google Gemini
model = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
# Deepseek
model = init_chat_model("deepseek-chat", model_provider="deepseek")
model.invoke([HumanMessage(content="Hi! I'm Bob")])
# Output
AIMessage(content='Hi Bob! How can I assist you today?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 11, 'total_tokens': 21, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0705bf87c0', 'finish_reason': 'stop', 'logprobs': None}, id='run-5211544f-da9f-4325-8b8e-b3d92b2fc71a-0', usage_metadata={'input_tokens': 11, 'output_tokens': 10, 'total_tokens': 21, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})
2.提示词(Prompts)
那个跟 LLM 互动,开发者输入的内容叫“提示词”。这提示词其实直接决定了模型的输出结果,而且 LLM 对你写法的敏感度超乎想象。比如说,“用学术语气讲机器学习”和“用趣味方式介绍机器学习”只差几个字,风格就完全变了。
LangChain 支持各种类型的提示模板:
-
• 动态提示:用占位符写模板,比如“以{语气}总结{主题}”
-
• 角色提示:先给模型定好身份,如“你是一位资深医生”
-
• 少量样本提示:给模型几个样例后,它会举一反三
提示词这个组件,让复杂需求都有结构化的实现空间,真心灵活。
# 单一Prompt用法
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({"topic": "cats"})
# 包含System Prompt 用法
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
prompt_template.invoke({"topic": "cats"})
# 包含历史记录 Prompt 用法
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
prompt_template = ChatPromptTemplate([
("system", "You are a helpful assistant"),
MessagesPlaceholder("msgs")
])
# Simple example with one message
prompt_template.invoke({"msgs": [HumanMessage(content="hi!")]})
# More complex example with conversation history
messages_to_pass = [
HumanMessage(content="What's the capital of France?"),
AIMessage(content="The capital of France is Paris."),
HumanMessage(content="And what about Germany?")
]
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
print(formatted_prompt)
3. 链(Chains)
链组件主要是把复杂任务拆成多个步骤,像流水线一样串联起来。例如,你需要把英文长文输入,输出成简明印地语摘要,流程可能大致这样:
-
1. 用户输入英文段落
-
2. LLM 先翻译成印度语
-
3. LLM 再对印度语文档做摘要
-
4. 返回给用户
各个环节设定好,数据自然流转,减轻流程管理压力,效率大大提升。
import getpass
import os
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
ifnot os.environ.get("GOOGLE_API_KEY"):
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter API key for Google Gemini: ")
model = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
chain = prompt | model | StrOutputParser()
chain.invoke({"topic": "bears"})
# output
"Why don't bears wear shoes?\n\nBecause they prefer to go bear-foot!"
4. 索引(Indexes)
其实 LLM 单靠训练语料,很难解答企业私有的问题,比如“公司 XYZ 的请假政策”那种。这个时候索引组件就很重要。它把 LLM 连接到私有网页、PDF文档等,让知识检索更有针对性。
你看索引模块涉及这些内容:
-
1. 文档加载器,比如支持 PDF、网页等多来源
-
2. 文本切分器,把大文件分成小段落
-
3. 向量数据库,把文本嵌入向量方便相似度搜素
-
4. 检索器,负责查找相关文本片段、喂给LLM生成合适答案
from langchain.indexes import SQLRecordManager, index
from langchain_core.documents import Document
from langchain_elasticsearch import ElasticsearchStore
from langchain_openai import OpenAIEmbeddings
# 1. Initialize the Vector Store and Embeddings:
collection_name = "test_index"
embedding = OpenAIEmbeddings()
vectorstore = ElasticsearchStore(
es_url="http://localhost:9200", index_name=collection_name, embedding=embedding)
# 2. Set Up the Record Manager:
namespace = f"elasticsearch/{collection_name}"
record_manager = SQLRecordManager(
namespace, db_url="sqlite:///record_manager_cache.sql"
)
record_manager.create_schema()
# 3. Index Documents:
doc1 = Document(page_content="kitty", metadata={"source": "kitty.txt"})
doc2 = Document(page_content="doggy", metadata={"source": "doggy.txt"})
# Using the 'incremental' cleanup mode for this example
index([doc1, doc2], record_manager, vectorstore, cleanup="incremental", source_id_key="source")
5.记忆(Memory)
绝大部分 LLM API 其实是“无状态”的,就是每次调用都不会记得上次聊了啥。LangChain 的记忆模块让上下文可以持久化,体验更好。
记忆常用方案有:
-
• ConversationBufferMemory —— 完整保存历史对话
-
• ConversationBufferWindowMemory —— 只保留最近 N 个
-
• ConversationSummaryMemory —— 用摘要替代历史内容
-
• CustomMemory —— 有特殊需求可以自定义
有了记忆,对话体验提升很多,机器人甚至能像朋友那样记住你的习惯和细节。
# ChatMessageHistory
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")
print(history.messages)
# ConversationBufferMemory
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("what's up?")
print(memory.load_memory_variables({}))
...
6.智能体(Agents)
智能体其实不只会聊天,还能主动调用各种工具,完成实际任务。比如:
-
• 有人问:“1 月 24日 从广州到北京最便宜机票”,智能体会调用航班API、自动预订
智能体最厉害的地方:
1、推理:会把任务拆分成多步,一步步推进
2、工具接入:能调计算器、检索服务甚至外部 API,动手解决问题
# Import relevant functionality
from langchain.chat_models import init_chat_model
from langchain_tavily import TavilySearch
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
# Create the agent
memory = MemorySaver()
model = init_chat_model("anthropic:claude-3-5-sonnet-latest")
search = TavilySearch(max_results=2)
tools = [search]
agent_executor = create_react_agent(model, tools, checkpointer=memory)
# Use the agent
input_message = {
"role": "user",
"content": "What's the weather where I live?",
}
for step in agent_executor.stream(
{"messages": [input_message]}, config, stream_mode="values"
):
step["messages"][-1].pretty_print()
# =========================Output==========================
================================[1m Human Message [0m=================================
What's the weather where I live?
==================================[1m Ai Message [0m==================================
[{'text': 'Let me search for current weather information in San Francisco.', 'type': 'text'}, {'id': 'toolu_011kSdheoJp8THURoLmeLtZo', 'input': {'query': 'current weather San Francisco CA'}, 'name': 'tavily_search', 'type': 'tool_use'}]
Tool Calls:
tavily_search (toolu_011kSdheoJp8THURoLmeLtZo)
Call ID: toolu_011kSdheoJp8THURoLmeLtZo
Args:
query: current weather San Francisco CA
=================================[1m Tool Message [0m=================================
Name: tavily_search
{"query": "current weather San Francisco CA", "follow_up_questions": null, "answer": null, "images": [], "results": [{"title": "Weather in San Francisco, CA", "url": "https://www.weatherapi.com/", "content": "{'location': {'name': 'San Francisco', 'region': 'California', 'country': 'United States of America', 'lat': 37.775, 'lon': -122.4183, 'tz_id': 'America/Los_Angeles', 'localtime_epoch': 1750168606, 'localtime': '2025-06-17 06:56'}, 'current': {'last_updated_epoch': 1750167900, 'last_updated': '2025-06-17 06:45', 'temp_c': 11.7, 'temp_f': 53.1, 'is_day': 1, 'condition': {'text': 'Fog', 'icon': '//cdn.weatherapi.com/weather/64x64/day/248.png', 'code': 1135}, 'wind_mph': 4.0, 'wind_kph': 6.5, 'wind_degree': 215, 'wind_dir': 'SW', 'pressure_mb': 1017.0, 'pressure_in': 30.02, 'precip_mm': 0.0, 'precip_in': 0.0, 'humidity': 86, 'cloud': 0, 'feelslike_c': 11.3, 'feelslike_f': 52.4, 'windchill_c': 8.7, 'windchill_f': 47.7, 'heatindex_c': 9.8, 'heatindex_f': 49.7, 'dewpoint_c': 9.6, 'dewpoint_f': 49.2, 'vis_km': 16.0, 'vis_miles': 9.0, 'uv': 0.0, 'gust_mph': 6.3, 'gust_kph': 10.2}}", "score": 0.944705, "raw_content": null}, {"title": "Weather in San Francisco in June 2025", "url": "https://world-weather.info/forecast/usa/san_francisco/june-2025/", "content": "Detailed ⚡ San Francisco Weather Forecast for June 2025 - day/night 🌡️ temperatures, precipitations - World-Weather.info. Add the current city. Search. Weather; Archive; Weather Widget °F. World; United States; California; Weather in San Francisco; ... 17 +64° +54° 18 +61° +54° 19", "score": 0.86441374, "raw_content": null}], "response_time": 2.34}
==================================[1m Ai Message [0m==================================
Based on the search results, here's the current weather in San Francisco:
- Temperature: 53.1°F (11.7°C)
- Condition: Foggy
- Wind: 4.0 mph from the Southwest
- Humidity: 86%
- Visibility: 9 miles
This is quite typical weather for San Francisco, with the characteristic fog that the city is known for. Would you like to know anything else about the weather or San Francisco in general?
说这里其实已经把 LangChain 的六大核心组件——模型、提示词、链、索引、记忆、智能体——都梳理清楚。可以说,它们让大语言模型真正地和实际业务场景紧密结合。每一个组件,都是创新和实用性并存的产物。开发者若能灵活运用,必定能构建出智能且富有温度的多维度应用。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?
别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明:AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。


四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









