



RAGFlow 是一个基于对文档深入理解的开源 RAG(检索增强生成)引擎。它的作用是可以让用户创建自有知识库,根据设定的参数对知识库中的文件进行切块处理,用户向大模型提问时,RAGFlow 先查找自有知识库中的切块内容,接着把查找到的知识库数据输入到对话大模型中再生成答案输出。它能凭借引用知识库中各种复杂格式的数据为后盾,为用户提供真实可信、少幻觉的答案。
RAGFlow 的技术原理涵盖了文档理解、检索增强、生成模型、注意力机制等,特别强调了深度文档理解技术,能够从复杂格式的非结构化数据中提取关键信息。下面我手把手教各位同学如何在 Linux 系统中搭建 RAGFlow。
Ollama 是一个开源项目,专注于帮助用户本地化运行大型语言模型(LLMs)。它提供了一个简单易用的框架,让开发者和个人用户能够在自己的设备上部署和运行 LLMs,而无需依赖云服务或外部 API。这对于需要数据隐私、离线使用或自定义模型调整的场景非常有用。
点击下方名片关注公众号**,第一时间获取AI案例分享!!!!!!**
一、安装 Docker Desktop(Windows 版)
- 下载安装包
-
访问 Docker Desktop for Windows 官方下载页(https://www.docker.com/),下载并运行安装程序。
-
安装时勾选 Use WSL 2 instead of Hyper-V(推荐,需提前启用 WSL 2)。

- 启用 WSL 2(若未启用)
打开 PowerShell(以管理员身份运行),执行:TypeScript
wsl --set-default-version 2
根据提示安装 Linux 内核更新包(下载地址)。
window选择开启Hyper-V
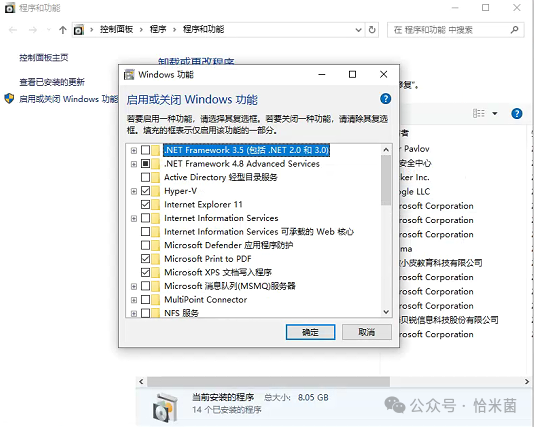
- 验证安装
启动 Docker Desktop,确保任务栏图标显示运行状态。打开命令提示符,输入 docker --version,显示版本号(≥24.0.0)即成功。
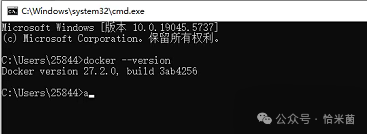
二、安装 Ollama(本地大模型运行工具)
- 下载 Windows 安装包
- 从 Ollama Releases 下载 ollama_windows_amd64.msi 安装包,双击安装。(https://ollama.com/)
- 部署 DeepSeek 模型(示例)
ollama run deepseek-r1
三、下载向量嵌入模型(用于文本向量化)
-
下载中文优化模型 bge-m3:
ollama pull bge-m3
四、用 Docker 部署 RagFlow
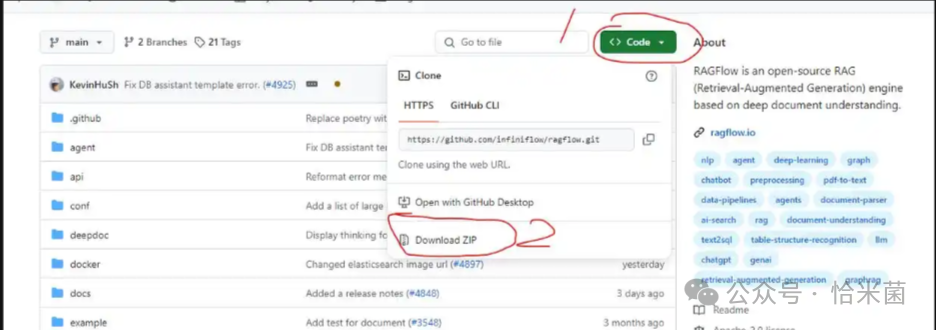
- 克隆 RagFlow 仓库
-
打开 Git Bash for Windows(需提前安装 Git),执行:
git clone https://github.com/infiniflow/ragflow.git也可以选择直接下载
- 启动 RagFlow 服务
-
编辑 .env 文件(用记事本打开),确保镜像版本正确(默认 ragflow_image=infiniflow/ragflow:v0.17.0-slim)。
-
启动服务:
docker compose -f docker-compose.yml up -d
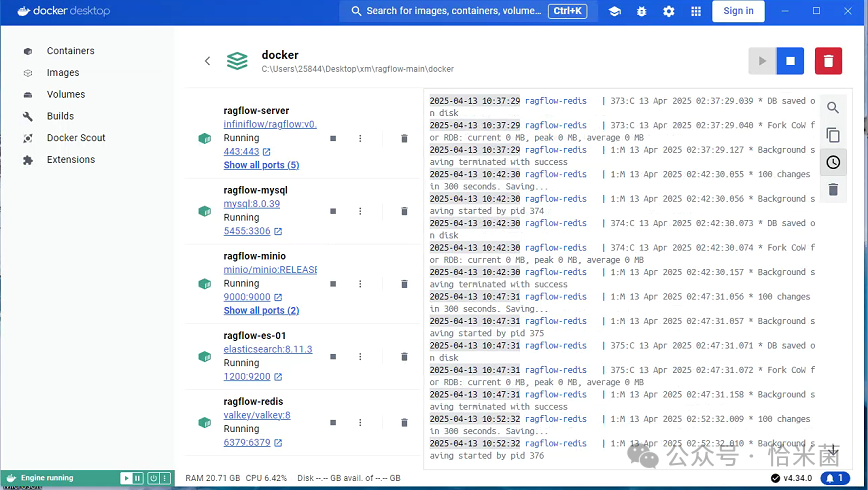
- 检查服务状态
-
打开命令提示符,输入:
docker logs -f ragflow-server出现 * running on all addresses (0.0.0.0) 表示启动成功。
-
访问 http://localhost(或 Docker 分配的 IP,端口可以选择默认的),进入 RagFlow 登录页。
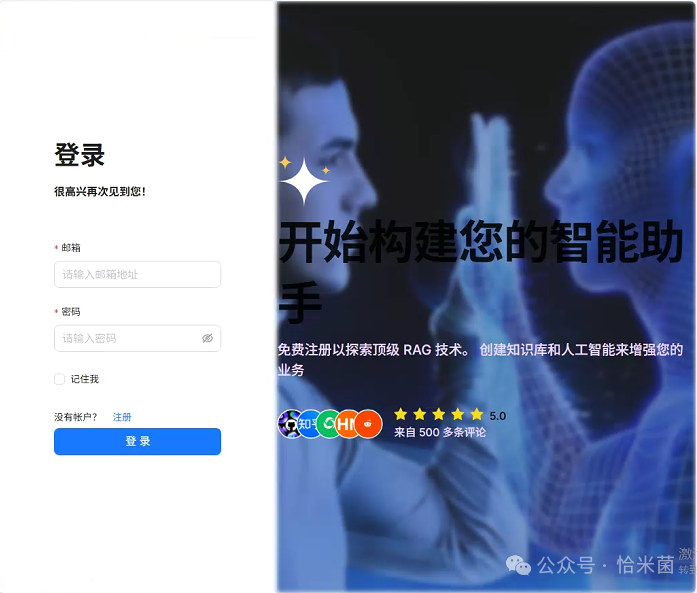
五、配置 RagFlow 连接本地 Ollama
添加模型提供商
- 登录后,进入 模型提供商 → 添加模型
-
模型名称:填写 deepseek-r1(与 Ollama 部署的模型一致)
-
端点:输入 http://localhost:11434(Ollama 默认端口)
-
类型:选择 chat
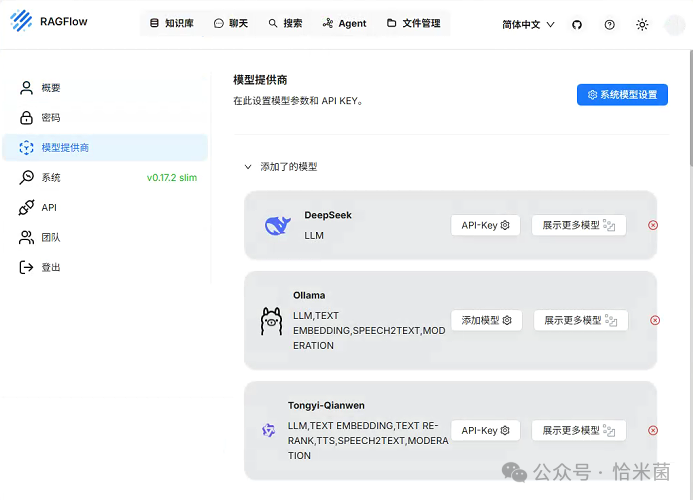
六、创建知识库并导入文件
- 创建知识库
-
点击 创建知识库,输入名称(如 my-knowledge)。
- 上传并解析文件
-
支持格式:PDF、DOCX、TXT、CSV 等。
-
操作步骤:
-
上传文件 → 选择分块模板(如 PDF 分块)。
-
Embedding 模型:选择ollama下载的bge-m3(需指定模型路径)。
-
点击 开始解析,等待进度条完成(大文件可能需要几分钟)。
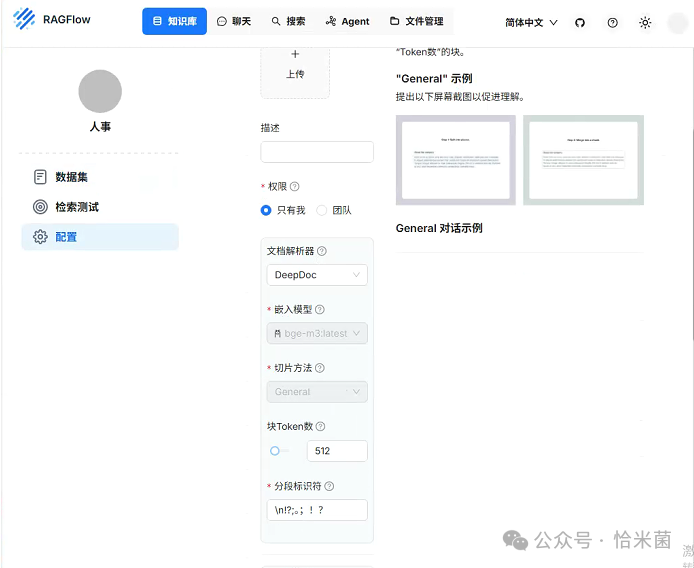
七、开始 AI 聊天
- 创建聊天助手
-
进入 Chat 页面 → Create an assistant:
-
名称:自定义(如 My Assistant)
-
知识库:选择已创建的知识库
-
模型:选择已添加的 deepseek-r1

- 开始对话
-
在输入框提问,例如:“知识库中的 PDF 文档提到了哪些技术要点?”
-
结果会显示引用来源(Show Quote 默认开启),确保答案可追溯。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 9552
9552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









