



最近需要本地部署FastGPT进行调研,借机整理下安装步骤。
本文适合场景:在Windows环境快速部署FastGPT,特别是需要配置上语音识别ASR模型(支持语音输入)、常见大语言模型、语音合成TTS模型(支持语音输出)。
主要步骤:
- Windows上安装Linux子系统WSL,原因是FastGPT需要使用docker方式进行安装,WSL让你在Windows上的Linux子系统直接操作docker,进行各种镜像安装。
- Windows上安装Docker Desktop。
- Linux子系统上使用docker安装FastGPT,如果你有Linux系统,忽略前面1、2步直接从这步开始。
- FastGPT上配置各种模型。
一、安装WSL
Windows版本要求:Windows 10 版本 2004 及更高版本(内部版本 19041 及更高版本)或 Windows 11。
右键“以管理员身份运行” 打开PowerShell ,输入如下命令,然后重启电脑:
wsl --install

该命令将在Windows系统上默认安装Ubuntu操作系统。当然可以安装其他版本的Linux,例如Debian,或者Windows版本太旧需要在安装前执行额外命令,这些情况不是本文重点,详细按照文档请参见资料[1]。
安装后,在运行中搜索Ubuntu,可看到已经安装好,打开可直接进入了Ubuntu系统的命令行。
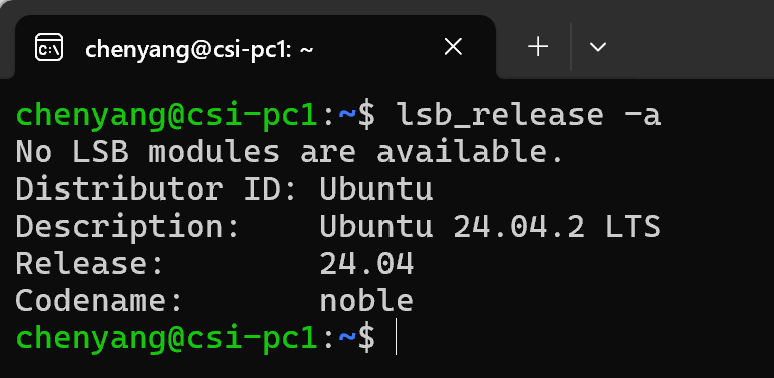
神奇的是,能直接在Windows资源管理器中直接操作Linux的文件目录,在Windows命令窗口中执行Linux命令,也可在Linux中执行Windows命令,例如用notepad.exe打开文件。
到此,Linux系统已就绪,本文假设你有基本的Linux操作经验。
二、在Windows上安装Docker Desktop
FastGPT需要使用docker进行安装,在Windows上安装Docker Desktop后,直接能在WSL Linux环境中执行docker各种操作,结果在Windows和Linux中都能看到。安装过程就是一个普通的Windows软件安装。
- 从https://www.docker.com/下载Windows版安装包;
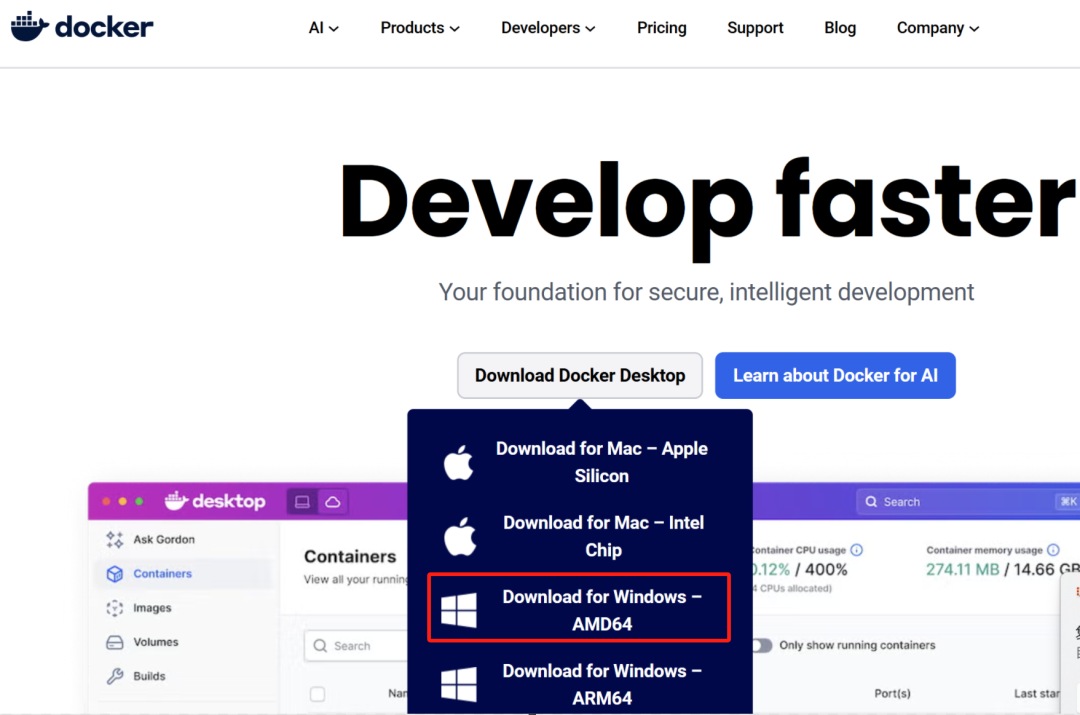
-
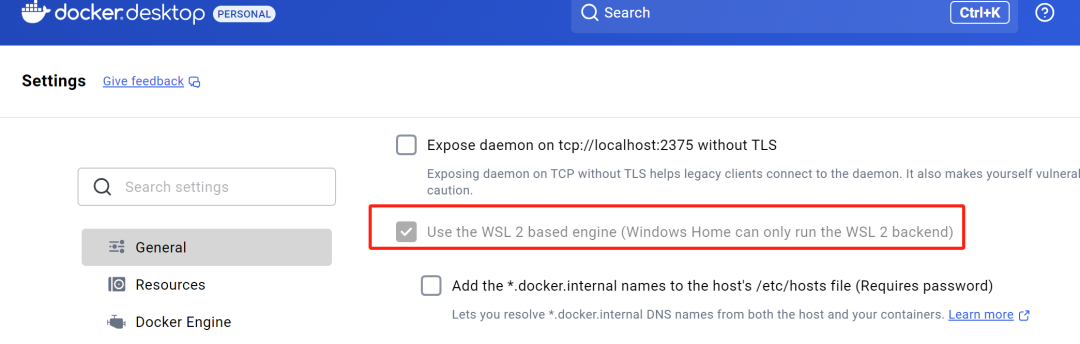
执行安装,在安装过程中,确保勾选 “Enable the WSL 2 based engine”。
-
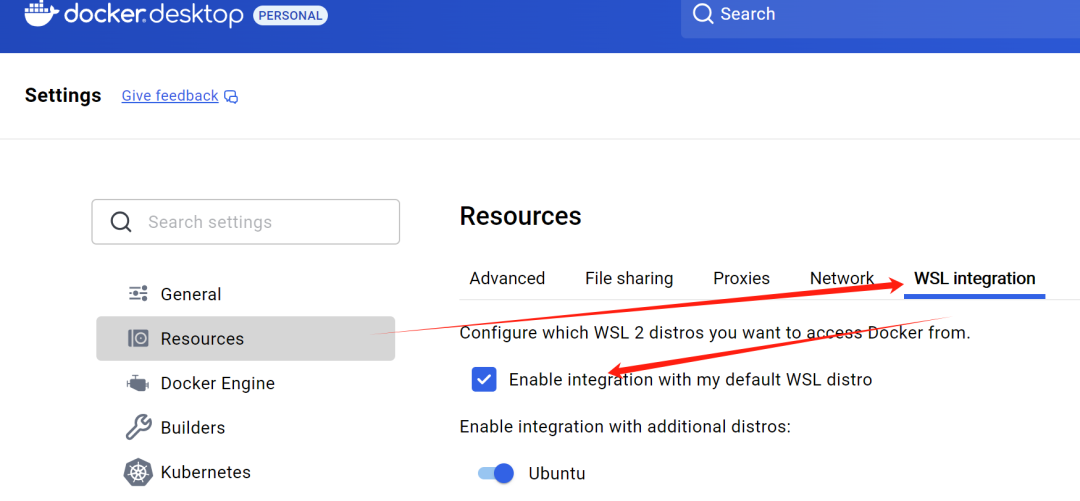
安装后,打开Docker Desktop,确保下面两个选项是勾选了的。
进入Linux命令行中,执行"docker --version"能看到具体的版本信息,表示已经安装成功。
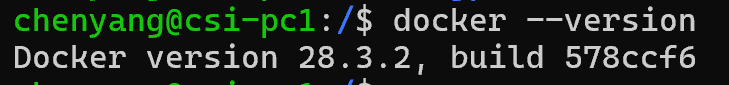
三、安装FastGPT
以下操作均在Linux命令行中执行。
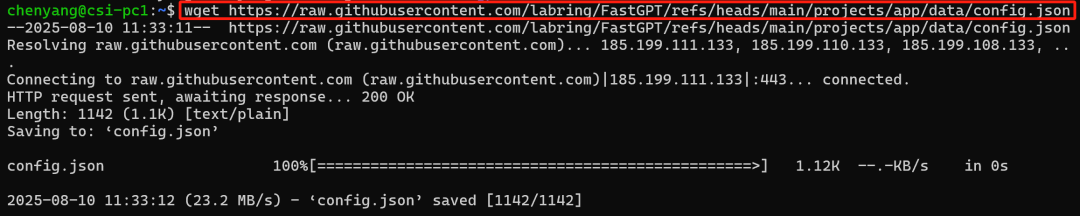
- 下载配置文件config.json
使用wget从github下载:
wget https://raw.githubusercontent.com/labring/FastGPT/refs/heads/main/projects/app/data/config.json
- 下载配置文件docker-compose.yml
针对使用不同的知识库向量数据库,下载不同的文件,PgVector适合知识库索引量在 5000 万以下,Milvus适合亿级以上的索引量(知识数据条数)。
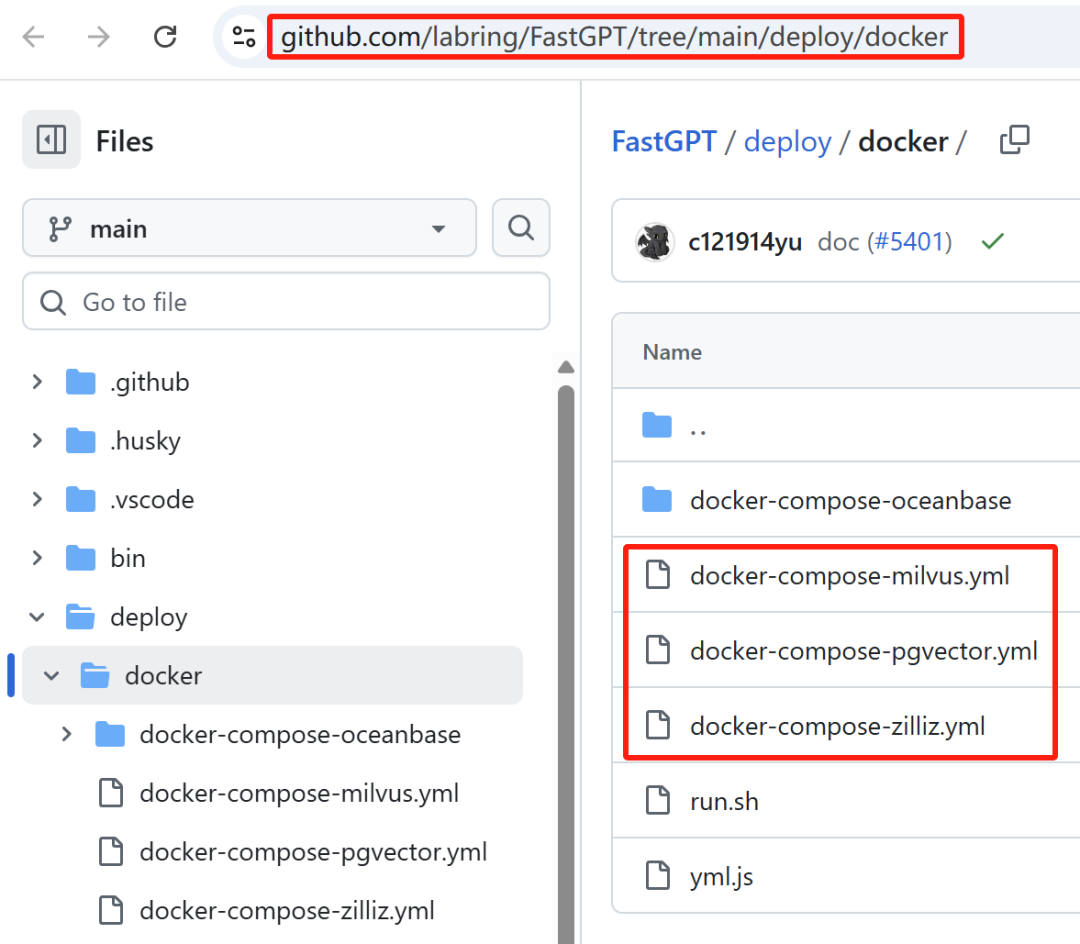
此处我们以使用PgVector为例,下载保存文件名为docker-compose.yml,命令如下:
wget https://github.com/labring/FastGPT/blob/main/deploy/docker/docker-compose-pgvector.yml -O docker-compose.yml
- 配置docker下载的镜像
为了能顺利从从国外下载FastGPT及其依赖的镜像,需要配置国内的镜像源,创建/etc/docker/daemon.json,并加入如下内容(需要有root权限或者sudo权限):
{
“registry-mirrors” : [“https://docker.registry.cyou”,
“https://docker-cf.registry.cyou”,
“https://dockercf.jsdelivr.fyi”,
“https://docker.jsdelivr.fyi”,
“https://dockertest.jsdelivr.fyi”,
“https://mirror.aliyuncs.com”,
“https://dockerproxy.com”,
“https://mirror.baidubce.com”,
“https://docker.m.daocloud.io”,
“https://docker.nju.edu.cn”,
“https://docker.mirrors.sjtug.sjtu.edu.cn”,
“https://docker.mirrors.ustc.edu.cn”,
“https://mirror.iscas.ac.cn”,
“https://docker.rainbond.cc”,
“https://do.nark.eu.org”,
“https://dc.j8.work”,
“https://dockerproxy.com”,
“https://gst6rzl9.mirror.aliyuncs.com”,
“https://registry.docker-cn.com”,
“http://hub-mirror.c.163.com”,
“http://mirrors.ustc.edu.cn/”,
“https://mirrors.tuna.tsinghua.edu.cn/”,
“http://mirrors.sohu.com/”
],
“insecure-registries” : [
“registry.docker-cn.com”,
“docker.mirrors.ustc.edu.cn”
],
“debug”: true,
“experimental”: false
}
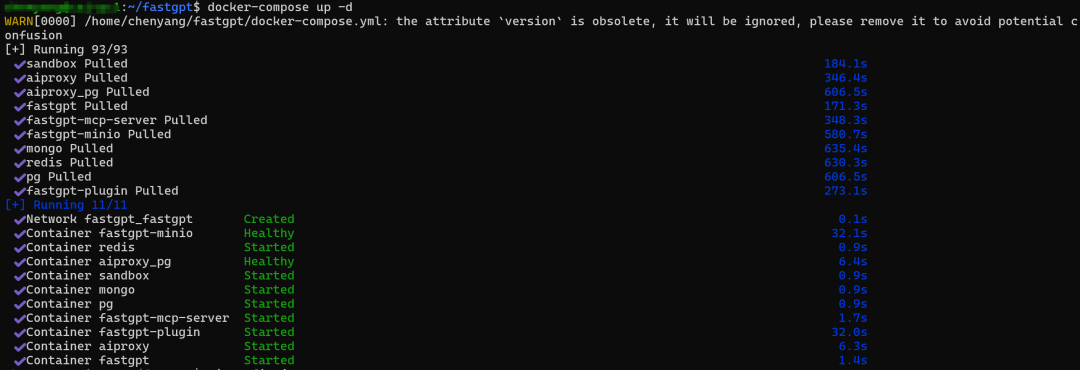
- 使用docker命令安装FastGPT
运行命令"docker-compose up -d"即可,docker根据docker-compose.yml内容自动下载FastGPT及其依赖的镜像进行安装,完成后如下:
这时到Docker Desktop界面中,能看到容器列表中已经有fastgpt:
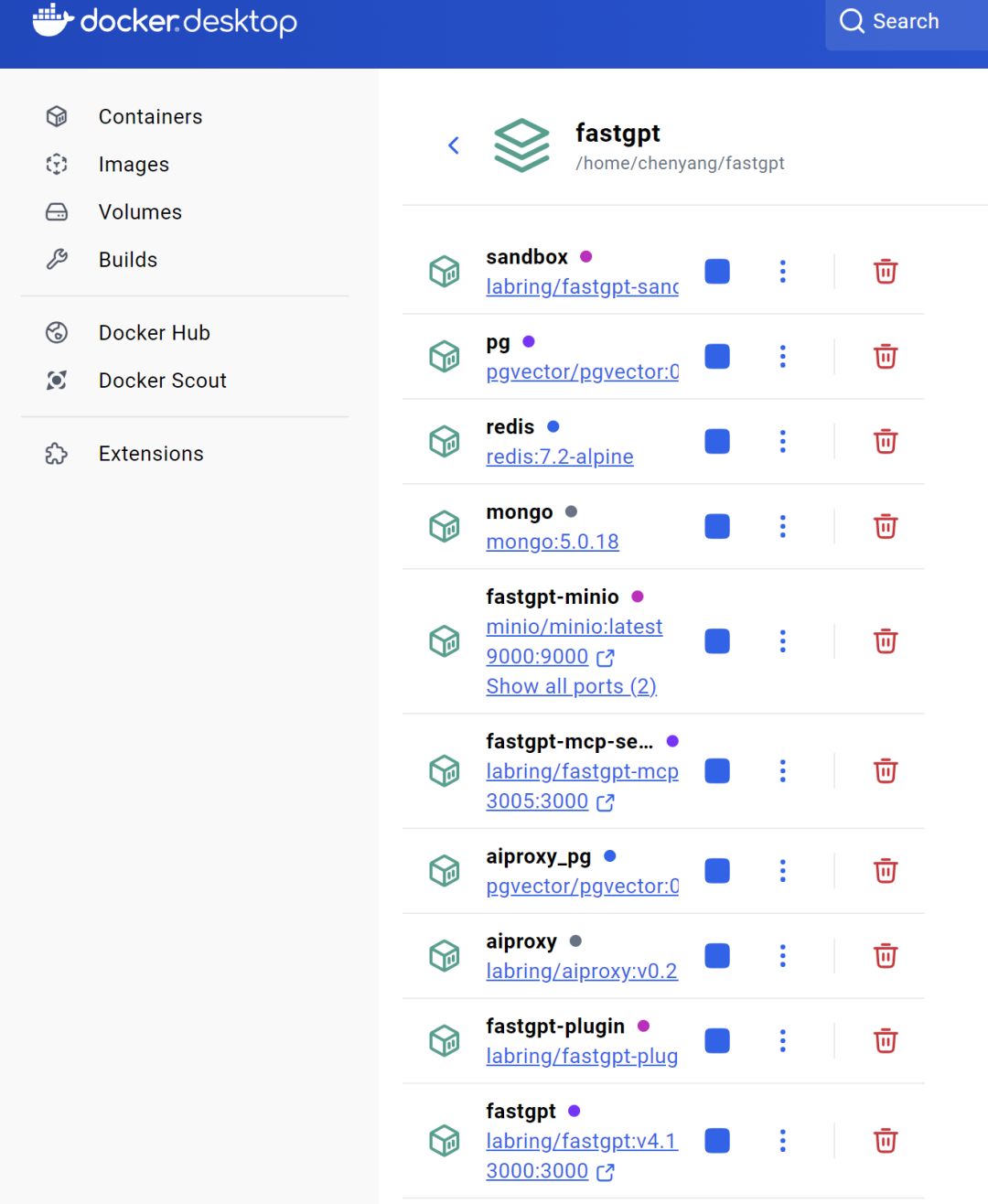
点进去能看到具体安装的镜像列表,例如上面说的PgVector向量数据库等。
- 访问FastGPT
此时,FastGPT默认已经启动,在Windows命令行通过ipconfig查看WSL的ip地址,通过端口3000即可访问,默认用户名root,密码1234。
四、模型配置
任何一个应用或者工作流都需要配置好模型,主要包括:
- 大语言模型
- Embedding模型(用于知识库)
- 重排模型(用于知识库)
- ASR语音识别模型(用于接受实时语音输入识别)
- TTS语音合成模型(用于把文字转为语音输出)
这些模型可以是本地部署的,也可是是远程的,只要通过API方式可被FastGPT调用即可。
如果使用过Dify,配置很简单,只要在管理后台选择对应的模型厂商,配置上调用的URL、API key即可。
FastGPT比Dify的配置略为复杂,支持两种方式:AI Proxy和One API。两者都是OpenAI 标准接口的管理 & 分发系统,可以通过标准的 OpenAI API 格式访问所有的大模型。
其中AI Proxy适合你已经有阿里百炼、硅基流动等厂商的用户账号的情况,阿里就是是Proxy代理角色,配置好账号后就能直接使用他们提供的一系列模型。若使用One API需要安装一个One API应用,在里面配置上各种模型,供FastGPT使用。
1、配置AI Proxy渠道
本文我使用AI Proxy方式,我已有了阿里百炼、硅基流动的API key,直接配置使用(关于如何申请API key就不说了)。
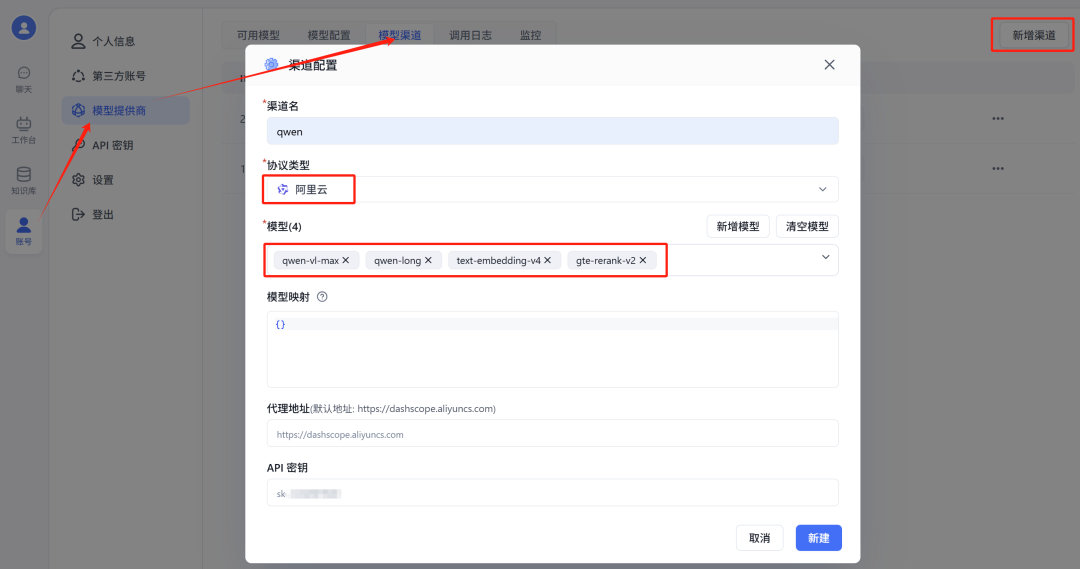
在模型渠道中新建渠道,协议类型选择阿里云,模型选择自己要使用的模型,例如大模型使用qwen-long,多模态模型使用qwen-vl-max,embedding模型使用text-embedding-v4等,代理地址默认就是对的,API密钥填上自己申请的API key。
ASR和TTS我使用硅基流动的模型,配置如下,模型选择SenseVoiceSmall、CosyVoice:
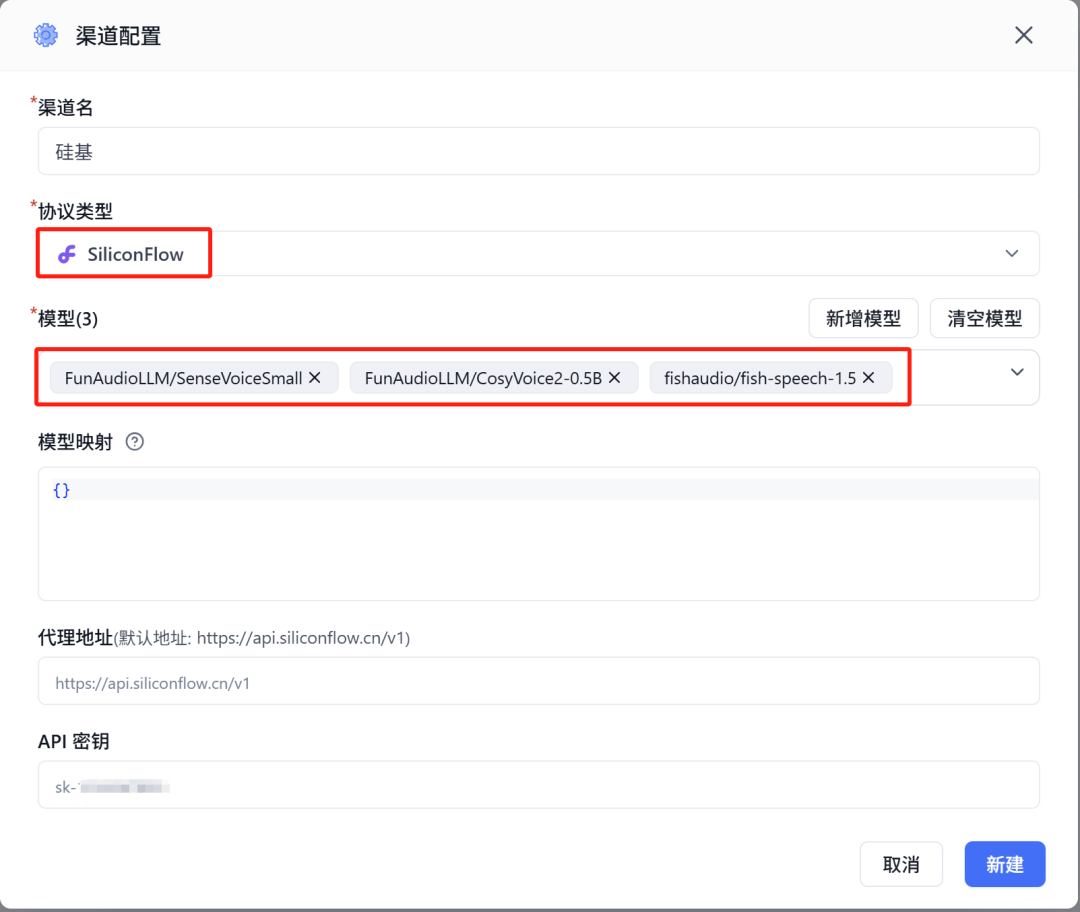
配置完渠道后长这样:
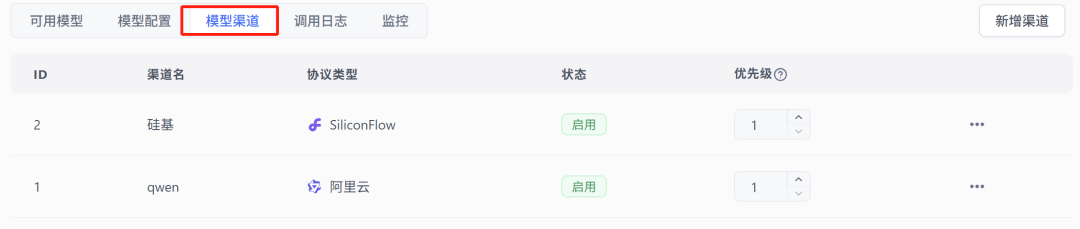
- 启用模型
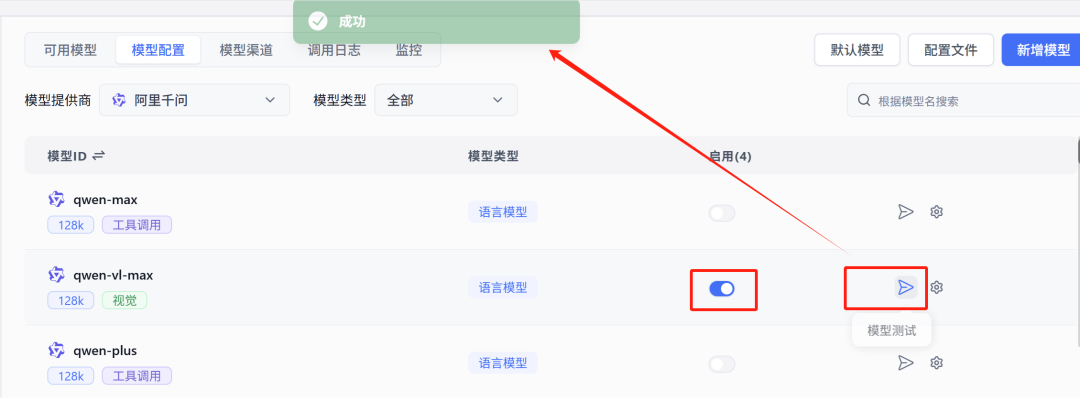
到模型配置中,通过模型提供商(阿里、硅基流动等)和模型类型(语言模型、语音识别等)过滤刚才选择了的模型,点击启用,可以点右边的“模型测试”就行测试,上面会显示测试结果。测试如果失败,可能是你的渠道配置、API key有问题。
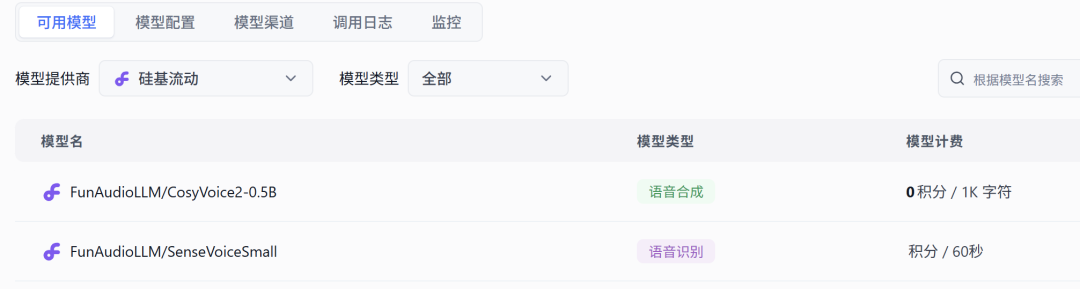
五、使用案例
一切已经就绪,可以创建应用和工作流了,下面是一个简单工作流的例子,FastGPT本身的使用方法不是本文的重点。
我们使用FastGPT已有的模版创建一个“生活达人”工作流,如果问菜谱相关的问题,使用大模型回答,否则不做解答,支持ASR语音实时输入和TTS语音输出。
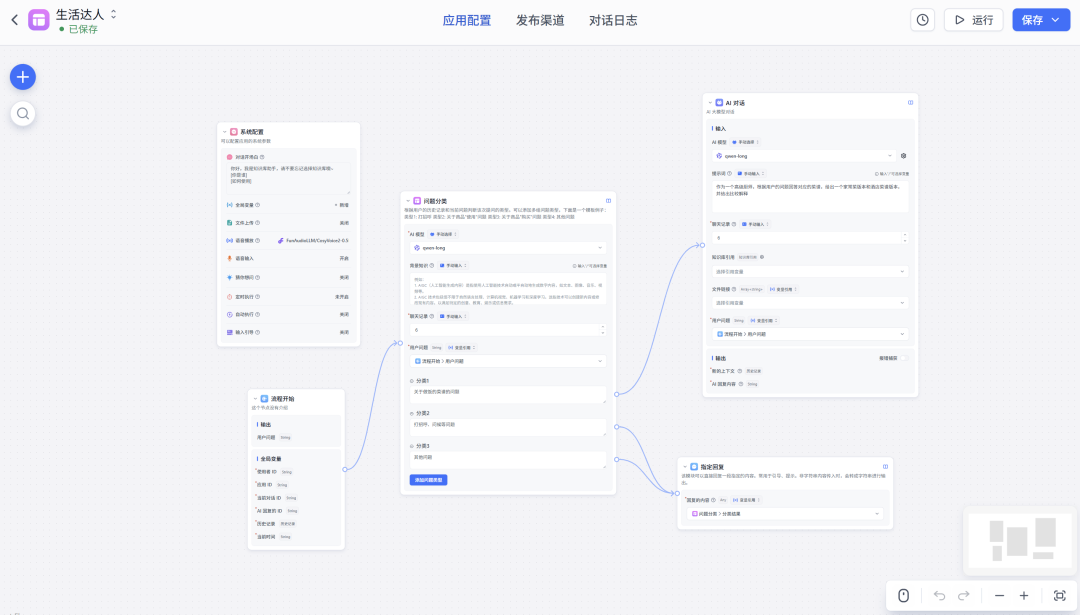
ASR和TTS设置如下:
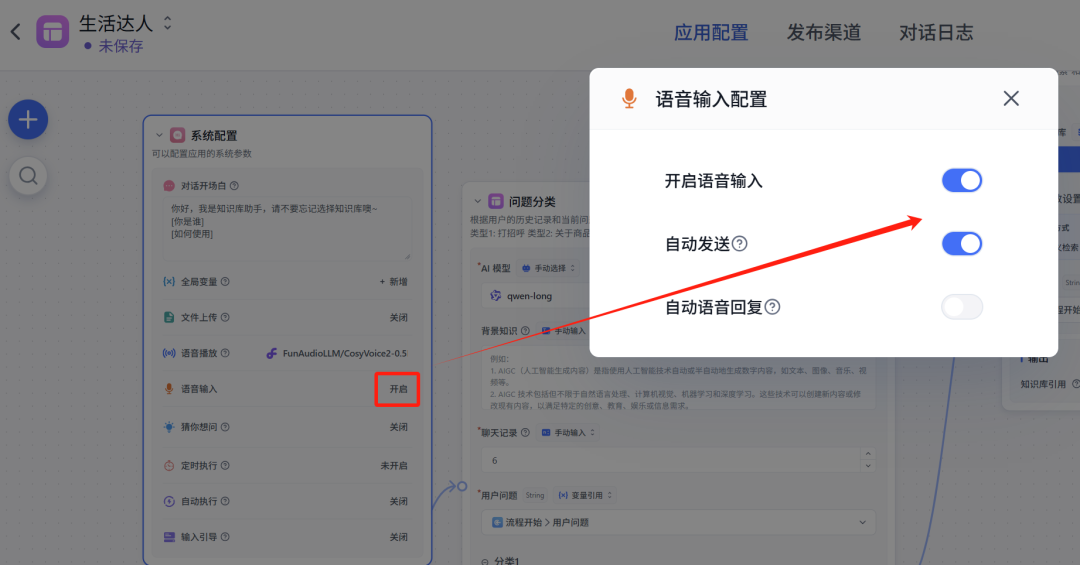
语音输入会直接使用上面已配置好的ASR模型。
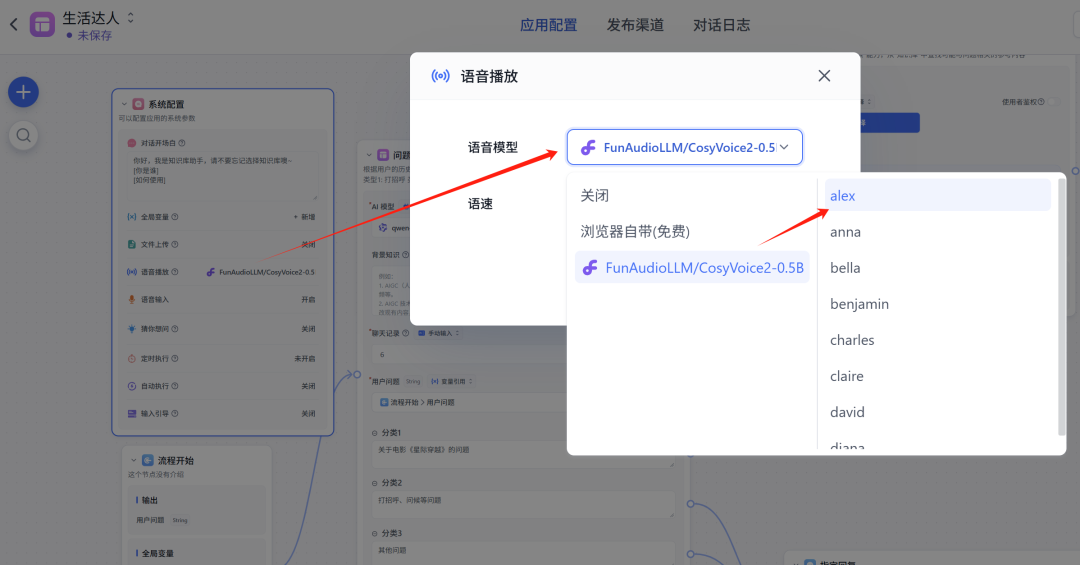
语音合成这里选择了上面配置的TTS模型,可选择不同的人物对应的音色。
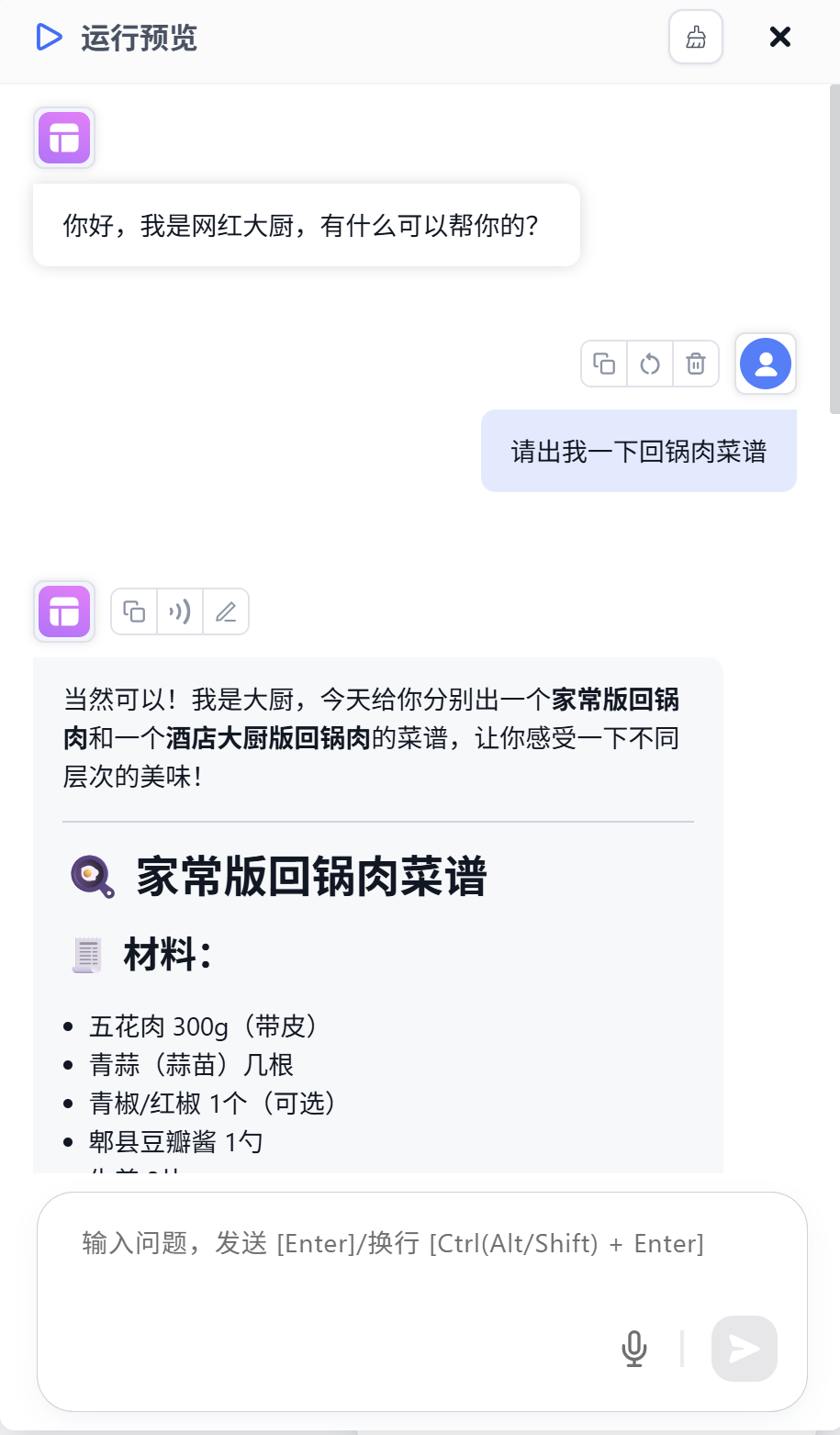
下面可以开始运行上述工作流,我们首先使用文字输入:
接下来使用语音输入,你很有可能会遇到“您的浏览器不支持语音输入”的错误,原因是浏览器出于安全考虑,默认需要用域名访问的URL才支持语音输入,而刚才我登录FastGPT使用的是ip。
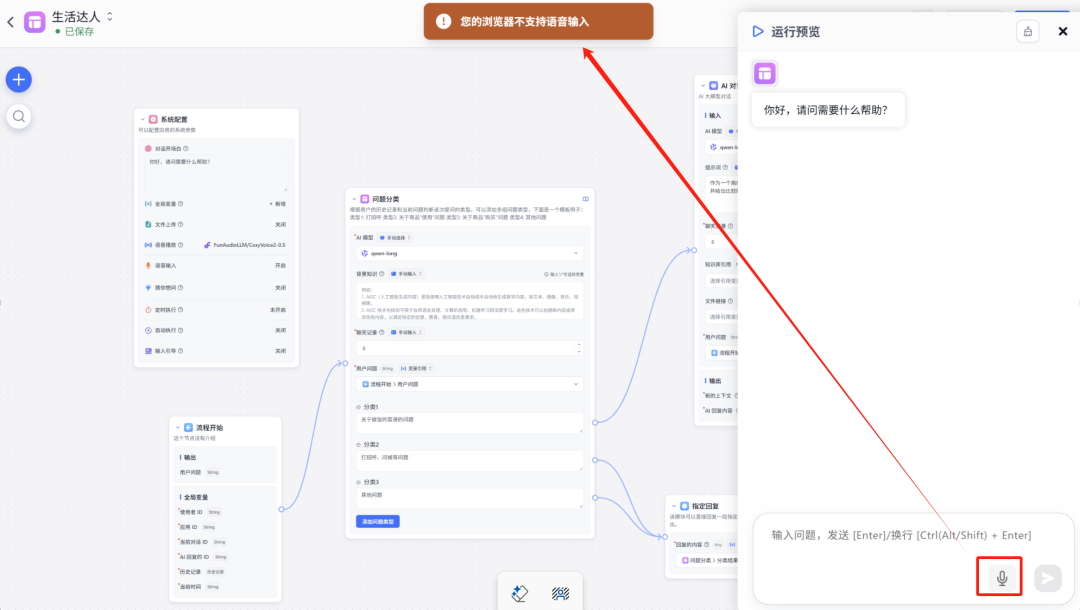
解决方法:上面我们使用的ip访问的FastGPT,如果能使用localhost就没这个问题,但Windows本身的ip和Linux子系统的ip不一致,如果用localhost,访问的是Windows而不是Linux,所以需要让两个系统的ip地址一致。具体方法是在Windows当前用户的目录创建个.wslconfig文件,加入内容如下:
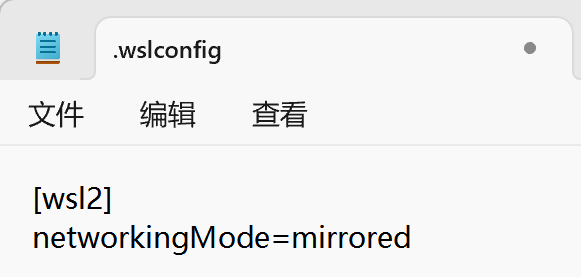
然后重启WSL,重启docker和FastGPT,通过http://localhost:3000访问就可以了。
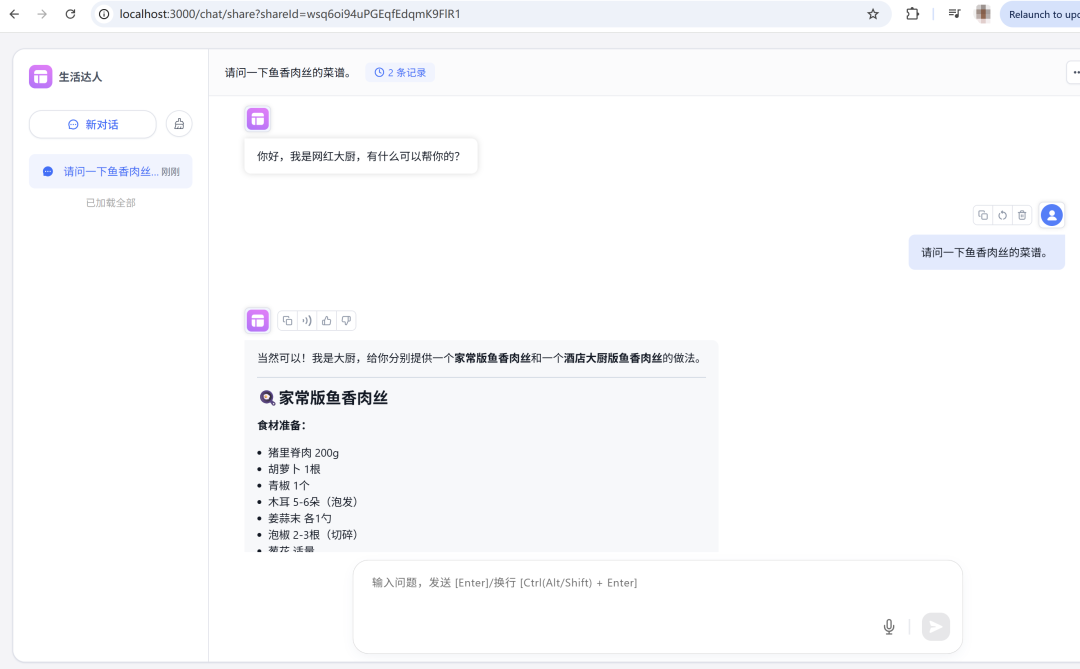
六、必须说的几件重要的事
-
在Windows上不管是玩FastGPT、Dify还是其他平台,确实只是玩玩而已,真正要在生产环境用,肯定还是要在Linux服务器上,用户数多的还要集群、负载均衡、各种备份。
-
FastGPT分为开源社区版和商业版、云服务版。社区版也只是玩玩而已,只要需要在公司多用户使用,就会涉及用户、权限管理,以及和其他系统的SSO单点登录等,就需要商业版才能满足了。
-
刚才用localhost解决浏览器支持ASR也是权宜之计,正常生产环境需要正式的域名并且配置上https等。
-
安装FastGPT的时候,docker-compose.yml中完全使用的默认值,包括数据库用户名和密码等,实际环境中需要改为安全的值。
参考资料:
[1]. WSL安装官方文档:https://learn.microsoft.com/zh-cn/windows/wsl/install
[2]. FastGPT官方文档:https://doc.fastgpt.io/docs/introduction
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 2540
2540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









